作者|面包包包包包包
修改|寒小阳 && 龙心尘
上一期我们一起探索了计算广告的基本概念和四种形式(点击查看《计算广告小窥(上)》),本期文章是我们为读者带来的【计算广告小窥】专题的第二个部分。
(上)(中)(下)全文目录
- 引言
- 广告=>互联网广告:“您好,了解一下”
- 互联网广告=>计算广告:指哪儿打哪儿!
- 计算广告四君子:谁在弄潮?
- 计算广告关键技术:这孙子怎么什么都知道?
- 广告系统架构:要啥自行车,这里有宝马。
- 手把手系列之教你搭建一个最小广告系统:mieSys
5. 计算广告关键技术:这孙子怎么什么都知道?
一句话解释关键技术:没声音,再好的戏也出不来。
广告作为一项商业活动,是需要资本来滋养的。作为整个产业链的金主,只有广告主花钱做广告,使资金流动起来,整个广告行业才能正常运转。所谓关键技术,就是那些能让广告主觉得“这钱花的值”,让媒体网站觉得“这钱挣的快”的技术。具体都有哪些呢?下面我们一一来表。
5.1 合约广告关键技术:受众定向
计算广告发展到合约广告阶段,媒体网站依靠受众定向技术给用户打标签,在实现了媒体网站广告位的时分复用的同时,还提高了广告主的投入产出比,极大的激发了广告主在互联网上做广告的积极性。因此,受众定向是合约广告中的关键技术。
我们知道,只要描述物体的维度足够高,那么世间万物都是独一无二的。在广告系统中,标签就是描述用户的维度。媒体网站为了精准的刻画用户,标签的种类和数量自然也不会少。为了更加直观地了解受众定向技术,我们从用户、上下文和广告三个方面讨论打标签的思路和一般方法。
- 用户标签:主要用性别、年龄、收入、地理位置、教育程度和用户行为等标签来刻画用户,从而回答“你是谁”的问题。
- 上下文标签:主要用网页的地域、主题和频道等标签来刻画用户当前所处的媒体网站环境,从而回答“你在看啥”的问题。
- 广告标签:主要用广告主、广告创意、广告计划和广告关键词等标签来刻画广告的相关内容,将广告内容与用户和上下文进行匹配后,从而回答“你该看啥”的问题。
5.1.1 用户标签关键技术
对一个用户来说,性别是不会轻易变的,但是用户的喜好和兴趣却是时刻都在变化的。根据标签属性的变化频率,我们这里私自将用户标签分为静态和动态两类。静态标签主要指年龄、性别、地理位置、收入和教育程度等这种不变或者很长时间之内都不变的标签,行话叫“人口属性”;动态标签则是指用户的浏览、搜索和点击等能够反映用户短时喜好和兴趣的行为标签,行话叫“行为定向(BT:Behaviroal Targeting)”。下面我们针对静态和动态这两类标签分别讨论。
一句话解释静态标签和动态标签的关系:价格围绕价值上下波动。
静态标签(人口属性)
在《计算广告小窥[上]》中,我们曾简要地提到过一种受众定向的方法:
通过对点击日志的分析,媒体网站发现点击过女性护肤品的用户又点击过媒体网站上其他女性品牌。在“女性用户对女性品牌可能更感兴趣”的合理假设下,判断这些用户的性别为女,男性用户同理。
现在我们可以更加清楚的认识到,上述媒体网站所打的标签是静态标签中的“性别”,使用的是基于规则的方法,即:满足了某种条件,就是某种人。这种基于规则的方法简单并且易于实现,但也存在着致命的缺点:基于规则的方法对数据非常敏感,若数据本身存在噪音(如误点击),那么标签的品质也将大打折扣。这可如何是好?简单的不行,那就来点复杂的嘛——用机器学习模型来实现(自带音效:当当当当,当当~~)。
假设我们已经知道一部分用户的真实性别,那么就可以用机器学习中有监督的二分类模型来预测用户性别。首先,我们需要对原始数据进行清洗,合理地处理缺失值和奇异值,并划分训练集、交叉验证集和测试集;其次,要在业务的指导下做特征工程,利用统计或模型的方法构造特征,并进行特征选择和特征组合;然后,我们要选择合适的模型(如SVM等),设置合适的评价标准并进行模型的训练;最后,通过模型调参和模型融合,获得性别预测模型。
动态标签(行为定向)
一句话解释行为定向:唐伯虎喜欢如花多一些,还是凤姐多一些?
“如果一定要比较一下,那唐伯虎是喜欢如花多一些,还是凤姐多一些?”这个看似荒谬的问题,正是行为定向要解决的。如果唐伯虎是异性恋,那他应该是喜欢凤姐多一些的,否则是如花。这也就告诉我们,在行为定向中,判断的标准至关重要。下面我们借助一个例子来分析该用户的动态标签究竟是什么。
有数据显示,某用户在过去的三个月时间中,点击广告的标签和次数如下表所示:
标准
单反爱好者
跑鞋爱好者
饮料爱好者
护肤品爱好者
…

对上述数据进行分析,我们可以轻而易举的得到答案:该用户的标签应该是“单反爱好者”,因为他的点击行为集中在这个标签上。但是,这个答案是我们以用户的点击行为作为标准得来的,如果以用户的浏览和搜索行为做标准,答案也是“单反爱好者”吗?我们再来看一下相关数据。
标准
单反爱好者
跑鞋爱好者
饮料爱好者
护肤品爱好者
…

标准
单反爱好者
跑鞋爱好者
饮料爱好者
护肤品爱好者
…

是不是出问题了?以点击和浏览为标准,该用户标签应该是“单反爱好者”,但是以搜索为标准,标签应该是“跑鞋爱好者”。如果该用户的标签只能有一个,那该选哪一个呢?为了解决这个问题,我们从数学角度分析一下好了。嘿嘿,数学噢,前方高能预警!我会尽量让这个过程变得简单,大家跟上我的思路哈。
Step1. 泊松分布
一句话解释泊松分布:猜猜我在哪儿~~~
我们先来介绍下泊松分布。啊啊啊啊!一上来就是数学,我不听我不听我不听,泊松分布是什么鬼?咳咳,那,那就先不丢公式了,咱们看图解决问题好了,下面是泊松分布绘出的曲线图,实际工程中要解决的问题就是找到图中的最高点,如下图:

这个肉眼找最高点的过程不要太简单了!!!我们可以看到:图中最高点的纵坐标大约为0.36,而对应的横坐标是1。OK,你就算会用泊松分布了哦!那个,感兴趣的同学们,可以一起来看看对应上图的泊松分布的公式。

公式相对于图,是有那么点点复杂啦。不过,我们只需知道λt影响泊松分布的形状,一个λt对应一个泊松分布就可以了。这个场景下要做的事情就是找到对应泊松分布图像的最高点。
Step2. 一个结论
一句话解释这个结论:一个萝卜一个坑。
我们先说一个结论:在一个标准下,所有用户占有的标签,在所有标签上的概率分布是满足泊松分布的。对于这个结论,有兴趣的同学可以参见Stanford 《Introduction to Computational Advertising》讲义Page-81,我们在这里就直接拿来用了。而所谓“标准”,就对应泊松分布公式中的λt,在我们这里的场景下与用户行为有关。
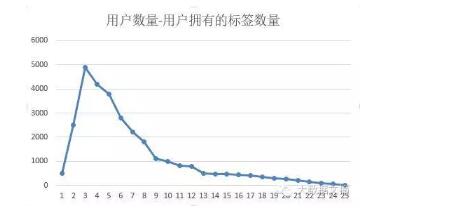
这张图的横轴代表用户拥有的标签数目,纵轴代表兴趣标签数目为x的用户数目,比方说有1个标签的用户有500人,有3个标签的人有5000人。从这张图中我们可以很清楚的看到,用户在所有标签上的分布是满足泊松分布的。但是这里有一个问题,大量用户所呈现出的这种泊松分布,和单独用户的兴趣标签之间有关联吗?我们说,关联不大,因为一个是随机过程,一个是随机事件,想要得到每个用户的兴趣标签,其实是一个复杂的任务。下面我们从统计和投票的角度入手,来看一种用户打标签的方法。
Step3. 最佳标准
一句话解释最佳标准:盲人摸象
“盲人摸象”比喻以偏概全,现在我们想要知道大象全貌,把每个人摸到的拼起来便是了。在广告系统中,搜索、点击和浏览三种行为数据都只能从一个侧面反映用户的行为,要想完整的刻画一个用户,我们需要将这三种行为融合起来之后找到一个最佳标准。提到融合,较为常用的方法是投票,我们可以写出下列公式:

简单解释一下:ti是标准,分别代表了搜索、点击和浏览行为;ωi是标准的权重,即该标准对于完整描述用户行为的贡献。我们用机器学习中的广义线性模型对该问题进行建模,模型训练完成后可得各标准的权重ωi,从而预测出最佳标准λt。
Step4. 最终求解
通过广义线性模型,我们找到了最佳标准λt。现在,我们根据该λt画出相应泊松分布,如下图:

回顾Step2中的结论:在一个标准下,用户在所有标签上的概率分布是满足泊松分布的。现在最佳标准下的泊松分布我们已经画了出来,该用户在所有标签中的概率分布也应该符合这个分布的。还是老步骤,我们找最高点所对应的标签,即标签5,所以该用户的动态标签是标签5,问题完美解决。
在学习了泊松分布和机器学习之后,媒体网站终于完成了用户标签的工作,看着那圆圆的饼图,流下了激动了泪水,哽咽着说“嗯..终于..终于可以卖钱了..”没错,流量可以变现了,互联网广告一脚踏进合约广告时代。但是仅仅知道“你是谁”,粒度还是太粗,卖不了好价钱。“要是知道你正在干嘛就好了”媒体网站嘴里嘟囔着,突然脑海中灵光一闪,大叫一声:(图片来自网络)
5.1.2 上下文标签关键技术
一句话解释上下文标签的做法:吃的是URL,挤的是标签。
“我当然知道他在干嘛!我有日志啊!我有他正在访问页面的URL!啊哈哈哈哈哈!”有了用户标签的经验,媒体网站处理起上下文标签来就显得轻车熟路了,总共分两步:第一,根据用户当前页面的URL,抓取用户当前浏览的页面内容;第二,提取页面内容的关键词,作为当前页面的标签。
通过URL获得页面内容是一个典型的爬虫应用,与搜索引擎的爬虫不同的是,广告系统的爬虫只抓取用户请求的页面,而非全网页面。鉴于上述原因,广告系统使用“半在线抓取系统”,该系统有三个特点。第一,仅对用户发起请求的页面进行抓取,节省了时间和成本;第二,将{URL:标签}存储下来,当其他用户发起相同页面请求时,直接返回标签结果,避免重复抓取。第三,考虑到某些频道页面内容可能会更新(例如”旧浪体育”),还可设置合适时间,周期地更新已存页面的标签。
在抓取到页面之后,如何提取标签也有几种常见方法。最简单的是利用规则,在URL层面上人为做映射,例如sports.oldna.com对应的页面标签就是”旧浪体育”。若用户是通过搜索发起的页面访问,还可以根据搜索词作为页面标签。当然,在广告系统使用范围较广的方法还是机器学习中的主题模型,得到页面内容在几个主题上的分布,从而判断页面标签。例如,sports.oldna.com页面内容在”体育”、”财经”和”游戏”三个主题上的概率分布分别为:
体育
财经
游戏

我们可以很容易的看出sports.oldna.com的标签是”体育”。这里值得注意的是,如果想要加工出”体育”、”财经”和”游戏”这种可解释的标签,通常需要采用有监督的主题模型。
能用的数据都用了,能打的标签也都打了,知道了“你是谁”和“你在看什么”之后,媒体网站这才感觉踏实了些。下面的工作就简单了许多,把标签卖给广告主就可以了,也算是一劳永逸,深藏功与名。至于用户会看到什么,那是广告主的地界,就不管媒体网站什么事儿了。
5.1.3 广告标签关键技术
普通的广告标签就是广告本身的属性,如所属广告主、广告大小、广告类别和目标人群等,当广告和用户两两匹配时,该广告就会展示给用户。但是,这里我们想说的广告标签是在程序化交易中的“个性化标签”。在《计算广告小窥[上]》中我们提到:“程序化交易是广告主为实现个性化营销举行的海天盛筵。”品尝过个性化营销的甜头之后,广告主就想:“既然这些人是回头客,那各方面表现和这些回头客很像的人,有没有可能也是我的回头客呢?世界那么大,我得去找找这种人。”
look-alike
一句话解释look-alike:比葫芦画瓢。
这个技术的名字还挺洋气呢,英文的,“看起来像”?说白了就是比葫芦画瓢,找到那些看起来像回头客的新用户,行话叫“新客推荐”。这里一定要注意了,千万不能翻译成“看起来像”,那样显得逼格不够,就叫英文的,look-alike~
关于look-alike的具体实现,市面上没有统一的做法,毕竟我们正在经历。这样一来我的心也放下了,因为即便我下面都是胡扯也不一定是错的。
look-alike的核心是按着回头客的样子去找新用户。那简单呀,看看回头客的标签是什么样子,对着去找相同的不就行了?没错,这算一种方法,并且是一种基于规则的方法。但是直觉告诉我们这样做粒度太粗,没有充分考虑到广告主因素,同时经验也告诉我们,基于规则的不如基于模型的效果好,所以我们还可以得出一个基于模型的做法:将某用户是否是潜在用户建模成一个机器学习中的二分类问题,利用回头客数据训练模型,并在新用户上做预测,是就是1不是就是0,也挺好理解的。
受众定向关键技术我们就介绍到这里了,现在我们来回顾一下。为了更加精准的刻画用户,我们从用户标签、上下文标签和广告标签三个方面来介绍受众定向。虽说角度不同,但总的说来,不外乎两种方法:基于规则和基于模型。在受众定向技术的支持下,互联网广告进入合约广告时代。在经见了在线分配的大坑之后,媒体网站发现合约不可保,便使用竞价方式售卖流量,指定广告主。那在竞价广告中,又有什么关键技术呢?请看下一小节:竞价广告关键技术:点击率预估。
5.2 竞价广告关键技术:点击率预估
| 郭德碗:聊(bi)了(bi)了这么久,想必衣食父母也都累了。
于 兼:是有点儿。 郭德碗:能坚持看到这儿的人不多。 于 兼:东西太难。 郭德碗:那就歇了吧,《计算广告小窥》到此结束! 于 兼:给我回来!像话嘛这个! 郭德碗:还想怎么着啊? 于 兼:说好的点击率预估呢?大伙都冲这个来的。 郭德碗:真有冲这个来的? (有!) 郭德碗:怎么不提钱跟我说呢? (吁~) 郭德碗:好了,玩笑归玩笑,驴鞭归于兼,下面呀,我.. 于 兼:您等会儿,那玩意儿归我干嘛呀? 郭德碗:嘿嘿嘿。 (吁~) 郭德碗:你们都懂? (吁~) 郭德碗:仁者见仁,污者见污哟。 (下去吧~) |
我知道很多同学是冲着点击率预估来的,所以不能让你们白来不是,免费送您一小段儿,别跟我提钱哈哈。等最后聊到最小广告系统,帮我贡献几次点击就行,我也好收集一些高质量数据,训练模型自己玩儿。言归正传,下面我们将从“是什么”、“为什么”和“怎样做”三方面来介绍点击率预估。
5.2.1 点击率预估是什么
点击率
一句话解释点击率:0.1%
既然聊到点击率预估,那我们先来看看什么叫点击率。点击率这个概念我们是第一次提起,但其实我们早就知道它了。我们在《计算广告小窥[上]》曾经提到:
“自从广告上了互联网,广告的面貌就焕然一新。造成行业巨变的原因,是因为互联网广告的效果可以被衡量。”
如果接着往下说,以什么标准来衡量呢?没错,最常用的衡量标准就是点击率。点击率(CTR:Click-Through Rate)是指的是媒体网站上某个广告的点击量/展示量。之所以使用点击率来衡量广告效果是有原因的,先来看分母:分母是某广告的总展示量。在《计算广告小窥[上]》中我们曰过,广告展示机会是广告主通过竞价获得的,展示机会越多,意味着广告主的出价越高,所以总展示量可以用来表征广告主的广告投入。再来看分子:分子是总点击量,而点击行为代表了用户的注意力,说明用户渴望进一步了解广告内容。因此点击率越高,意味着广告主在相同投入的情况下,收获了更多的用户注意力,完美诠释了广告主做广告的初衷,所以点击率是广告主和媒体网站常用来衡量广告效果的标准。我听过一个数字,广告平均点击率为千分之一,也就是每展示1000次广告才会收获1次点击,所以点击率预估中数据都是很稀疏的。
点击率预估
一句话解释点击率预估:80%
了解了点击率,我们再来看看什么叫点击率预估。从字面上理解,点击率预估是预测媒体网站上某个广告的点击量/展示量,然而这样理解并不是很准确,我先给出我的理解:点击率预估,是指预测特定用户点击特定广告的概率,例如小明点击某信二手车广告的概率是80%。
为什么对媒体网站广告点击率(0.1%)的预测,会变成了对用户点击某广告概率(80%)的预测呢,接着往下看啦。
5.2.2 为什么要做点击率预估
一句话解释为什么要做点击率预估:钱。
在竞价广告阶段,广告主与媒体网站之间以按点击付费(CPC)的方式结算,因此我们可以用下列公式来表征媒体网站在某次广告活动中的收入:
媒体网站收入 = (点击率 * 展示量) * 单次点击价格 = 点击量 * 单次点击价格
我们知道,展示量和单次点击价格这两部分都是广告主参与竞价后才能决定的,与媒体网站无关,所以媒体网站的收入就与点击率直接挂钩。在收益最大化的驱使下,媒体网站有提高点击率的动力。点击率的定义是点击量/展示量,展示量又是广告主通过竞价决定的,因此媒体网站只能想方设法提高点击量。
对于媒体网站而言,他所拥有的资源就是页面上几个固定的广告位和海量的用户。为了提高点击量,一种简单明了的想法就是让展示的广告尽可能多的被点击,即“指哪儿打哪儿”。为了实现这个理想,亟需解决两个问题:首先需要知道用户感兴趣的广告有哪些,其次需要让用户尽可能多的点击这些广告。
第一个问题叫做“广告检索”,是指媒体网站根据用户的定向标签或其他方式检索出符合用户口味的广告候选集合。这部分内容是搜索引擎的核心,在这里我们就不展开讨论了。我们来看第二个问题,假设我们已经得到了一个符合用户口味的广告候选集合,如何能让用户更多的点击呢?很简单,把用户最可能点击的广告放在最显眼的地方,为了定量描述用户最可能点击的广告,这便引出了点击率预估的问题。因此我们说,点击率预估并不是来预估媒体网站上点击量/展示量,而是预测某个特定用户点击某个特定广告的概率。OK,那预估完干什么呢?刚才不是说了嘛,把最可能点击的广告放在最显眼的地方呀!
最显眼的地方
一句话解释最显眼的地方:你也是柳岩的球迷?
为了较为直观地描述用户的注意力分布,我找了一张LinkdIn的用户注意力热力分布图。(图片来自网络)

图中,颜色越红代表用户注意力越集中。可以看到,用户最关注的是页面的上半部分,其次是右半部分,最后是下半部分。这种注意力分布基本我们日常的浏览习惯,即如果能在页面靠前位置找到我们所需的信息,一般就不会再关注页面其他地方。了解了注意力分布,我们来看一下某度搜索页面上的广告位分布。
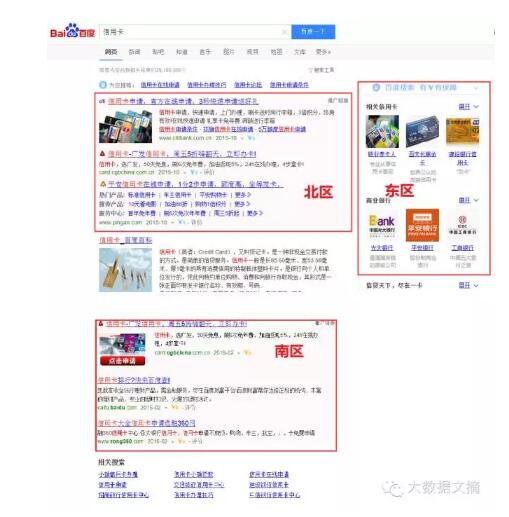
某度广告位主要分布在北区、东区和南区三部分,以LinkedIn页面中的用户注意力分布来推测,用户在某度页面上注意力分布从高到底分别是北区、东区和南区。假设某度共有10个广告位,那么将用户最可能点击的10个广告按照点击概率由高到低顺序分别排在北区、东区和南区。然后还干嘛?没有了,万事俱备,只欠点击。
不知道您听明白了没,我来帮您捋捋。为了提高媒体网站的收益,我们结合业务场景不断简化问题,从提高媒体网站点击率入手,到提高总点击量,再到获得广告候选集合,预测出了用户点击广告的概率。仅仅预测点击概率媒体网站还赚不着钱,因此媒体网站根据点击概率在页面广告位上对广告进行排序。所以为什么要做点击率预估呢?都是为了钱!都是为了钱!都是为了钱!
5.2.3 点击率预估怎么做
一句话解释点击率预估怎么做:使尽浑身解数,只为更懂你。
自计算广告学诞生以来,点击率预估就是一个在学术界和工业界被广泛研究和实践的课题。剥去种种具体场景,点击率预估的本质其实还是一个机器学习中的二分类问题。一般来讲,媒体网站点击数据的数学分布是非线性的。为了拟合这种非线性关系,学术界侧重于模型的研究,工业界侧重于特征的构造,双方优势互补,已取得了相当丰硕的成果。下面我们将先介绍展示广告和搜索广告这两种互联网广告的主要形式,然后阐述二者在点击率预估问题上的不同之处,最后介绍一些点击率预估的方法。
展示广告
展示广告(Display Advertising)是一种以“图片+文字”的方式进行广告宣传的互联网广告形式。从广告触发方式来看,展示广告是媒体网站根据用户历史行为所做的推荐,对用户而言广告是被动接收的,如下图。

搜索广告
搜索广告(Sponsored Search)是一种以“标题+超链接”的方式进行广告宣传的互联网广告形式。从广告触发方式来看,搜索广告是媒体网站针对用户当前检索所做的广告匹配,广告是用户主动发起的,如下图。

根据上面我们对展示和搜索广告的描述,我们可以对两种广告形式的点击率预估有一个浅显并直观的认识:展示广告的点击率预估可以看作是一个推荐问题,根据历史记录推测用户对哪些广告更感兴趣;搜索广告的点击率预估可以看作是一个检索问题,根据用户当前的查询来做广告匹配。前者推荐后者检索,问题性质的不同也决定了点击率预估所采用方式的不同。
点击率预估方法
有关展示广告和搜索广告的实现算法和应用细节都是各家互联网公司的商业机密,由于场景的不同,各家对点击率的预估也是八仙过海各显神通。作为一个没有实战经验的小屁孩儿,想要较为流畅地阐述这个话题,还是力不从心,毕竟眼界太窄太年轻。为了保证文章结构的完整,这部分还必须要写,那么我就抛开业务场景,仅从机器学习角度来和大家聊一聊我所知道的内容。写的不好,还请各路大神多多指教,如有不当指出,请严厉指出,我定感激不尽!
上面我们提到过,从用户浏览网页到广告获得展示,要经过三个阶段:用户定向、广告检索和广告排序。用户定向和广告检索就不多说了,最终在广告库中可以找到符合你口味的广告,即“万里挑十”。在广告排序阶段,需要将这十个广告位放置在页面上,通常做法有两种,一个是基于规则,一个是基于机器学习。我们这里从机器学习的角度入手,但是各位千万不要忽视了规则的能力。聊到机器学习,主要就是两方面,特征和模型。下面我就根据我所了解的内容,重点介绍一下线性模型+海量特征的方法,然后简单介绍一下点击率预估的发展。
<1>线性模型 + 海量特征
用于点击率预估的数据主要是日志数据,一般会有点击行为(点击为1,没点为0)、广告信息(广告位、广告主id、广告标签和广告描述等)、用户信息(用户id和用户标签等)、上下文信息和时间戳等。有了这些原始数据之后,需要对数据进行清洗,然后利用统计或模型的方法构造特征,进而做特征选择和特征组合,最终特征的数量级大约在10亿-100亿维。完成了特征工作之后,在模型方面,较为经典的点击率预估模型是线性模型Logistic Regression,由于LR在通过sigmoid之前是一个[0,1]之间的浮点数,利用LR的特点,我们可以将这个浮点数作为用户点击该广告的概率,把广告按照这个概率从高到低放置在相应广告位上,就完成了广告排序。
为什么要造出维度这么高的特征向量呢?我的理解是这样的。对于点击数据来说,点击行为与其他特征之间的关系是非线性的,为了拟合这种非线性关系,我们依然可以从特征和模型两方面入手。通常来说,非线性模型的效果要更好一些,但是效率太低,不适合工业界的现实场景,所以快速简单的线性模型就成为了模型的首选。那线性模型如何拟合非线性关系呢?这就需要在特征层面做文章,利用特征工程的方法来构造出高阶特征,同样可以实现非线性。这个思路理解起来还是不难的,如下面两式对比:

<2>点击率预估的发展
为了构造出维度如此巨大的特征向量,特征工程几乎占据了70%的项目时间,并且主要是靠努力的程序员人工来实现的。那有没有自动选择特征的方式呢?ADKDD’14有一篇Facebook的paper《Practical Lessons from Predicting Clicks on Ads at Facebook》提出了一种使用GBDT自动选择特征的方法,用每棵树上的叶子节点来表达特征,比如{1:2, 2:3}指的是第一棵树上第2个节点和第2棵树上第五个节点,根据每棵树的节点个数用one-hot表示即可。多说一句,GBDT选特征的方法已经经过实践验证,在Kaggle-Criteo点击率预估大赛中,冠军的解决方案便是GBDT+FFM的方法获得的。
说到FFM,它是FM的一个变种。FM(Factorization Machine):因式分解机是最近比较火的一个模型,这个模型可以挖掘出特征间的非线性关系,并且可以在O(n)的时间内完成计算,非常吸引人。
最后就是深度学习了,在视频、图像和语音领域有较为突出的成果。最新的听说MSRA出了一个152层的网络,OMG…国内在广告领域应用深度学习最早的应该是百度凤巢,低于10层,经过多轮迭代之后效果初显。我自己也在探索阶段,期待能有好的结果,这里就不多说了。
点击率预估环节到这里就结束了,以上内容不知是否和您心意。部分内容可能需要一些机器学习背景,对此感兴趣的同学可以加入我们的QQ群(初学者373038809,行业同学和研究者472059892),我们共同讨论。
5.3 程序化交易关键技术:出价策略
在上半部分中,我们曾经介绍过程序化交易中的参与者,除了用户外,主要还有代表媒体网站利益的SSP、代表广告主利益的DSP和小三ADX。通俗来讲,SSP是管仓库的,ADX是管传话的,DSP是管花钱的,现在我们要开始聊程序化交易中的关键技术,您觉得我们应该把目光放在谁上面呢?已经讲到现在了,我们要收起情怀,统一思想,当然是要重点关注DSP啦!你可能会想,花钱谁不会啊,这要啥技术?没错,花钱是没什么难的,但对于广告主而言,花钱做广告是一种投资,本质和风投股票文玩楼盘高利贷没什么区别,追求的就是高的投入产出比,真刀真枪的动起钱来,弄不好会走火入魔的。这钱,您还敢花吗?
敢啊!
要是不敢我还怎么写博客嘛,哈哈哈哈哈~~~花钱不要紧,只要能挣就行了呀!那我们就来聊聊如何才能挣的比花的多吧。
5.3.1 出价原则
上面我们提到,广告主花钱做广告实际上是一种投资行为,既然是投资,就要对风险进行评估。具体到DSP来说,“投资”是指广告主投钱给DSP,让其参与实时竞价,期望获得良好的广告效果(点击/购买/注册/下载等);“风险”是指钱花了,但由于效果太差,没见着收益。为了规避风险,获取较高的投入产出比,DSP在出价时需要进行“风险评估”,即预估本次广告展示机会所能带来的收益,以此作为出价的参考。在出价时,要注意以下几点原则,可能并不全面,还请行业内的同学补充。
- 预算限制:广告主一次就给这么多,超了算你的。
- 时间限制:到时间花不完就收回去了。
- 花钱为主:都说了是投资,能花了就别留着。
- 见好就上:出价与流量品质成正相关。
这些出价原则理解起来没什么难的,但我想要着重说一下第四条见好就上,这才是最关键的部分。如何定义流量品质,又如何出价呢,好戏马上开始。
5.3.2 如何定义流量品质?
所谓流量品质,就是在此时此刻此情此景,用户点击广告能为广告主带来的收益,主要分为两部分:一是点击率,二是点击价值。点击率的预估就不多说了,和媒体网站上点击率预估是类似的,只不过在实时的场景下要求会更高一些。点击价值是什么意思?刘鹏老师在《计算广告》中这样解释道:(有部分修改,括号内容为我的解释)
点击价值可以分解为到达率、转化率和转化单价三个量的乘积。到达率是指实际打开广告次数与点击次数的比例,这与广告主网站的页面你打开延迟关系最大,与媒体的属性、特别是误点情况也有一定关系;转化率指的是到达广告主页以后,有多少比例产生了广告主定义的转化行为(购买/注册/下载等);转化单价是指广告主指定的转化费用(即DSP做一单能挣多少)。
上述三个变量中,到达率和转化单价都是很好统计的,只有转化率的预估是比较困难的。转化率预估的方法可以参照点击率预估,但是由于转化数据要比点击数据少得多,除非是在有充足行业数据支持的情况下,否则用机器学习方法建模有较大困难。实践中比较可行的办法基本上都是简单统计与运营经验相结合来估算转化率。
5.3.3 如何出价?
终于进入到了最核心的出价环节。按照“见好就上”的原则,出价与流量品质成正相关。那到底是采用线性策略好,还是非线性策略好呢?我们来仔细分析一下。
(1)线性出价策略
我们在CTR预估阶段提到过用户注意力,广告位这个物理因素对点击率的影响是十分显著的。我曾看到过一个数字,同样一个广告,把它放在第一位所获得点击率是放在第二位时的两倍。若采用线性出价策略,DSP在出价时就有必要出两倍于第二位的价格去参与竞价。这个思路很好理解,感兴趣的同学可以参照KDD’12的paper《Bid Optimizing and Inventory Scoring in Targeted Online Advertising》。
(2)非线性出价策略
非线性策略是我想说的重点,主要是想借着这个机会介绍一下限制条件下的优化问题以及其解法,这对于我们做科研或者工程项目都是很有帮助的,下面我们通过KDD’14《Optimal Real-Time Bidding for Display Advertising》一文来了解一下非线性出价策略的来龙去脉。以下内容是我对这篇paper的个人理解,可能并不到位,既然写出来就不怕大家笑话啦,有错就改嘛嘿嘿。
<1>. 文章大意
实时竞价的场景中,在预算限制条件下如何设计出价策略是我们关注的焦点。为了实现这一目标,分为三步。第一,将现实问题用数学方法建模为限制条件下的优化问题,并通过拉格朗日乘子法,求得出价策略的数学表达式;第二,利用品友RTB出价算法大赛的数据拟合出价策略中的参数;第三,验证结果,发现了一个有意思的结论:相比少量高品质的展示机会,那些大量低品质的展示机会同样可以具有较好的广告效果,值得出价。这个发现对于那些预算不够,同时又想做广告的小广告主来说,简直就是福音。
<2>. 建立模型
在一切开始之前,让我们先考虑清楚要解决的问题是什么,简单来说就一句话:选择合适的出价策略,在预算的限制下实现广告效果最大化,用数学语言描述就是下面这样:

我靠!这一堆是什么玩意儿!你TM在逗我?淡定。。看不懂就对了啊哈哈哈哈!下面我来做一下简化,告诉你这个模型在我眼中长什么样。
b()ORTB=argmaxb()一大坨 !
subject to 又一大坨 !
这下是不是好多了?反正我第一次看到这个模型就长这样,把积分部分当作一大坨,就很容易看懂了。这个模型一共有两个公式,我们一一来看。
b()ORTB=argmaxb()一大坨 !
第一个公式是一个等式,等号左边是我们想得到的出价策略函数b()ORTB,等号右边是argmaxb() 跟上一大坨,这里argmaxb()的意思是:当后面一大坨取最大值时,返回在最大值情况下的那个b()。将等号左右两边连起来,这个等式所表达的意思就是:当后面一大坨取最大值时,返回在最大值情况下的那个b()作为我们要求的出价策略b()ORTB。这个思路是不是有点眼熟?没错,在前面合约广告关键技术——受众定向中,讲到用户动态特征时我们对泊松分布的处理方式有些类似。综上所述,对于这个等式而言,我们要做的工作就一个:求最大值。
subject to 又一大坨 !
第二个公式是一个不等式,subject to是“受限于”的意思。在这里,又一大坨 !
现在我们的任务已经明确了:在限制条件下求等式最大值。那么这个数学任务和我们的实际问题:选择合适的出价策略,在预算的限制下实现广告效果最大化是怎么匹配上的呢?这就需要去看那两大坨了。那一大坨全都是各种符号,我们看不懂,所以需要一张符号对照表,如下图。为了方便,我再把模型公式再贴一次。

有了符号定义和模型,我们开始聊(啃)一聊(啃)这两大坨吧。先看第一坨,我们从右往左看。
- dx:x代表一次bid request,是ADX发给DSP的竞价请求“标识XXX,男性,20-25岁,跑鞋爱好者,广告位为首页”,即一次广告展示机会。之所以是dx而不是x,是因为我们关注的是整个广告推广计划中所有的竞价过程,而非某一次竞价。
- px(x):广告展示机会的概率密度分布,我的理解是在全网所有的竞价中,满足我DSP要求的、或者是我能收到的bid request所占的比例。因此,px(x)∗dx的物理意义是“我能收到的展示机会”。
- θ(x):θ是赢得此次竞价所能带来的收益(KPI),本文用CTR来衡量,CTR越高,收益就越高。
- b(θ(x),x):对于此次展示机会,在能带来收益为θ(x)的情况下,我所出的价格bid。
- ω(b(θ(x),x),x):对于此次展示机会,在能带来收益为θ(x)的情况下,我的出价bid能获胜的概率是多少。因此,
![]()
的物理意义是“对于本次我所收到的这个展示机会来说,在该机会能带来收益为θ(x),我出价为bid的情况下,我能打败对手获得此次展示机会的概率”。
![]()
的物理含义是“我出价为bid,赢得这次展示机会后,所能获得的收益”。
- NT:一次广告推广活动中所有的bid request。
有了上面的解释,我们可以很容易的得出第一坨的物理意义:对于一次广告推广活动中的所有竞价,我使用b()的出价策略所能获得的收益。和等式连起来,即:对于一次广告推广活动中的所有竞价,我使用b()的出价策略所能获得最大收益时所对应的b(),就是我们想要的出价策略。
有了第一坨的经验,第二坨啃起来就容易多了。前面都不变,只有到最后把
![]()
其物理意义为:对于这次广告展示机会,我出价为bid且赢得这次展示机会所花费的预算。所以对于整个广告推广活动而言,所有的出价要小于预算。就这样,我们顺利的将预算限制写进了数学模型里。
好了,分析完两大坨积分的含义之后,我们合起来解释一下该模型(ORTB)所表达的物理意义:在整个广告推广活动中,在出价总和小于预算的限制条件下,当广告收益取得最大值时所对应的那个出价策略,就是我们梦寐以求的出价策略b()ORTB。再来对照一下我们的任务:选择合适的出价策略,在预算的限制下实现广告效果最大化。这下匹配了吧!
<3>. 模型求解
截止到目前,我们已经得到了模型表达式,由一个等式和一个不等式组成。接下来我们就要开始求解了:求最大值。最大值有什么好求的?让导数等于0之后带入极值点不就完了?你说的对,如果只有一个等式我们是这么求的,但问题是我们现在除了一个等式,还有一个不等式,这种情况下怎么来求最大值呢?用拉格朗日乘子法。
通过拉格朗日乘子法,我们可以将不等式乘一个参数λ后和等式写进一个公式里(化简过程已省略),得到如下结果。
![]()
有了这个公式,我们就可以对它进行求导等于0了,可得如下结果:
![]()
通过化简,可得出价函数b()与胜率函数w()的关系:

也就是说,我们想要的出价函数b()与胜率函数w()有关,那我们就来看看他们之间到底有什么关系。通过对数据的统计,可以画出出价函数b()与胜率函数w()的关系图像:
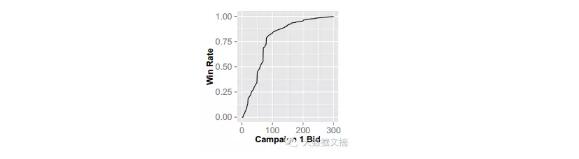
从图像中我们可以看出,出价函数b()与胜率函数w()的关系是非线性的,并且这个曲线的走势和y=xc+x很像,我们来对比一下,这里c=3。

没错,的确很像。基于此,为了达到消元的目的,作者做了一个出价函数b()与胜率函数w()之间的假设,仿照着y=xc+x得到下面公式:

将出价函数b()与胜率函数w()的9式关系带入到倒数为0的7式中,化简可得:

就这样,我们得到了我们的出价策略bORTB()的表达式(公式13)。我们来看看这个公式里有什么。这个公式是由θ, c和λ组成的,其中c和λ都是常量,只有θ一个变量。c是出价函数b()与胜率函数w()之间的系数,λ是拉格朗日乘子,而θ是每次广告展示的收益,按CTR高低来评判。我们来验证一下:CTR越高,由该策略算出的出价也就越高,符合我们的预期,大功告成。
我们来梳理一下思路。在建模环节,我们已经得到了我们所需的模型:一个等式+一个不等式。我们的任务是要求等式的最大值,通常方法直接对等式求导等于0即可,由于我们这里是一个限制条件下的优化问题,所以需要用到拉格朗日乘子法,将限制条件写进等式中,构造出一个新的公式(公式6)。对于新的公式,我们就可以用求导等于0了(公式7)。在化简过程中,我们发现了出价函数b()与胜率函数w()存在着数学关系(公式8),为了消元,我们按照实际数据的分布构造出出价函数b()与胜率函数w()的表达式(公式9),将公式9带入公式7,继续化简就得到了我们的出价策略:bORTB(),剩下的工作就是根据数据去拟合λ和c即可,这里就不多说了。这里需要强调的是,这种限制条件下的优化方法在统计与机器学习中是很常见的,例如SVM的推导过程,感兴趣的同学可以试一试,其实并不难。
<4>. 结果分析
既然有了公式,那我们就来看看ORTB的出价有什么特点吧。

我们可以很直观的看出,我们所得到的出价策略是一个非线性的。横坐标θ代表了广告展示计划的品质,ORTB会对低价值的展示机会出高价,这样的结果能为我们带来什么,谁会去要那些低价值的展示机会呢?我们来看下面这张图。
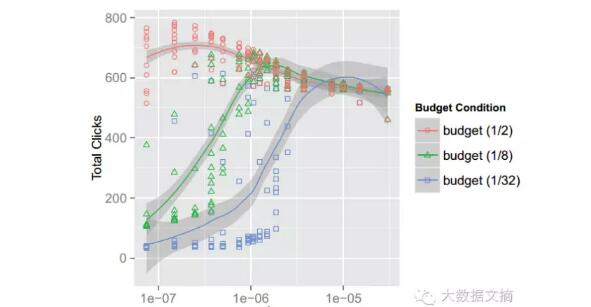
在此图中,我们盯着一条曲线看,比如蓝色的(1/32)。随着λ增加,收获的点击量是增加的,意味着λ越高,我们的收益越高。对于我们获得的出价策略而言,λ越高,我们的出价是越低的,也就意味着这次展示机会的价值是很低的。这样的结果值得我们深思,我们以为低价值的展示机会是不值钱的,但数据说明,这些看似不值钱的展示所能带来的回报还算不错。特别地,在λ=1e-05时三条曲线的几乎重合,而红色代表有钱的广告主,蓝色代表穷广告主,虽然预算差了16倍,但是获得的收益是相同的,这个结论对于预算有限的小广告主而言,是个天大的好消息:虽然我们钱不多,但只要我们出价合适,依然可以收获很好的广告效果,四两拨千斤,极大的调动了小广告主参加程序化交易的积极性。
我们知道,“二八原则”是客观存在的,在广告主中也不例外,如果能吸引这80%的小广告主参与程序化交易,玩家一多,需求自然更多。为了满足金主的需求,势必会推动相关计算技术的发展,这对于计算广告的未来而言,是一件好事。
讲完了非线性出价策略,程序化交易中的关键技术也接近尾声了。出价策略之所以重要,是因为就是DSP赖以生存的看家本领,没有这些真本事,DSP是走不了多远的。
到此,计算广告关键技术就讲完了,啥也不说了,给自己鼓个掌吧。
历时大半个月,中间又加上过年,终于把这章给写完了,没想到这一章的内容要比上半部分全文都要多。在本篇《计算广告小窥[中]这孙子怎么什么都知道》中,我们从理论的角度探讨了计算广告各阶段的关键技术:在合约广告中,我们讨论了受众定向技术,从用户、上下文和广告主三个方面简单介绍了打标签的常用思路和方法,为计算广告实现精准营销打下了坚实的基础;在竞价广告中,我们讨论了点击率预估的来龙去脉,感受到了互联网人的智慧,为媒体网站流量变现提供了直接保障;在程序化交易广告中,我们通过学术论文了解了当下学术界领先的DSP出价策略,近距离地感受了一下科研的魅力。
曾有人叹息到“我们这一代最聪明的人竟然都在这里思考着怎样让人们去大量的点击广告,真衰。”我个人不认同这种说法,因为在计算广告这样复杂的场景下,相关技术和解决方案的水准必然是顶尖的,稍加修改即可解决其他场景下的疑难杂症,这恰似军工技术反哺民用,又恰似女生随手甩一个不要了的护肤品给男生,那可都是宝。
受篇幅所限,原定于本篇要完成的第五章和第六章只好放在《计算广告小窥[下]广告系统架构:要啥自行车,这里有宝马。》中来写了。在下篇中,我们将介绍一个通用的广告系统架构,在领略在线和离线过程的同时,还将见到时下工业界最火热的技术,譬如Nginx,Hadoop,Spark等在计算广告领域的位置与应用。
除了广告系统架构,我还将介绍一个我自己搭的最小广告系统mieSys,可以先放出来给大家玩一玩,链接是http://115.159.33.50/。使用方法:用户点击页面中广告,等一段时间后刷新页面,在页脚处会显示用户的兴趣标签和性别,在第一行五个广告位中会展示符合用户口味的广告。需要注意的是,由于目前缺少点击数据,CTR模型并不准,为了保证演示效果,暂时只能用离线代替在线,所以您在点击过后预计要10分钟(用户多的话甚至更长)才能看到页面效果,我后期会进行优化,还望轻拍,效果图如下,第一张为默认页面,第二张为结果页面。

这个系统是我用大概20天的时间搭成的,目前来说基本的功能都有,但还是太简单,并且算法没有优化,我会逐步的往上面添加模块和算法,目前思路已有,就差各位为我提供点击数据了[嘿嘿嘿嘿···]。如果您发现mieSys挂了,不是用户太多就是我在调程序,在系统成熟的时候我会选择开源,愿意与有兴趣的同学多交流。哦对了,至于为什么起名为mieSys,因为我女朋友属咩,呵呵哒~
【本文是51CTO专栏机构大数据文摘的原创文章,微信公众号:大数据文摘 id: BigDataDigest】