51CTO学院IT课程1折起秒杀,12月12日0点万人秒杀准时开启,我是51CTO学院深度学习课程讲师浦深,跟大家分享一些个人经验。
在当前深度学习之下,随着大量的训练数据以及深度卷积神经网络(CNN)的推动,人脸识别或者是其他物体识别几乎比得上人的肉眼识别。利用一些独有的大规模训练数据集,一些研究团体在LFW或其他人脸数据集上取得了相当好的表现,达到了97%-99%的准确率。越来越多开源的卷积神经网络框架已经不断涌现出来,比如 Caffe、Theano、TensorFlow等,也有相应的很多人脸数据库,比如WebFace、FDDB、YouTubeFace、MultiPIE等等,包含了大量的人脸图片数据,情况看起来似乎很良好,卷积神经网络框架有了,大规模数据也有了,加上各种物体检测算法Rcnn、FastRcnn、FasterRcnn、Ssd等,仿佛可以不费吹灰之力训练得到一个表现良好的模型,然而,事实并非如此,请看下图:

我们从某个数据库下载下来的,一个名为jack的个人图片数据,可以看到,很多都不是同一个人的,当然,最重要的是这样混乱的个人图片文件夹还不在少数!这样的训练集是很难训练出另一个好的模型的。所以,当下的情况是:深度学习工程应用领域,数据比算法更重要!!!
上图所举的例子是图片质量比较差的情况,我们来看一个比较好的情况:

尽管说情况比较良好,但仍然夹杂着一些非本人的图片数据。
往下,我们来看看图片数据库是如何产生的,以及如何处理大规模图片数据集中的噪声,比如:在一个***别的数据集中去掉像***张图那样混乱的个人数据文件夹、去除质量相对较好的个人图片数据中非本人的图片数据。
图片数据库的产生(以人脸数据为例)
人脸识别数据集只需要两种数据:人脸图片和身份标签,随机地从网络上抓取图片并且标注它们,是一个几乎不可能的任务。我们这边介绍一个结构非常良好的网站IMDb,这个网站包含了人物的信息,包括名字、年龄、性别、生日以及个人照片。我们来看下:
可以直接搜索人物名字,比如我们搜索Ben Foster ,结果如下所示:
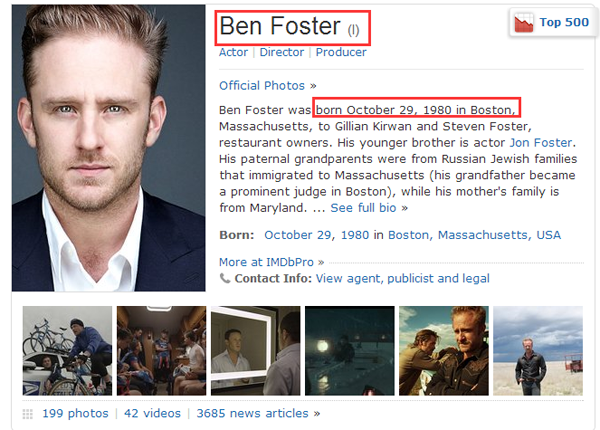
结果中包含该人物的多种信息:人名、生日、个人图片等等。你可以根据人名搜索每个人的数据,每个人物在网站上都有一个独立的页面,我们通过一个人脸检测器,可以自己训练一个浅层全卷积神经网络来处理,这个浅层网络的设计非常重要,因为在这个环节中,我们对图片处理的速度要求是比较高的,具体的网络设计及训练可以参考我的视频教程(http://edu.51cto.com/course/course_id-7650.html)通过这个人脸检测器,把所有图片中包含人脸的图片收集到本地数据库中。
这个阶段的数据还不能够用来训练,我们需要标注每张人脸图片所属的人名。我们可以看到,有写图片当中包含的不仅仅一张人脸,也包含了不同人物的人脸,我们的任务是对每一张人脸进行标注并且要把这些非本人的人脸划分到他们各自的文件夹里头。这个该如何处理?看如下这张图:
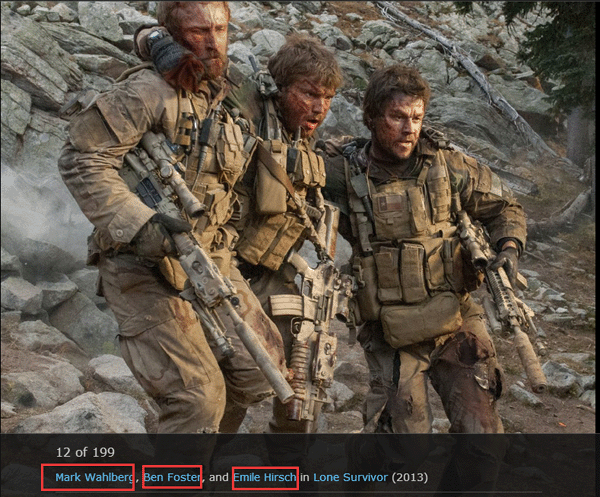
每张图片底下都包含着每个人物的名字,我们可以根据这个标签来进行处理,因为这个环节是对人名进行搜索,而每个人物的名字均来自于影片中的名字,极有可能出现同名不同人的情况,这也是造成我们获取到的人脸数据库质量不好的主要原因!
好了,问题出现总是需要解决的,我们要处理的问题有两个:1.去掉混乱程度较高的人物及其数据;2.去掉图片质量相对较好的图片中非人脸数据以及非本人的人脸数据。
我们可以这样来处理:在训练好的经典的分类网络,比如VGG,GOOGLENET等上进行微调训练,这个环节中重点是训练数据,数据来源可以选择一些质量较好的人脸数据库,加上适当的人工筛选效果更佳!那这个训练的网络作用是什么?是用来提取每张图片的特征,对吧!每张图片用一行向量去表示。那一张图片该用多少维度的向量去表示?这边的维度指的是:比如pic1=[1,2,3,4],指的是4个维度,即用4个数据来表示一张图片,然而实际的工程应用当中,向量的维度应该取多少合适?假设我们已经取得一个合适的维度,也对应修改好了相应的训练网络,并且提取好了每张图片的向量,对于***个要处理的问题(去掉图片质量相对较好的图片中非人脸数据以及非本人的人脸数据),因为图片的质量较好,可以取这个人的所有图片的向量的平均值来代表这个人物的特征,然后这个人的所有图片的特征值跟其对应的平均值求距离,设置一个阈值,把跟平均特征值距离远的图片过滤掉即可!
然而对于第二个问题(去掉混乱程度较高的人物及其数据),由于图片混乱程度相对较高,此时的平均特征值已经无法代表这个人了,此时,用解决上一个问题的方法已经不奏效了!!!该如何处理?
关于***种问题的处理方法在我的深度学习视频课程里头已经做了相应的讲解与示例,包括特征的提取等基本操作均已详细进行了说明。关于第二个问题的解决方案及其相应的算法编写、工程经验等都将会陆续在课程中进行补充!
我的课程是用Windows的版本进行演示,其实,不管是在Linux下或者Windows下,仅仅编译的时候有些区别,而对于caffe的使用基本上是一致的,请大家放心,Windows下用VS2013的开发环境会更友好一些,比如在课程中我也将会带大家一起修改caffe的源码来满足lmdb的多标签输入的要求,在Windows下显得更方便,当然也可在Windows下更改后,再把工程拷贝到Linux下进行编译。
欢迎大家报名学习我的视频课程:http://edu.51cto.com/course/course_id-7650.html