【51CTO.com快译】GlusterFS可存储网络上的数据,还可以用作云环境下的存储后端。
不久之前,软件定义存储还是各大存储解决方案厂商独占的领域,如今却可以用开源免费软件来加以实施。另一个好处是,你有望获得基于硬件的解决方案所没有的额外功能。GlusterFS让你得以构建一个可扩展、虚拟化的存储池,它由常规存储系统组成(这些存储系统组成网络RAID),并使用不同的方法来定义卷,描述数据如何分布在每个存储系统上。
不管你选择了哪一种类型的卷,GlusterFS都可以利用单个的存储资源构建一个通用的存储阵列,并通过单一命名空间提供给客户(见图1)。客户还可以是使用GlusterFS服务器存储后端用于虚拟系统的应用程序,比如云软件。相比这种类型的其他解决方案,GlusterFS无需专用的元数据服务器在存储池中查找文件。相反使用了一种哈希算法,让任何存储节点得以识别存储池中的文件。这与其他存储解决方案相比是一大优点,因为元数据服务器常常是瓶颈和单一故障点。
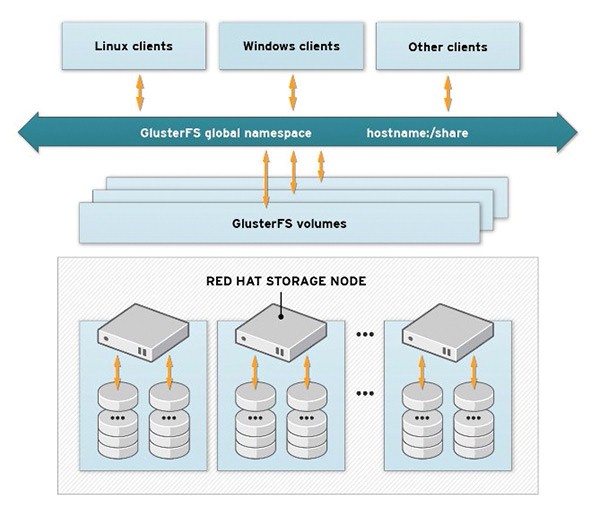
图1:客户系统通过单一命名空间,访问所需的GlusterFS卷
如果你看一下GlusterFS的内部结构,就会惊讶地发现:文件系统实施在用户空间里面,访问通过用户空间中的文件系统(FUSE)接口来进行。这样一来,处理文件系统非常容易、非常灵活,不过代价是性能受到影响。然而,libgfapi库能够直接访问文件系统。比如说,Qemu用它来存储GlusterFS上虚拟系统的映像,没必要经由FUSE挂载来绕行。
如前所述,文件系统是在可分布于多个系统上的卷上创建的。单个系统通过TCP/IP或InfiniBand远程直接内存访问(RDMA)加以连接。然后,通过原生的GlusterFS客户软件、通过网络文件系统(NFS)或服务器消息块(SMB)协议,就可以使用存储卷。除了镜像数据外,GlusterFS还可以使用转换工具,将数据分布到单个存储系统上。
对分布式数据和镜像数据而言,最小的单位是文件本身;以条带化(striping)为列,一个文件的每个部分分布在系统上。这种系统的扩展性良好,如果你需要管理大文件更是如此。这种模式下的性能几乎随着系统的数量呈线性增长。镜像数据时,GlusterFS创建一个文件的多个副本。多种模式的数据还可以结合起来。比如说,结合分布式数据和镜像数据让你可以兼顾性能和数据安全性。
分散模式就好比是一种RAID 5配置,它是比较新的模式。为了获得容错和高可用性,你还可以通过异地复制,将存储卷镜像到远程站点。如果灾难发生,服务器在分布式存储卷方面出现故障,就很容易恢复数据。
Gluster卷还可以加以扩展,可能立即扩展:为此,你只要为卷添加一个额外的brick。用Gluster专业术语来讲,brick是存储系统的目录,卷是由这些目录组成的。单一卷的brick通常但未必驻留在不同的系统上。为了扩大可信赖存储池,你只要为现有的联合体添加额外的服务器。
这里的例子基于Fedora 22,旨在为基于Qemu/KVM和libvirt虚拟化框架的虚拟系统提供后端存储。Glusterfs软件包包含在常规的Fedora软件库中,只要使用dnf软件包管理器就可以安装:
dnf install glusterfs glusterfs-cli glusterfs-server
除了安装GlusterFS社区版外还有一个办法:还可以向Linux发行版经销商红帽公司购买商用Gluster Storage产品。它随带典型的企业功能(比如,你可以访问Linux发行版经销商的支持服务)。
安装GlusterFS
为了避免让例子过于复杂,我的环境包括两个系统。每个系统提供一个brick,它将在两个系统之间复制。在这两个系统上,glusterfs服务都由systemd来启动(代码片段1)。
代码片段1
GlusterFS服务
- # systemctl start glusterd.service
- # systemctl status glusterd.service
- glusterd.service - GlusterFS, a clustered file-system server
- Loaded: loaded (/usr/lib/systemd/system/glusterd.service; disabled; vendor preset: disabled)
- Active: active (running) since Thu 2015-08-27 21:26:45 CEST; 2min 53s ago
- Process: 1424 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid (code=exited, status=0/SUCCESS)
- Main PID: 1425 (glusterd)
- CGroup: /system.slice/glusterd.service ??1425 /usr/sbin/glusterd -p /var/run/glusterd.pid
- Aug 27 21:26:45 gluster2.example.com systemd[1]: Starting GlusterFS, a clustered file-system server...
- Aug 27 21:26:45 gluster2.example.com systemd[1]: Started GlusterFS, a clustered file-system server.
在这两台计算机上,专用的块设备挂载在/storage/下面。之后将用来创建GlusterFS卷的brick在该设备上设置。在这个例子中,每个系统只使用一个brick。然而,如果你之前将所有存储系统添加到前面所述的可信赖存储池,这才有可能实现。登录到哪个存储系统来创建可信赖存储池没有关系。在这个例子中,***个系统(gluster1)用于这个用途:
- # gluster peer probe gluster2
- Probe successful
本地系统自动属于可信赖存储池,它不需要添加上去。来自gluster peer status的输出现在应该会将另一个系统标为两个系统上的peer。下面这个命令在两个存储系统之间生成一个复制卷。在此之后需要启用该卷:
- # gluster volume create gv0 replica gluster1:/storage/brick1/gv0/ gluster2:/storage/brick1/gv0/
- volume create: gv0: success: please start the volume to access data
- # gluster volume start gv0
- volume start: gv0: success
由于传输模式在默认情况下被设成TCP/IP,不需要指定它。如果你偏爱InfiniBand而非TCP/IP,只要在创建卷时指定rdma transport作为进一步的变量。这种方式创建的卷为你提供了额外的功能特性。比如说,你可以允许只从某个特定的网络来访问:
- # gluster volume set gv0 auth.allow 192.168.122.*
- volume set: success
此处(http://www.admin-magazine.com/Articles/Build-storage-pools-with-GlusterFS/(offset)/3#article_i2)大致介绍了所有可用的Gluster选项。安装卷后,你可以输入volume info命令,获得详细信息(见代码片段2)。
代码片段2
获得卷的详细信息
- # gluster volume info gv0
- Volume Name: gv0
- Type: Replicate
- Volume ID: 4f8d25a9-bbee-4e8c-a922-15a7f5a7673d
- Status: Started
- Number of Bricks: 1 x 2 = 2
- Transport-type: tcp
- Bricks:
- Brick1: gluster1:/storage/brick1/gv0
- Brick2: gluster2:/storage/brick1/gv0
- Options Reconfigured:
- auth.allow: 192.168.122.*
使用FUSE实现最快的客户访问
可以使用各种方法,以便最终访问以这种方式创建的卷。经由FUSE的原生访问提供了***性能,你也可以为卷创建一个NFS或SMB共享区,以便通过网络来访问。然而,我建议使用原生客户软件,不仅仅为了获得更好的性能,还因为确保可以透明地访问单个brick,不管用来挂载卷的存储服务器是哪一台。如果你想创建GlusterFS卷,通过NFS-Ganesha或CTDB,配置一台具有高可用性的数据服务器,那么使用NFS或SMB值得关注。如果你按如下方式运行mount命令,就要用到原生客户软件:
- mount -t glusterfs gluster1:/gv0 /mnt/glusterfs/
为了提供***访问卷的服务,往你的etc/fstab文件添加一个相应的行。眼下值得一提的是,使用哪种存储系统来访问无关重要,因为它只是用来读取元数据,元数据表明了你的卷到底是如何组成的。你可以在这里找到为卷提供brick的所有系统。
扩展存储池
GlusterFS让用户很容易调整现有的存储池。比如说,如果你想为存储池添加一个新的存储系统,可以使用下列命令:
- gluster peer probe gluster3
- gluster volume add-brick replica 3 gv0 gluster3:/storage/brick1/gv0/
这里,gluster3系统被添加到存储池,将现有的卷扩大一个brick。调用gluster卷信息应该会证实这一点:现在这个卷已有三个brick。视选择的模式而定,你可能需要为卷添加额外的brick。比如说,分布式复制卷需要四个brick。
你可以从卷删除brick,这个过程就跟添加brick来得一样容易。如果不再需要某个存储系统,可以从可信赖存储池删除它:
- gluster volume remove-brick gv0 gluster3:/storage/brick1/gv0/
- gluster peer detach gluster3
你为分布式卷添加brick或从分布式卷删除brick后,需要重新排序数据,以体现brick数量发生变化的事实。为了启动这个过程,使用这个命令:
- gluster volume rebalance gv0 start
使用参数status而不是start调用这个参数,为你提供了重组进度方面的详细信息。
GlusterFS作为云存储
由于良好性能和易于扩展,GlusterFS经常用作云环境的存储解决方案。既可以部署在纯粹基于libvirt的Qemu/KVM环境,也可以部署在多个KVM实例并行运行的环境。oVirt框架和红帽的商用变种(Enterprise Virtualization)是两个例子。它们提供了这一功能:将Gluster卷用作一段时间的存储池或存储域。Qemu可以直接访问磁盘,没必要经由FUSE挂载绕行,这归功于GlusterFS版本3.4中集成了libgfapi库。性能测试表明,直接访问GlusterFS卷获得了与直接访问brick几乎一样的性能。
下面这个例子表明了如何为基于libvirt的KVM实例提供一个简单的存储池。至此,我假设虚拟机管理程序已安装,只有之前创建的Gluster卷需要连接到该虚拟机管理程序。原则上来说,除了借助命令行工具可以实现外,这还可以借助图形化virt-manager(虚拟机管理器)工具来实现(见图2)。
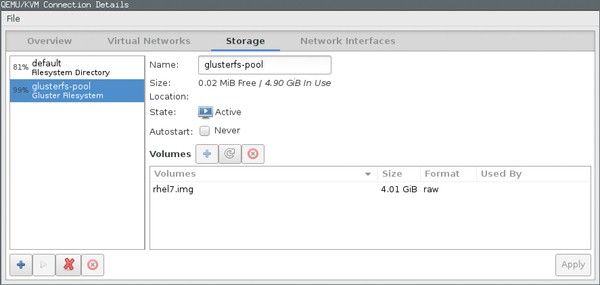
图2:使用virt-manager图形化工具,你可以创建GlusterFS存储池,但眼下,你仍无法创建卷
代码片段3显示了一个XML文件,该文件描述了一个Gluster卷,然后把它添加到libvirt框架。你只要指定单一的存储系统,同时指定配置卷时使用的卷名。下一步,创建一个新的libvirt存储池,并启用它:
- # virsh pool-define /tmp/gluster-storage.xml
- Pool glusterfs-pool defined from /tmp/gluster-storage.xml
- # virsh pool-start glusterfs-pool
- Pool glusterfs-pool started
代码片段3
池定义
- <pool type='gluster'>
- <name>glusterfs-pool</name>
- <source>
- <host name='192.168.122.191'/>
- <dir path='/'/>
- <name>gv0</name>
- </source>
- </pool>
如果这一步行,可以输入virsh pool-list,即可显示本地虚拟机管理程序上的现有存储池的概况信息:
- # virsh pool-list --all
Name State Autostart
------------------------------------------------
default active yes
glusterfs-pool active no
卷可以分配给这个存储池里面的虚拟机。遗憾的是,截至本文截稿时,libvirt并不允许你在GlusterFS池里面创建卷,所以需要手动创建卷(见图2)。下面这个命令在虚拟机管理程序上创建一个4GB大小的卷,用于安装红帽企业级Linux系统:
qemu-img create gluster://192.168.122.191/gv0/rhel7.img 4G
IP地址对应于可信赖存储池里面的***个存储系统,GlusterFS卷之前在该存储池里面创建。virsh vol-list命令显示卷已正确创建:
- # virsh vol-list glusterfs-pool
Name Path
---------------------------------------------------
rhel7.img gluster://192.168.122.191/gv0/rhel7.img
***,你可以使用virt-manager或virt-install命令行工具,创建所需的虚拟系统,并定义刚设置为存储后端的那个卷。在GlusterFS卷上安装虚拟系统的一个很简单的例子看起来就像这样:
- # virt-install --name rhel7 --memory 4096 --disk vol=glusterfs-pool/rhel7.img,bus=virtio --location ftp://192.168.122.1/pub/products/rhel7/
当然,你需要相应修改针对virt-install的调用。这里目的只是显示如何可以把GlusterFS卷用作安装系统的后端。
***,还要注意GlusterFS版本3.3带来了另一个创新,那就是统一文件和对象(UFO)转换工具,它让文件系统能够将POSIX文件处理成对象,反之亦然。在OpenStack环境下,文件系统是内置的OpenStack存储组件Swift的名副其实的替代者,因为它支持所有的OpenStack存储协议(文件、块和对象)。
结束语
GlusterFS可以基于免费软件和商用硬件,构建可横向扩展的存储系统。管理员可以在数据安全和性能之间作一选择,也可以两者兼顾。
原文标题:Build storage pools with GlusterFS,作者:Thorsten Scherf
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】