一、什么是高可用
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
很多公司的高可用目标是4个9,也就是99.99%,这就意味着,系统的年停机时间为8.76个小时。
百度的搜索首页,是业内公认高可用保障非常出色的系统,甚至人们会通过www.baidu.com 能不能访问来判断“网络的连通性”,百度高可用的服务让人留下啦“网络通畅,百度就能访问”,“百度打不开,应该是网络连不上”的印象,这其实是对百度HA***的褒奖。
二、如何保障系统的高可用
我们都知道,单点是系统高可用的大敌,单点往往是系统高可用***的风险和敌人,应该尽量在系统设计的过程中避免单点。方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
保证系统高可用,架构设计的核心准则是:冗余。
有了冗余之后,还不够,每次出现故障需要人工介入恢复势必会增加系统的不可服务实践。所以,又往往是通过“自动故障转移”来实现系统的高可用。
接下来我们看下典型互联网架构中,如何通过冗余+自动故障转移来保证系统的高可用特性。
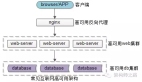
三、常见的互联网分层架构
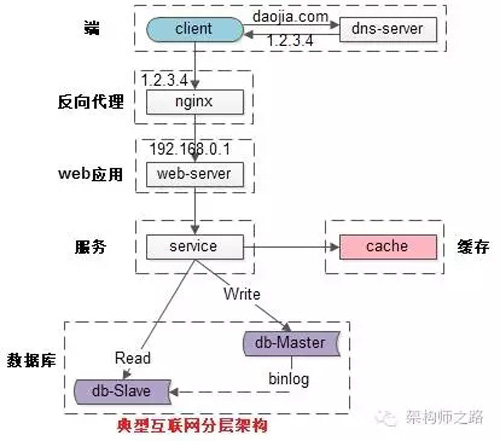
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余+自动故障转移来综合实现的。
四、分层高可用架构实践
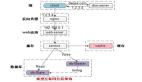
【客户端层->反向代理层】的高可用
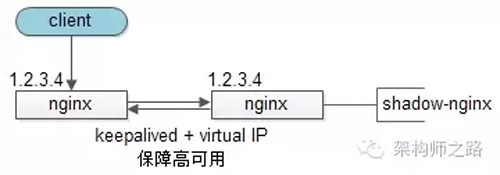
【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余来实现的。以nginx为例:有两台nginx,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
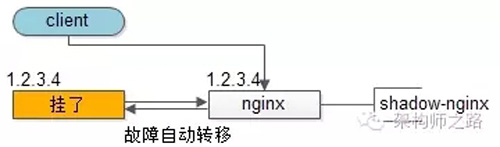
自动故障转移:当nginx挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-nginx,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的。
【反向代理层->站点层】的高可用
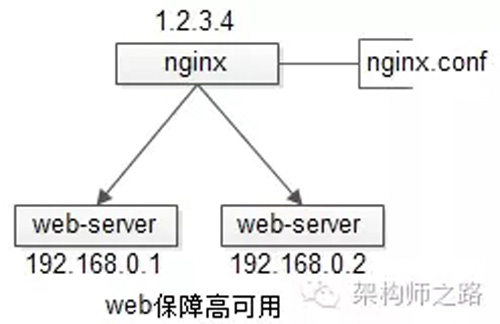
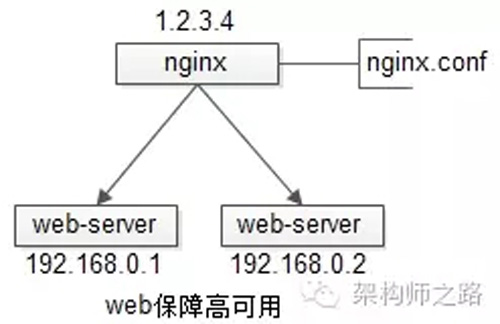
【反向代理层】到【站点层】的高可用,是通过站点层的冗余来实现的。假设反向代理层是nginx,nginx.conf里能够配置多个web后端,并且nginx能够探测到多个后端的存活性。
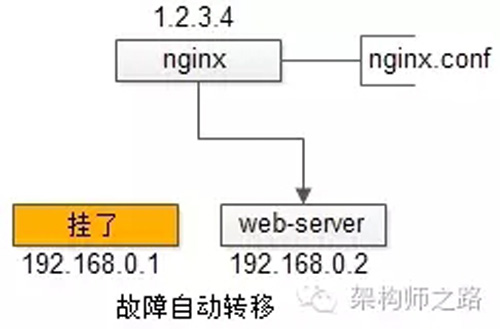
自动故障转移:当web-server挂了的时候,nginx能够探测到,会自动的进行故障转移,将流量自动迁移到其他的web-server,整个过程由nginx自动完成,对调用方是透明的。
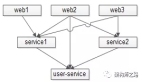
【站点层->服务层】的高可用
【站点层】到【服务层】的高可用,是通过服务层的冗余来实现的。“服务连接池”会建立与下游服务多个连接,每次请求会“随机”选取连接来访问下游服务。
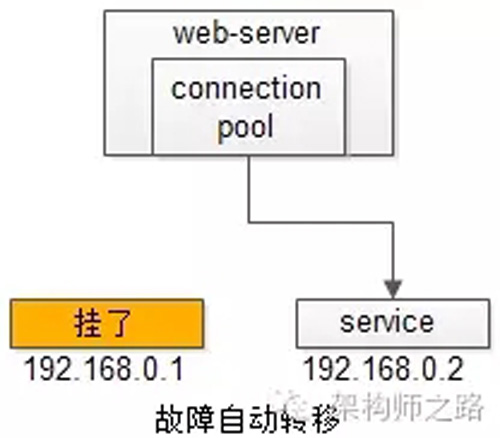
自动故障转移:当service挂了的时候,service-connection-pool能够探测到,会自动的进行故障转移,将流量自动迁移到其他的service,整个过程由连接池自动完成,对调用方是透明的(所以说RPC-client中的服务连接池是很重要的基础组件)。
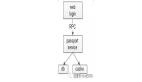
【服务层>缓存层】的高可用
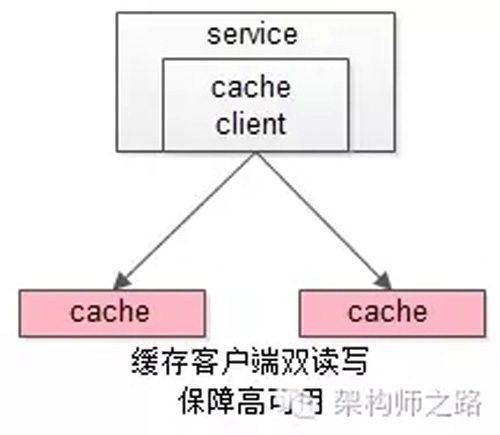
【服务层】到【缓存层】的高可用,是通过缓存数据的冗余来实现的。
缓存层的数据冗余又有几种方式:***种是利用客户端的封装,service对cache进行双读或者双写。
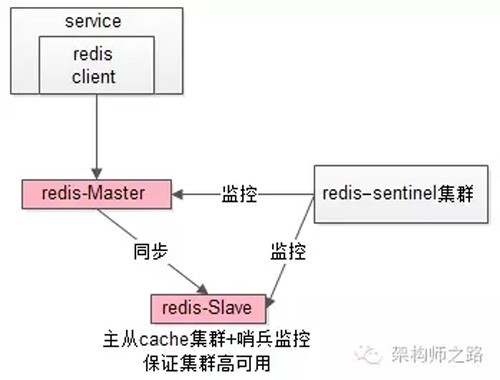
缓存层也可以通过支持主从同步的缓存集群来解决缓存层的高可用问题。
以redis为例,redis天然支持主从同步,redis官方也有sentinel哨兵机制,来做redis的存活性检测。
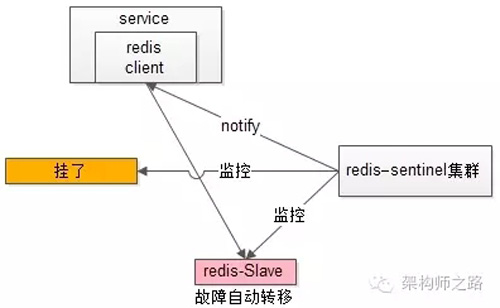
自动故障转移:当redis主挂了的时候,sentinel能够探测到,会通知调用方访问新的redis,整个过程由sentinel和redis集群配合完成,对调用方是透明的。
说完缓存的高可用,这里要多说一句,业务对缓存并不一定有“高可用”要求,更多的对缓存的使用场景,是用来“加速数据访问”:把一部分数据放到缓存里,如果缓存挂了或者缓存没有***,是可以去后端的数据库中再取数据的。
这类允许“cache miss”的业务场景,缓存架构的建议是:
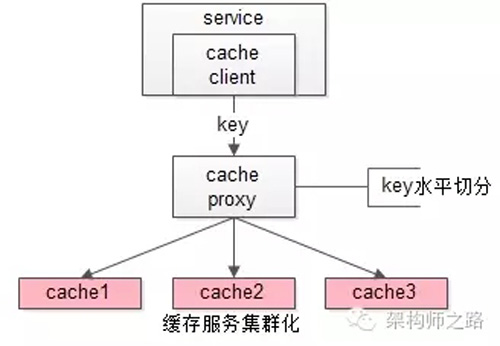
将kv缓存封装成服务集群,上游设置一个代理(代理可以用集群冗余的方式保证高可用),代理的后端根据缓存访问的key水平切分成若干个实例,每个实例的访问并不做高可用。
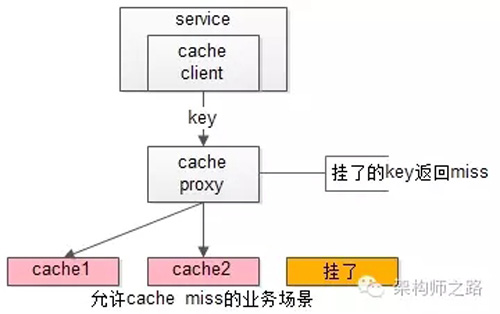
缓存实例挂了屏蔽:当有水平切分的实例挂掉时,代理层直接返回cache miss,此时缓存挂掉对调用方也是透明的。key水平切分实例减少,不建议做re-hash,这样容易引发缓存数据的不一致。
【服务层>数据库层】的高可用
大部分互联网技术,数据库层都用了“主从同步,读写分离”架构,所以数据库层的高可用,又分为“读库高可用”与“写库高可用”两类。
【服务层>数据库层“读”】的高可用

【服务层】到【数据库读】的高可用,是通过读库的冗余来实现的。
既然冗余了读库,一般来说就至少有2个从库,“数据库连接池”会建立与读库多个连接,每次请求会路由到这些读库。

自动故障转移:当读库挂了的时候,db-connection-pool能够探测到,会自动的进行故障转移,将流量自动迁移到其他的读库,整个过程由连接池自动完成,对调用方是透明的(所以说DAO中的数据库连接池是很重要的基础组件)。
【服务层>数据库层“写”】的高可用
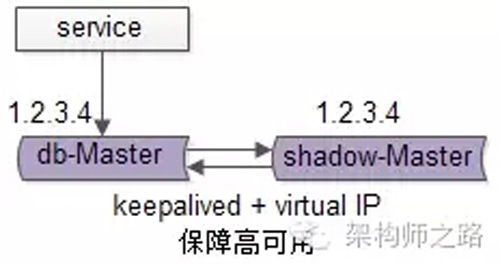
【服务层】到【数据库写】的高可用,是通过写库的冗余来实现的。
以mysql为例,可以设置两个mysql双主同步,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
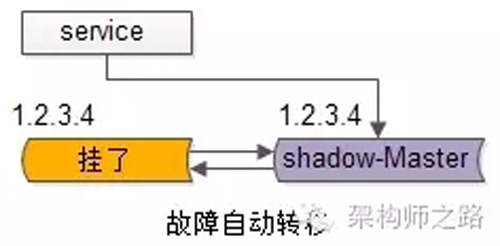
自动故障转移:当写库挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-db-master,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的。
五、总结
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
(2)【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
(3)【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
(4)【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
(5)【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
(6)【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
前段时间,受@谢工 邀请,在GitChat平台首发《究竟啥才是互联网架构“高可用”》。
12月01日周四晚8点30分,在微信群进行了针对该文章的的主题交流。以下是主持人@赫阳 整理的问题精华,记录下了我和读者之间关于高可用架构的问答精彩片段。
问答中所有文章都是可以直接点击跳转的哟。
问:在缓存层rehash过程中必然会有脏数据。一致性hash实际上只能减少rehash的成本,不能消灭脏数据,这种脏数据有没有办法避免?
答:如文章《究竟啥才是互联网架构“高可用”》所述,如果没有高可用需求,一台 cache 挂了,不宜做rehash,会产生脏数据。此时对挂掉cache的key可以直接返回 cache miss。
问:从您后面的回答来看,这其实也是“降级”的一种,这样以后是直接把请求打到后端的数据库上么?还是直接抛弃请求?如果发生雪崩效应,miss的请求越来越多,如果miss的都打库的话,库马上就会挂了。这一块老师能再展开讲一讲么?
答:打到数据库上,cache集群的份数和数据库能抗多少读有关。理论上1-2份挂掉,数据库能抗住。58的做法,有一个 backup mc集群,有挂了可以顶上,不建议rehash。高可用的代价是冗余,冗余有成本和复杂性,一致性问题 cache 我文章中***那种 cache 服务集群化,是比较好的方案(配上backup 集群)。
问:服务层到数据层,如果写是通过冗余写入保证高可用,那么根据CAP, 一致性很大可能上是不能保证的。 如何能保证基本一致性的情况的下,保证数据层的高可用?
答:根据CAP理论,一般来说,一致性和可用性取其一,其实最终一致就行。保证了高可用,得牺牲一些一致性,以主从数据库为例,可能在主从数据同步时间窗口内,会从从库读到旧数据。
问:你对时间管理和自我实现有没有什么格外经验,贴之前的文章也行,想学习下。
答:时间管理个人经验,工作时关闭朋友圈、qq、各种群、邮件提醒等,它们是影响效率的主要矛盾。
自我实现?还在努力编码、写文章自我实现中。在百度的一段工作经历让我印象很深刻,周围比我牛逼的同事比我努力,一直努力向他们学习。
问:其实***问题我的意思是,如果不允许 cache miss 的 case 下怎么做rehash且尽可能少脏数据?
答:不允许cache miss,就做cache 高可用,cache高可用也如文章,有几种实现方式。cache 一致性,见《缓存与数据库一致性保证》,这篇文章会对你有帮助。
问:我看了不少的大型网站的构架演进,都是从all in one然后慢慢变成服务化的系统。既然,前人开路,我们后人已经知道最终架构,那能不能一步到达这个服务化的系统?很多人给出不能的理由是一开始就搭建这样的架构成本太高,要先发展业务再治理。但是在我看来,很多东西都可以自动化了,只要几行命令就可以把一整套基础架构搭好了,比如 jenkins 自动化集成+部署、大数据分析平台kafka+spark+zookeeper+Hadoop 等,剩下就是在在这上面写业务应用了及根据业务具体情况调参数了。正因如此,我不是很认同“成本高”这个观点。请问,到底能不能一步到达最终的服务化的系统,跳到中间的演化过程?为什么?也许有人会说了,适合的架构才是好的架构,你业务量现在还达不到,就没必要做成和淘宝,58的架构。我想说,如果搭建和他们类似的架构的成本很低,那我为什么不搭建?简单的说,问题是:能不能跳过大多公司的架构演化过程,直接搭建最终架构?
答:架构设计多想一步,不建议想太远,如果回到10年前58同城重新创业,估计架构还会是当初那个样子,而不是现在一样。
不建议跳过演化,架构是支持业务,不同阶段业务需求不同,架构不同,***架构演化。架构师之路公众号这篇文章《好架构是进化来的》可能会对你有帮助。
问:服务层到数据库读的高可用与服务层到数据库写的高可用 的取舍原则应该遵循哪些方面考虑?想请沈老师的提出一下见解,看看是否给我思考的思路一致?
答:《DB主从一致性架构优化4种方法》这篇文章中有详细的介绍。
问:如何避免服务挂掉之后,rpc client在转移server的时候导致集群中的惊群效应?
答:我的理解,是不存在惊群的,假设原来5个服务10条连接,现在一个服务挂了,变成4个服务8条连接,只要负载分配策略是随机的,流量依然是随机的。
问:58到家在灰度发布和A/B是怎么样的一个落地方案?
答:灰度发布是APP的灰度发布?还是类似推荐算法的AB测,多个算法同时运行?还是服务的平滑升级?对于***个,常见方法是渠道包,越狱包。对于第二个,需要有推荐算法分流平台支持。对于第三个,web/service的升级,间隔重启过程中,要切走流量,保证所有用户不受影响。
以webserver平滑重启为例,一般从nginx层切走一天tomcat的流量,这一台升级站点重启,nginx流量再切回,这么平滑。
问:58是否也做了分中心的建设,中心和中心的内部调用是否是rpc这种方式,又有那些场景是用消息调用,那些用rpc服务,怎么考量的,***有举例?
答: 58没有做多机房架构,《从IDC到云端架构迁移之路》这篇文章,讲了同城机房迁移过程中,一段时间多机房的一些经验。原则是:不能做到完全不跨机房,就减少跨机房,“同连”架构,具体可以看文章。
问: 对于内存计算怎么看,目前redis功能太低级,内存计算同时势必要读取缓存信息,是否可以在内存计算中就把缓存的事情做了,还是缓存就是缓存,只做这一件事情?
答:不太清楚问题是想问什么,mc支持kv,redis支持一些数据结构,还有主从,还支持落地(不建议用),功能我倒是觉得太强大了,cache就是cache,做计算不合适,计算还是业务服务层自己做吧。
问:关于缓存和数据库分布式后,重新分区后的数据迁移是否有好的方案?
答:这篇文章《58怎么玩数据库架构》讲了数据库扩容,一种秒级扩容,一种迁数据扩容(不停服务),或许有帮助。缓存的扩容,可以二倍扩容,如果像我文章中proxy+cache集群的架构,扩容其实对调用方是透明的。
问:你的文章介绍了每个层级和阶段的高可用方案和设计原则,我关心的是有了这些方案和原则设计出来的东西怎么检验,设计检验方案的思路和原则?
答:不是特别理解这个“怎么检验”,高可用上线前完全是可测的。例如nigix层高可用,做keepalived+vip后,干掉一台,测试下能否继续服务。
问:我想了解云环境下数据库高可用怎么做?没有vip怎么做?他们提供的负载,用起来有限制。比如mha不能做到vip漂移。
答:云端两种方式,以阿里云为例。一种ECS+自搭建DB+购买阿里云类似vip的服务,一种用直接用rds高可用数据。印象中阿里云只有主库提供rds高可用,从库貌似不高可用(需要数据库连接池自己实现)。58到家目前使用阿里云,两种方式都有用。
问:使用微服务的方式后如何保证某个服务的版本更新后,对其他各个服务之间的影响能尽可能小?
答:和服务化粒度有关,粒度越粗越耦合,一个地方升级影响其他。粒度越细,越不影响。这篇文章《微服务架构多“微”才合适》对你或许有帮助。
问:架构高可用就是否架构师和运维人员的事情?开发人员有能做和需要注意的?
答:我的理解,不适合存在专职架构师负责架构设计,开发人员负责编码,本身架构就是 技术人 设计的,rd、dba、op等一起,高可用是大家的事情,只是说可能有个经验稍微丰富的研发(暂且叫架构师)牵头来梳理和设计。
问:请问老师分布式系统里面唯一全局ID的生成规则有什么好的方式么?
答:请看这篇文章《细聊分布式ID生成方法》。
问: 从高程转向架构师需要提高那方面的能力,在提高系统设计能力方面有什么建议?
答:这个问题有点泛,这篇文章或许有帮助(非我原创)《互联网架构师必备技能》。
问:假如我之前5个机器能支撑10w用户,突然有一台机器断电了,然后流量分散到其他4台,那么这4台都超过***值了,就会挂了,也就是惊群效应,是否做拒绝策略,具体的落地怎么去做?
答:1)如果流量能抗住,直接分配没问题。2)如果流量超出余下系统负载,要做降级,最简单的方法就是抛弃请求,只为一部分用户提供服务,而不是超出负载直接挂掉,这样所有用户都服务不了=> 服务自身需要做自我保护。
问:类似支付宝750积分这样的灰度,类似运营可以配置策略这种方式来控制不同的人根据不同的策略,接触的服务类型都是不一样,这种的话具体的落地该如何去做呢?
答:这样的灰度,就是不同的用户的界面、功能、算法都不一样的,需要系统支持(开关、流量策略、分流、不同实现),《58同城推荐系统架构设计与实现》这篇文章中“分流”的部分,应该会有帮助。
问:请问web集群中的数据同步,如果涉及跨机房,有什么好的方法尽量避免跨不同区域机房的数据同步和复制中的可靠性,或有其他更好的方法避免跨机房间的数据交互吗?
答:这是多机房的问题,后续在多机房架构的文章中在具体阐述。多机房架构常见三个方案:
1)冷备(强烈不推荐);
2)伪多机房(跨机房读主库数据);
3)多机房多活(入口流量切分+双机房数据同步)。
问:58的服务降级如何做的?
答:不说结合业务的降级(跳过非关键路径),通用的系统层面的降级,常见做法是设置队列,超出负载抛弃请求。这个方案是不好的,当一个上游请求变大,会是的所有上游排队,抛弃请求,都受影响。
58服务治理一般这么做:针对不同调用方,限定流量;一个调用方超量,只抛弃这个调用方的请求,其他调用方不受影响。
末了,希望文章的思路是清晰的,希望大家对高可用的概念和实践有个系统的认识,感谢大家。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】