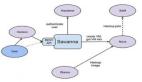
OpenStack Sahara是个命令行工具,通过简化流程,跟踪复杂的细节,使Hadoop和 Spark的安装、部署变得更加简单。
OpenStack是一种云操作系统,用于提供虚拟机,而OpenStack Sahara是一个附加组件,使管理员能够在这些虚拟机上部署Spark和Hadoop。换句话说,你可以将OpenStack Sahara作为一个中心点,构建Hadoop和Spark分布架构,做大数据分析。
Sahara本身提供的插件,可以用于不同供应商分配的Hadoop和Spark:
Vanilla: Apache Hadoop;
Ambari: Hortonworks Hadoop;
Spark: Apache Spark with Cloudera HDFS、Apache Spark with Cloudera Hadoop等
MapR:MapR plugin和 MapR File System等, Hadoop和Spark 准前端
Cloudera:Cloudera Hadoop分布式
从技术层面讲,不需要使用Hadoop来运行Spark,但是,由于Spark被分配存储在一个分布式架构中,因此,使用Hadoop来运行Spark,是最佳的选择。另外,Spark自身没有存储机制。
在架构中,Sahara 运行在OpenStack控制器节点上,而Hadoop集群运行在OpenStack计算节点上。
当然,还有其他的方法来部署Hadoop,比如说使用Docker containers,或者,还可以将Hadoop手动安装在虚拟或物理机器上。例如通过Ansible或者Puppet工具,使得这一切变得更加简单化。还有很多供应商以及供应商辅助工具可供选择,如Cloudera和MapR。另外,可以在不同云供应商的云中运行Hadoop。
使用OpenStack Sahara提供了一个中心点,可以部署并启动Hadoop,给每个VM分配一个Hadoop角色。作为一个开源的产品—一个不依赖于任何供应商的产品—能够获得OpenStack贡献者的支持,例如RedHat、Ubuntu、Suse、惠普、Workday、SAP、英特尔等等。
开始
可以在一台机器上安装OpenStack,但是,在做任何承诺之前,需要对其进行测试。有几种测试的方法。可以使用RHEL或CentOS的Packstack ,也叫RDO。或者可以使用DevStack Fedora、Ubuntu和CentOS。还可以使用Ubuntu 的Mirantis Fuel。
第一步是将虚拟机镜像上传到OpenStack Glance。可以使用Horizon仪表板或者Glance命令行。对于虚拟机,需要一个具有可用cloud-init的图像。Cloud-init便于部署到云,通过生成Secure Shell键,设置默认的定位和设置主机名。
使用Sahara
通过其他OpenStack组件,可以使用命令行界面,或者可以使用Horizon仪表板。仪表板显然更加容易。无论使用哪种方式,都需要安装Sahara。这是一个漫长的过程,OpenStack在其网站上提供了这样做的详尽说明。
部署Hadoop的基本步骤,首先是配置及部署VM,之后,才能确定每个VM提供哪种Hadoop角色。如下:
- Namenode: Hadoop分布式文件系统(HDFS)的存储细节,运行JobTracker
- Datanode: 运行工作的HDFS一部分
- 二级节点名称:作为名称节点备份,以防名称节点出现异常
- Oozie:工作流调度程序
- 资源管理器:使用Apache、Yarn或者Mesos 分配资源—内存和CPU
- 节点管理器:定位每个服务器的角色—节点—Hadoop系统中
工作历史服务器:密切关注MapReduce和其他工作的执行情况,并且,在必要时,进行重新安排。
继续使用OpenStack Sahara部署Hadoop,上传一个VM映像,例如带cloud-init的Ubuntu。接下来,使用Safari注册一个图像,将你使用的插件添加匹配的标签,例如Vanilla。向Horizon添加Sahara时,可以使用仪表板。VM模板、节点组模板具有相同的RAM和CPU特点,例如,m1.medium。最后,将节点组模板与集群模板相结合。
一旦完成这些步骤,在Horizon创建实例,设置主从Hadoop节点。然后,启动集群—实例。可以创建一个Hadoop job。可以是Spark、Pig、Java、MapReduce等等。然后,启动集群工作。最后,输出结果到Cinder或者其他存储。
Spark、Hadoop和Sahara
OpenStack Sahara并不是Hadoop或者Spark的增强版。相反,你可以把OpenStack Sahara看作一个图形或者命令行工具,使用OpenStack Sahara,建立一个分布式Hadoop或者Spark系统,变得更加简单。OpenStack Sahara不仅有助于安装这些系统;OpenStack Sahara还能跟踪服务器的服务功能。因此,通过屏幕,可以看到整个布局。
没有OpenStack Sahara的话,安装Spark或者Hadoop存在的最大困难是,你需要手动安装虚拟机。借助于OpenStack Sahara,可以跳过这一步,然后,你可以在上面安装Hadoop和 Spark。
OpenStack Sahara使你能够为每个服务器分配一个角色,因此,你要知道哪些服务器是用来存储数据的,哪些服务器是用来收集数据的,哪些服务器是用来协调所有活动的。一旦这一切已经敲定,当你需要规模扩展的时候,你可以重复这个过程。这是因为,你可以将你的想法另存为模板,就像OpenStack将不同的VM配置保存为模板。
OpenStack Sahara也能够帮助你跟踪其他复杂的细节,并且将这些复杂的细节纳入决策。例如,Hadoop背后的指导原则是,Hadoop使得每一块冗余数据分为三份。因此,把所有数据放置在同一台机器上、电源或者架子上,毫无意义。Sahara能起到很大的作用,因为Sahara本身就知道数据中心架配置,为了提高性能,可以将数据集中,为了避免冗余的话,也可以将数据分开。
综上所述,对那些已经使用OpenStack的用户来说,Sahara使得安装Hadoop和Spark变得更加容易。当然,你也可以使用Puppet、Ansible或者Docker,但是,这些都不是云的操作系统。