【51CTO.com快译】这年头几乎每个人都在这样那样抱怨性能。数据库管理员和程序员不断发现自己处于这种情形:服务器遇到了瓶颈,或者查询起来没完没了,这种情况并不少见。这种郁闷对我们所有人来说司空见惯了,解决方法不一。
最常见的一幕就是看一眼查询后,责怪程序员在查询方面没有做得更好。也许他们原本可以使用合适的索引或物化视图,或者干脆以一种更好的方法重写查询。而有时候,如果贵公司使用云服务,你可能要多启用几个节点。在其他情况下,如果服务器被太多慢腾腾的查询搞得不堪重负,你可能要为不同的查询设置不同的优先级,那样至少比较紧迫的查询(比如***执行官的查询)更快地完成。如果数据库不支持优先级队列,管理员甚至会取消你的查询,腾出一些资源,用于更紧迫的查询。
不管你遇到过上述哪种情况,可能熟悉这种痛苦的经历:不得不等待慢腾腾的查询,或者购买更多的云实例,或者购买更快速、更庞大的服务器。大多数人熟悉传统数据库调整和查询优化方法。这些方法有利也有弊。所以,我们在这里不会谈论那些方法。我们在本文中是要谈论更新颖的方法,它们不大为人所知,但在许多情况下确实可以有机会大大提升性能,并节省成本。
首先,不妨考虑这些场景:
场景1(探索性分析)——你是名分析员,要对数据进行交叉分析,寻找洞察力和模式,或者测试针对你的公司、客户或服务所作的不同假设。在这种情况下,你通常不知道自己究竟会看到什么。你运行查询,查看结果,然后决定是否需要运行不同的查询。换句话说,你执行一系列探索性即席查询,直至找到所需的结果。你运行的查询中只有一些会用来填充公司报表、填写表单,或者为客户生成图形。但每当你提交查询,可能要等几分钟才能得到答案,时间的长短要看数据大小及集群中其他并行查询的数量。等待过程中,你通常无所事事,无法决定下一个查询,因为这取决于你仍在等待执行完毕的前一个查询的输出结果!
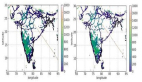
解决办法:等待过程中,你可以立即看到“几乎***”的答案。我这里所说的“几乎***”的答案是啥意思?不妨比较下面这两张图。
这些是同一款商业智能工具在运行从后端数据库装入数据的查询后的输出结果。由于使用全部10亿个数据点,右边这张图耗时71分钟才完成,而左边这张图只使用100万个数据点,只花了3秒钟就完成!当然,左边这张图相比右边的***版本有点模糊。但要想一想:这么做值不值得?不用等待71分钟,你立即可以获得几乎一样的答案,然后决定是否想再等71分钟获得完整的答案,还是不等了,去做其他事情!
这肯定不是一个新想法!实际上,所有的Web浏览器已经在这么做。下次你试图在浏览器上加载高分辨率图像时,注意Web浏览器如何先试图加载和显示一个模糊的图像,图像逐渐变得越来越清晰。但是将同样的原则运用于数据库和SQL查询处理却鲜为人知。
于是,现在你可能有几个问题:我们实际上如何获得这种提速?即便你的数据分布呈偏态,这一招管用吗?你仍看到异常数据?你需要使用特定的数据库来享用速度和准确性之间这种类型的取舍吗?我会在文章末尾回答所有这些问题,但我先说说另外几个场景,你可能发觉同样这个想法很有吸引力:立即见到准确性达到99.9%的结果,但速度要快200倍!
场景2(超载集群)——与如今的大多数数据库用户一样,你可能没有一个集群专门供自己使用。换句话说,你与你的团队共享集群,甚至共享其他报表和商业智能工具。这些工具对同一个共享的数据库资源池执行SQL查询。如果这些共享的集群超载,实际上就会发生下面三种情况中的一种:
A.全面沮丧。你什么都没做,任由每个人遭受一样的痛苦。换句话说,一旦数据库查询积压,CPU核心处于满载状态,没人能够足够快地完成查询。
B.局部沮丧。你做得比较巧妙,终止或暂停优先级较低的查询,让更紧迫的查询(比如你经理的那些查询)先完成。换句话说,你确保几个更重要的人满意,但是让其他人很生气!
C.如果这种情况频繁发生,可能要购买更多更大的服务器,或者迁移到云端,按需要启用更多的节点。当然,这种方案要花一定的费用,也不方便。另外,它也通常不是短期的解决办法。
大多数人没有认识到的一点是,还有第四种方法比前面两种方法更好,而且不像第三方方法,也不要你花钱。那么这种方法是什么呢?第四种方法如下:
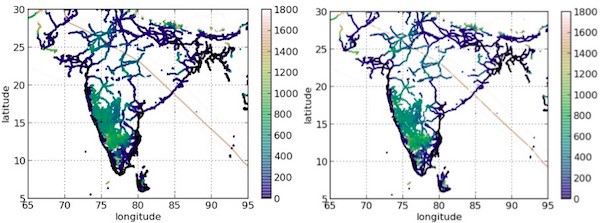
为低优先级查询返回99.9%准确的答案,为其余查询返回100%准确的答案!这之所以可行,是由于按照统计定律,你只要使用0.1%的数据和处理,通常就能获得99.9%准确的答案。这就是为什么牺牲0.1%的准确性意味着,实际上速度可以提升100倍至200倍。我知道没人想要凑合着使用99.9%的准确性,但是你需要考虑其他的选择:终止查询,被列入长长的等待名单,或者无所事事,等待查询完成。正如我在场景1下提到的那样,在许多情况下,你仍可以获得完整的答案,在等待完整答案的同时就使用99.9%准确的答案。我会在文章末尾回过来探讨“如何实现”的问题。不过眼下,记住:99.9%的准确性并不意味着你错失0.1%的输出结果。通常你仍看到一切,但是实际数字可能偏差0.1%,这意味着在大多数情况下,你甚至看不出区别所在,除非你确实眯着眼在打量。比较这两个图:
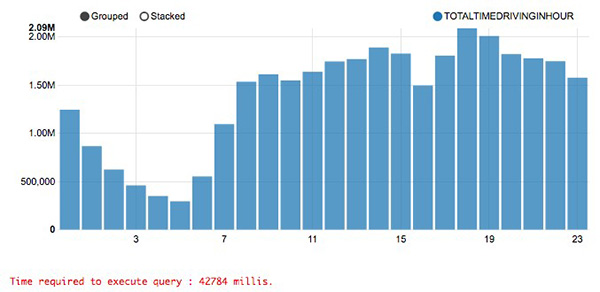
这些是使用著名的纽约市出租车数据集,询问打车到闹市区所用总时间的查询输出。
你能区别哪个是100%准确的答案,哪个是99.9%准确的答案吗?在大多数人看来,这两个一样。但是上面那个查询只花了1.7秒,而下面这个查询却花了42.7秒。这意味着,若牺牲0.1%的准确性,你的CPU时间可以节省25倍!不妨谈论***一种场景,然后我会告诉你“如何实现”这部分。
场景3(机器学习和数据科学)——如果你是机器学习专家或数据科学家,会常常发现要训练统计模型、调整参数,或者做一些特征选择和工程。这方面最常让人沮丧的问题之一是,你需要尝试大量的参数或特性,而训练机器学习模型要花很长时间。集群不断忙于训练和测试不同的模型,这就限制了数据科学家可以试用的一组不同模型和参数,或者至少减慢了这个过程。
在许多应用中,你不需要完全准确的答案,就能做出相当合理的决策。A/B测试、根源分析、特征选择、可视化、噪声数据或值缺失的数据库都属于这种情形。只有你是计费部门的人,才不想要这么做!
我可能会写另一篇文章来介绍如何加快参数调整或特征选择。
但是我们“如何”才能让查询加快200倍,但又只牺牲一点极小的准确性?
答案在于一种名为近似查询处理(简称AQP)的技术。有不同的方法来实现AQP,但是最简单的办法是使用表的随机样本。结果是,如果你的数据呈偏态,你不想使用随机样本,因为这会错失可能存在于原始表中的大多数异常数据和罕见项。所以,实际上更常见的是一种名为“分层样本”的样本。分层样本是什么?不妨看看下面这张图:
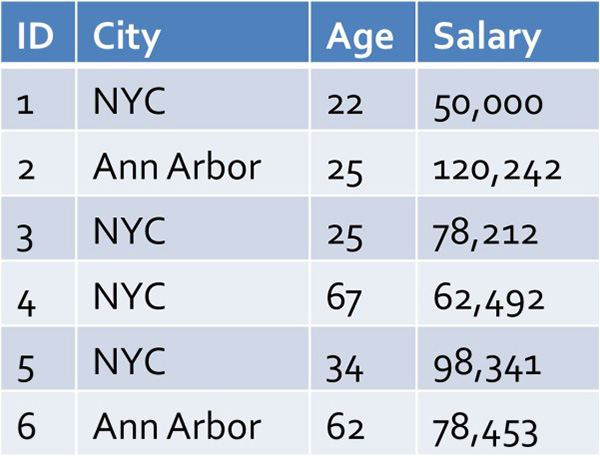
假设你想对这个表运行下列查询:
SELECT avg(salary) FROM table WHERE city = ‘Ann Arbor’
当然你可以运行这个查询,但是如果这个表有数亿行,或者它跨多个机器来分区,可能要好几分钟才能完成。相反,你可以决定只对表的随机(即统一)样本运行查询,比如说:
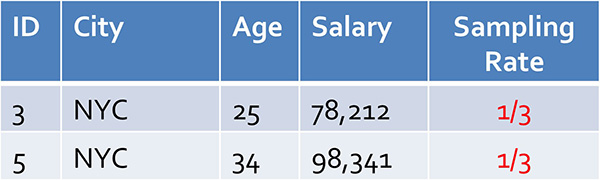
正如你所见,由于Ann Arbor元组相比原始表中的NYC元组很罕见,你很可能在样本表中很少看到Ann Arbor或根本就看不到。相反,分层样本会先根据City对表进行分层(即分区),然后随机采样显示每个城市的行:
ID City Age Salary Sampling Rate
3 NYC 67 62,492 1/4
***nn Arbor 25 120,242 1/2
结果发现,不用深入分析统计数据,诸如此类的分层样本会确保:通过处理一小部分的原始元组,你就能获得非常高的准确性。
现在,下一个问题是如何创建这些样本?又如何衡量准确性?有自动方法可以这么做。市面上有几款产品,可以用来隐藏这种复杂性,那样你只要摁一下按钮,它们就会帮你从头搞到尾,以极快地速度返回答案,有一些甚至为你提供旋钮,只要转动旋钮,就可以决定想要多高的准确性以换取多快的提速。
BlinkDB / G-OLA
虽然外面有许多AQP方案,但是BlinkDB可能是***个成为开源项目的分布式(大规模并行)AQP引擎。本着完全披露的精神,我参与这个项目,所以我在这里可能有偏见,因为我确实很喜欢BlinkDB的方法,我认为它确实影响了后面介绍的许多学术方案和行业方案。Databricks(商业化Apache Spark的公司)在继续开展BlinkDB方面的工作。Databricks不久前宣布了BlinkDB的扩展方案,将逐步完善其查询答案,直至用户满意为止。这个扩展方案名为G-OLA。G-OLA之前从未公开发布过,BlinkDB有好长时间没有更新了。
SnappyData
SnappyData是一种开源内存混合分析平台,它在一个引擎中提供了OLTP、OLAP和数据流(Streaming)。数据库引擎本身是通过扩展Apache Spark而构建的(因而它与Spark全面兼容)。内存核心还通过精选的分层采样及其他概率结构提供了AQP。查询语法类似BlinkDB,这让用户可以指定所需的准确性。这意味着你可以把准确性当作可调节拨盘。比如,如果你想要准确答案(这是默认行为),可以要求100%的准确性;但如果想要快速的答案,也可以在一秒左右的时间内获得99%准确性的答案。在我看来,SnappyData的一大优点是,它使用精选的分层样本。这意味着,你可以在几秒内运行分析查询,即便是在查询数TB的数据,在笔记本电脑上运行,或者在共享集群中运行(有另外众多并行查询)。它还内置了支持数据流的功能,这让你可以构建样本,并且实时更新样本,以响应入站数据流。
SnappyData的另一个出色功能是,它随带许多高级用户接口,这意味着你不需要精通数据统计,就可以使用其AQP功能。比如,现在它有一种免费的云服务iSight,它使用Apache Zeppelin作为前端,以便在后台运行完整查询的同时,立即显示查询响应。
Presto
Facebook的Presto有一项试验功能,可以近似处理基本的聚集查询。我其实不知道***版本是不是拥有这项功能,但缺点是,你不得不使用不同的语法(即修改SQL查询),那样才能调用那些近似聚集功能。如果你有现有的商业智能工具或应用软件并不使用这一种特别的语法,那很麻烦,因为它们无法得益于潜在的速度提升,除非对它们重写,以便可以使用这种新的语法。
InfoBright
InfoBright提供了近似查询功能(名为IAQ)。不像其他系统,IAQ根本就不使用样本。遗憾的是,近似功能如何工作,它们提供什么样的准确性保证方面公布的细节不多,不过在看了其博客后,我认为他们在构建底层数据的模型,并使用那些模型来回答查询,而不是使用样本。我也不是很了解IAQ,因为它不是开源,我在其官方网站上也找不到许多详细信息,不过听起来它像是一种值得关注的方法。
ABS
分析引导系统(ABS)是另一种近似查询引擎,它使用样本和高效的统计方法,以估计误差。***代码有点过时了,只适用于Apache Hive的早期版本。这个项目目前不活跃。
Verdict
Verdict是一种中间件,介于你的应用程序或商业智能工具与后端SQL数据库之间。你只要对现有数据库执行与以前一样的查询,立即就能获得近似的答案。原则上,可以将Verdict与任何SQL数据库结合使用,这意味着你不会受制于任何特定的数据库管理系统(DBMS)。但目前,它只随带面向Spark SQL、Hive和Impala的驱动程序。优点在于,它是通用的,可以与任何SQL数据库兼容,而且是开源的;缺点是由于它是中间件,可能不如InfoBright或SnappyData等一些商用解决方案来得高效。
Oracle 12C
Oracle 12C推出了approximate count distinct和近似百分比功能。这些近似聚集提升了性能,计算时少占用内存。Oracle 12C还提供了物化视图支持,那样用户甚至可以预先计算近似聚集。虽然近似百分比和count distinct查询大有用处,实际上也很常见,但是并不广泛支持其他类型的查询。但是考虑到Oracle的庞大用户群,连这些有限的功能也会让许多用户从中得益。不过,据我所知,其他许多数据库厂商长期支持approximate count distinct查询(比如使用HyperLogLog算法)。
原文标题:How To Make Your Database 200x Faster Without Having To Pay More?,作者:Barzan Mozafari
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】