通过前面几篇文章的介绍,我们已经可以通过一系列命令,从不同维度获得操作系统当前的性能运行情况。 另外,借助类似Ganglia这样的开源产品,持续不断地实施性能数据采集和存储,我们基于时间序列的历史性能图形,就可以大致判读出计算集群的资源消耗情况和变化趋势。 但是,仅仅这些还是不够的,在很多情况下,我们希望能够知道:“慢,是为什么慢;快,又是为什么快”。 如果要回答这个问题,就必须引入另外一件神兵利器:动态追踪技术(Dynamic Tracing)。
鉴于这套兵器过于复杂(牛逼),属于专家级技能, advanced performance analysis and troubleshooting tool。据称掌握该技能需要耗费大约100小时以上,所以如果不是对于系统性能问题有***追求,以及变态般地技术狂热,建议绕过本文。
为了便于展开,今天先起个头,重点梳理下动态追踪技术的发展简史和目前的生态环境。更加具体详细的内容,会在后续的文章中陆续发表。
上月底,正当全国人民翘首以盼光棍节的时候,开源社区传来一则重要新闻: Linux 4.9-rc1发布,正式合并了一项重要特性:BPF追踪(Timed sampling)。
系统性能领域的国际导师Brendan Gregg,感动得都快哭了,当即在Twitter上表示这是一个重要的里程碑! 他随后又写了一篇长文《DTrace for Linux 2016》,以示庆祝。
As a long time DTrace user and expert, this is an exciting milestone! --Brendan Gregg
Linux 合并了BPF而已嘛,跟DTrace这个劳什子有什么关系呢?
DTrace 是动态追踪技术的鼻祖,源自 Solaris 操作系统,提供了高级性能分析和调试功能,它的源代码采用 CDDL 许可证,不兼容 Linux 内核使用的 GPLv2 许可证,无法直接移植。 当然,江湖上还有另外一种说法,Linux之所以一直没有原生支持DTrace,是因为Linus 觉得这玩意没什么必要。 Anyway,随着 BPF跟踪的***主要功能合并到 Linux 4.9-rc1,Linux 现在有了类似 DTrace 的高级分析和调试功能。
Linux 这次合并的BPF(The Berkeley Packet Filter ),和Ganglia一样,来自于加州大学伯克利分校(这所大学很有意思,以后还要反复提到)。 BPF,顾名思义,最早只是一个纯粹的封***滤器,大家比较熟知的netfilter,就是基于BPF实现的动态编译器。 后来在很多牛人的参与下,进行了扩展,得到了一个所谓的 eBPF,可以作为某种更加通用的内核虚拟机。 通过这种机制,我们其实可以在 Linux 中构建类似 DTrace 那种常驻内核的动态追踪虚拟机。
Linux 没有 DTrace(名字),但现在有了 DTrace(功能)
严格来说,DTrace这个词本身,已经并不是狭义上基于Solaris的那套工具了,而是代表的是后现代操作系统的一整套工具家族和方法论。
History
当时 Solaris 操作系统的几个工程师花了几天几夜去排查一个看似非常诡异的线上问题。 开始他们以为是很高级的问题,就特别卖力,结果折腾了几天,***发现其实是一个非常愚蠢的、某个不起眼的地方的配置问题。 自从那件事情之后,这些工程师就痛定思痛,创造了 DTrace 这样一个非常高级的调试工具,来帮助他们在未来的工作当中避免把过多精力花费在愚蠢问题上面。 毕竟大部分所谓的“诡异问题”其实都是低级问题,属于那种“调不出来很郁闷,调出来了更郁闷”的类型。---《漫谈动态追踪技术》
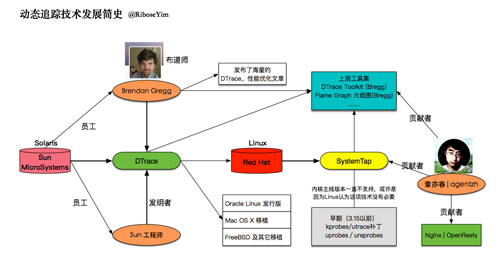
通观DTrace的演变过程,几乎相当于一部现代操作系统系统的发展史,细查起来,极其复杂。 但是有两个人非常值得关注,一个是***的布道师,一个是国内的代表人物, 初学者完全可以通过阅读他们的文章、代码,甚至微博/Twitter动态,了解动态追踪技术的实际应用情况。
Brendan Gregg
前SUN性能工程师,最早的DTrace用户,出版了包括《性能之巅》在内的一大批书籍,囊括了性能问题领域的技术、工具、方法论等方方面面。 是动态追踪技术当之无愧的***布道师。他维护的个人博客发布了大量的原创内容,并且持续保持着相当的活跃度。可以作为***手的学习资料。
Twitter: 个人网站:
章亦春 网名 agentzh。开源项目OpenResty创始人,编写了很多 Nginx 的第三方模块, Perl 开源模块,以及最近一些年写的很多 Lua 方面的库。 他发表过的《漫谈动态追踪技术》,是目前唯一由Brendan认证的中文资料,入门***。 另外,他本人也在目前的工作、开源项目运营中大量使用动态追踪技术。
Linux 追踪器选型
动态追踪技术最复杂的地方在于追踪器种类繁多,让人一时无从下手。 根据前人的一些经验总结,建议按照以下路径进行选择:
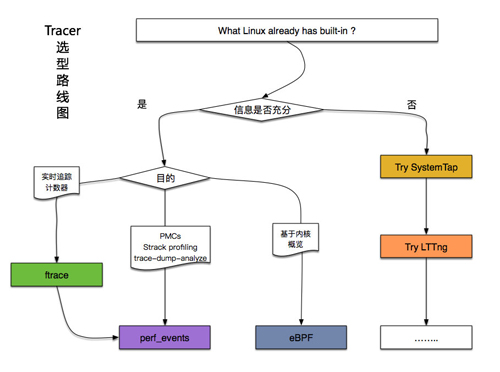
普通模式
适用于:开发者, 系统管理员, DevOps, SRE
CPU分析
perf_events的应用很广泛,配合Brendan Gregg老师研究的火焰图工具,可以分析程序在所有代码基的资源消耗,精确定位到函数级。 例如
进程追踪
- # ./execsnoop
- Tracing exec()s. Ctrl-C to end.
- PID PPID ARGS
- 22898 22004 man ls
- 22905 22898 preconv -e UTF-8
- 22908 22898 pager -s
- 22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
HARD模式
适用于:性能或内核工程师
Understanding all the Linux tracers to make a rational decision between them a huge undertaking.

- ftrace 内核hacker的***。已经包含在内核,能够支持 tracepoints, kprobes, and uprobes, 并提供一些能力: 事件追踪, 可选择过滤器和参数; 事件计数和时间采样,内核概览;基于函数的路径追踪。
- perf_events Linux用户的主要追踪器之一,它的源代码在内核中,通常在一个 linux-tools-common包。
- eBPF 基于内核的虚拟机
- SystemTap ***有力的追踪器。它可以做几乎所有的事情: 分析,打点, kprobes, uprobes (源子 SystemTap), USDT, 内核编程等。
- LTTng 事件收集器, 优于其它追踪器,支持多种事件类型,包括 USDT。
- ktap 一个很有前景的追踪器,基于lua内核虚拟机
- dtrace4linux 个人开发者业余产出 (Paul Fox) ,将 Sun DTrace迁移到 Linux。
- OL DTrace Oracle Linux DTrace,将 DTrace 迁移到Oracle Linux的实现。
- sysdig 一种新型追踪器, 能够基于类似tcpdump的命令操作 syscall events, 再用lua后处理。