数据管理比以往更加复杂,到处都是大数据,包括每个人的想法以及不同的形式:广告 , 社交图谱,信息流 ,推荐 ,市场, 健康, 安全, 政府等等。 过去的三年里,成千上万的技术必须处理汇合在一起的大数据获取,管理和分析; 技术选型对IT部门来说是一件艰巨的任务,因为在大多数时间里没有一个综合的方法来用于选型.

当自己面临选择的时候,通常会问如下的问题: 什么时候需要考虑在IT系统中使用大数据? 准备好使用了么? 从哪里开始? 感觉大数据只是一种市场趋势,我还是应该去做么?这些问题萦绕着CIO和CTO们,当决定部署一个全局化分布式大数据架构时,可能会把企业置于危险之中。
定义大数据的表征—换句话说,就是什么时候需要考虑将大数据放入架构。 但是,也指出了各种大数据技术的区别,能够理解在何种情况使用哪种技术。
定义大数据表征
基于不同的需要,可能选择开始大数据项目s: 因为所需处理的数据容量, 因为系统中数据结构的多样性, 因为扩展性问题, 或者因为需要削减数据处理的成本。 本节中,将看到怎样的征兆意味着一个团队需要开始一个大数据项目了。
数据大小哪些事
使人们开始考虑大数据的两个主要领域是何时出现了与数据大小和容量有关的问题。尽管大多数时间这些问题是考虑大数据的合情合理的原因,但今天而已,这并不是唯一的原因。
有其他的表征—例如数据的类型. 如何在传统数据存储中管理不断增加的各种各样的数据类型, 如SQL数据库, 还期望象建表那样的结构化么? 不增加灵活性是不可行的,当出现新的数据结构是需要技术层面的无缝处理。当讨论数据类型是,需要想象非结构化数据,图数据,图片,视频,语音等等。
不但要很好的存储非结构化数据,而且最好是得到一些他们之外的东西。另一表征来自于这一承诺: 大数据也可以从大容量的各种数据中提取增值信息.若干年前,对于大量读多于写的操作,通用的缓存或数据库队友每周的ETL (extract, transform,load) 处理是足够的。如今不再是这样的趋势。现在,需要一个架构具备长时间处理和准实时数据处理的能力。这一架构是分布式的,而不是依赖于高性能且价格高昂的商用机,取而代之的是,高可用,性能驱动和廉价技术所赋予的灵活性。
当下,如何充分利用增值数据以及如何能够原生地搜索到它们呢?为了回答这一问题,再次考虑传统存储中为了加速查询而创建的索引。如果为了复杂查询而索引上百列而且包含了主键的不确定性,会是什么样子?不希望在一个基础SQL 数据库中做这些;取而代之的是,需要考虑按照特殊需要而使用一个 NoSQL存储. 所以,简单回顾一下主要路径:数据获取,结构化,可视化这些真正数据管理的场景,显而易见,数据大小不再是主要的考量因素。
典型的商务使用场景
除了技术和架构考虑,需要面对典型大数据用例的使用场景。它们部分和特殊的工业领域相关; 另外的部分可能适应于各种领域。这些考虑一般都是基于分析应用的日志,例如web访问日志,应用服务器日志,和数据库日志,但是也可以基于各种其他的数据源例如社交网络数据。当面对这些使用场景的时候,如果希望随着商务的增长而弹性扩展,就需要考虑一个分布式的大数据架构。
客户行为分析
感知客户, 或者叫做 “360-度客户视角”可能是最流行的大数据使用场景。客户视角通常用于电子商务网站以及开始于一个非结构化的点击流—换而言之, 由一个访客执行的主动点击和被动的网站导航操作组成。通过计算和分析点击量和面向产品或广告的印象,可以依赖行为而适配访客的用户体验, 目标是得到优化漏斗转换的见解。
情绪分析
公司关注的是其在社交网络上所被感知的形象和声誉; 把可能使他们声名狼藉的负面事件最小化并充分利用正面事件. 通过准实时爬下大量的社交数据,可以提取出社交社区中关于品牌的感受和情绪,从而找到影响用户并练习他们,改变并强化与这些用户的交互。
CRM Onboarding
基于访客的社交行为,可以将客户的行为分析和数据的情感分析结合在一起。公司希望将这些在线数据源和已经存在的离线数据结合在一起,这叫做 CRM (customer relationship management) onboarding, 以便于得到更好和更准确的客户定位. 进而,公司能够充分利用这一定位,从而建立更好的目标系统使市场活动的效益最大化。
预测
从数据中学习在过去几年已经成为主要的大数据趋势。基于大数据的预测在许多业界是非常有效的, 例如电信界, 这里可以预测大众化的路由日志分析. 每一次在设备上发生了问题, 公司可以预测它并避免宕机时间或利润丢失。
当结合以上的使用场景的时候,根据用户的整体行为,可以使用一个预测型架构来诱惑产品目录的选择和价格。
理解大数据技术生态系统
一旦确实要实施一个大数据项目, 最困难的事是架构中的技术选型。这不仅是选择最著名的Hadoop相关技术,而且需要理解如何给它们分类才能构建一个一致性的分布式架构。为了得到大数据星云中的项目数量,可以参见 https://github.com/zenkay/bigdata-ecosystem#projects-1 ,这里有100多个工程项目。这里,可以考虑选择一个Hadoop的发布版,一个分布式文件系统 ,一个类SQL处理语音, 一个机器学习语言, 调度器,面向消息的中间件, NoSQL数据存储,数据可视化等等。
既然是描述构建一个分布式架构的可扩展方法,所以不深入到所有的项目中;取而代之,重点在典型大数据工程中最可能使用的东西。显然,架构的选择和项目的集成依赖于具体的需要,可以看到在特定的领域可以使用这些项目的具体实例。为了使Hadoop 技术表现的更有相关性,这一分布式架构将适用于前面描述的典型场景,命名如下:
- 客户行为分析
- 情绪分析
- CRM onboarding 和预测
Hadoop 发布版
在涵盖了Hadoop 生态系统的大数据项目中,有两个选择:
- 在一个连贯,弹性和一致的架构中分别下载相关项目,然后尝试创建或组装它们
- 使用一个广泛流行的 Hadoop分发版, 已经装配或创建好了这些技术.
尽管选项一完全可行,还是可能选择方案二,因为一个Hadoop 发型包保证了所有安装组件的兼容性,安装,配置部署,监控和支持都非常简单。
Hortonworks 和Cloudera 是这样领域的主角。尽管它们之间有些区别,但是从大数据包的角度上看,它们是一样的,不需要那些专属的插件。我们的目标不是描述每个发布版的所有组件,二是聚焦在每个提供者在标准生态系统中所增加的部分。同时,描述了在每种情况下,该架构所依赖的其他组件。
Cloudera CDH
+ Cloudier在Hadoop基础组件上增加了一个内部机构组件的集合; 这些组件被设计成更好的集群管理和搜索体验。部分组件列表如下:
Impala: 一个实时,并行化,基于SQL的引擎来搜索 HDFS
(Hadoop Distributed File System)和 HBase中的数据. Impala被认为是Hadoop 发布版提供商市场中最快的查询引擎,是UC Bekeley Spark 的直接竞争者。
+ Cloudera Manager: 这是Cloudier的控制台,用来管理和部署Hadoop集群内的Hadoop组件.
+ Hue: 一个用于执行用户交互数据操作和执行脚本的控制台,可以操作集群内不同的Hadoop组件.
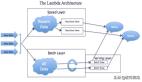
Figure 1-1 解释了Cloudera’s Hadoop分发包有如下组件分类:
+ 橙色部分是Hadoop核心栈.
+ 粉色部分是 Hadoop 生态系统项目
+ 蓝色部分是 Cloudera的特使组件.
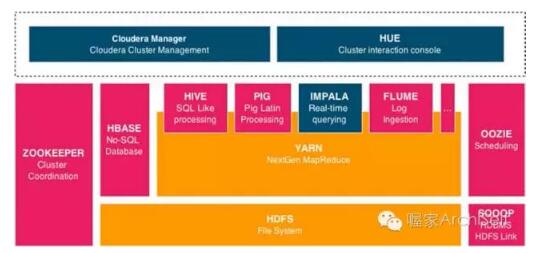
Figure 1-1. Cloudera Hadoop发布版
Hortonworks HDP
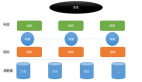
Hortonworks 是一个百分之百的开源而且使用了稳定的组件包,而不是1Hadoop 项目中最新的分发版本。它增加了一个组件管理控制台来与Cloudera Manager对比。Figure 1-2 展示了Hortonworks 发布版与Figure 1-1 相应的分类:绿色部分是Hortonworks的特殊组件.
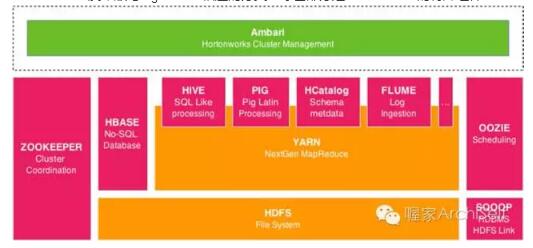
Figure 1-2. Hortonworks Hadoop 发布版
如前所述,当我们构建架构的时候,这两个发布版(Hortonworks 和Cloudera) 是一样的。尽管如此, 如果考虑到每个发布版的成熟度,应当选择; Cloudera Manager比Ambari更完整和稳定 .进一步,考虑实时与大数据集交互,更应该因为它的性能卓越而使用Cloudera.
Hadoop Distributed File System (HDFS)
可能疑虑摄取到Hadoop集群中的数据存储到哪里,一般都在一个专有的系统上,叫做HDFS。HDFS的核心特性:
- 分布式
- 高吞吐量访问
- 高可用
- 容错
- 参数调整
- 安全
- 负载均衡
HDFS 是Hadoop集群中数据存储的头等公民。数据在集群数据节点中自动复制。
Figure 1-3 展示了HDFS中的数据如何在 一个集群的五个节点中复制的。
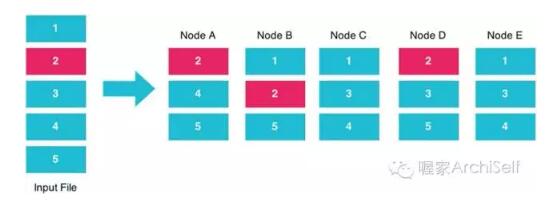
Figure 1-3. HDFS 数据复制
可以从 hadoop.apache.org获得更多的有关HDFS的信息。
Data Acquisition
数据的获取或者摄取开始于不同的数据源,可能是大的日志文件,流数据, ETL处理过的输出,在线的非结构化数据,或者离线的结构化数据。
Apache Flume
当查看生成的摄取日志的时候,强烈推荐使用Apache Flume; 它是稳定且高可用的,提供了一个简单,灵活和基友流数据的可感知编程模型。基本上,仅通过配置管理不需要写一行代码就可以陪着一个数据流水线。
Flume 由sources, channels, 和sinks组成. Flume source 基本上从一个外部数据源来消费一个事件如 Apache Avro source,然后存到channel. channel是一个像文件系统那样的被动存储系统 ; 它在sink 消费事件前一直持有它. sink 消费事件,然后从channel中删除该事件,并分发给一个外部的目标。
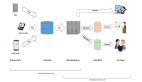
Figure 1-4 描述了一个web server和HDFS间的日志流如 Apache,使用了Flume 流水线.
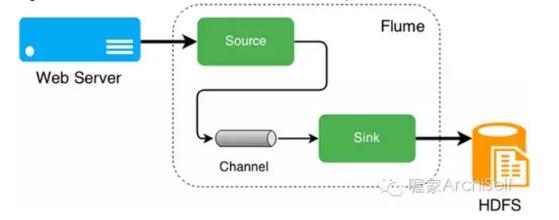
Figure 1-4. Flume 架构
通过 Flume, 可以将web服务器产生的不同日志文件移动到HDFS. 牢记我们工作在一个分布式的架构,可能包含有负载均衡器,HTTP servers,应用服务器,访问日志等等 . 我们是一不同的方式充分利用这些资源,使之能够被Flume流水线处理 . 详情参见 flume.apache.org.
Apache Sqoop
Swoop是一个从结构化数据库传说大量数据到HDFS. 使用它,既可以从一个外部的关系型数据库将数据导入到HDFS, Hive, 或者 HBase, 也可以Hadoop 集群导出到一个关系型数据库或者数据仓库.
Sqoop 支持主流的关系型数据库例如Oracle, MySQL, 和Postgres. 这个项目把你从写脚本传输数据中解脱出来;它提供了高性能数据传输的特性.因为关系型数据库中的数据增长迅速, 最好从开始就定义那些快速增长的表,然后使用Sqoop将数据周期性地传输到Hadoop,以便用于分析.
然后,结合Hadoop与其他数据,可以使用Sqoop 导出数据注入到BI 分析工具中. 详情参见 sqoop.apache.org.
处理语言
一旦数据到了HDFS,可以使用不同的处理语言从原始数据得到最好的结果.
Yarn: NextGen MapReduce
MapReduce 是第一代Hadoop集群中的主要处理框架; 它基本上将滑动数据分组(Map) 在一起,然后依赖特殊的聚合操作(Reduce)来聚会数据。在Hadoop 1.0中, 用户们可以使用不同的语言来写 MapReduce jobs—Java, Python,
Pig, Hive等等. 无论用户选择了什么语言, 都依赖于相同的处理模型:MapReduce.
随着Hadoop 2.0的发布, 有了HDFS之上新的数据处理架构. 现在已经实现了YARN (Yet Another Resource Negotiator), MapReduce 已经成为了众多处理模型中的一个. 这意味着可以依赖特殊的使用场景来采用特殊的处理模型.
Figure 1-5 展示了HDFS, YARN, 和处理模型是如何组织的.
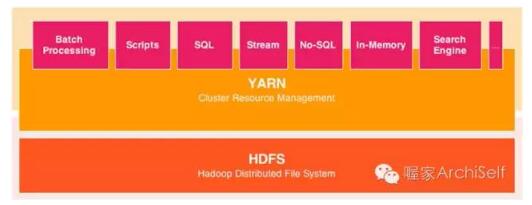
Figure 1-5. YARN 结构
我们无法审视所有的语言和处理模型; 专注于 Hive 和Spark, 它们覆盖了我们所用的用例,长时间数据处理和流处理。
使用Hive的批处理
当决定写第一个批处理job的时候, 使用所喜欢语言实现它,例如Java或 Python,但如果真的要做,最好舒服地使用mapping 和reducing 设计模式, 但这需要开发的时间和复杂的编码,有时候很难去维护。
作为一个替代方式, 可以使用例如Hive这样的高级语言, 以类SQL方式简单而又强大地从HDFS中查询数据. 在用Java写了10行代码的MapReduce地方,在Hive中, 只需要一条 SQL 查询语句.
当使用其他语言而不是原生MapReduce, 其主要的缺陷是性能.在 Hive 和 MapReduce之间有着天然的时延; 另外, SQL查询也与关系型数据库中的查询截然不同。详情参见 hive.apache.org.
Hive 不是一个实时或准实时的处理语言,被用作批处理,例如一个低优先级的长时间处理任务. 处理流式数据,需要使用Spark Streaming.
使用Spark Streaming的流处理
Spark Streaming 可以通过Java, Scale, 或者Python来写批处理任务, 但是可以处理流数据. 这非常适合处理高吞吐量的数据源T例如社交网络(Twitter), 点击流日志, 或者 web 访问日志.
Spark Streaming 是Spark的一个扩展, 它充分利用了分布式数据处理架构,把流式计算作为 一系列不确定的小时间间隔的微型批处理计算。详情参见 spark.apache.org.
Spark Streaming 可以从各种源获得数据,通过与如Apache Kafka这样工具的结合, Spark Streaming 成为强容错和高性能系统的基础。
面向消息的中间件Apache Kafka
Apache Kafka 是一个由Linkedin开发的订阅-发布消息的分布式应用。Kafka经常与 Apache ActiveMQ 或者RabbitMQ对比, 但根本不同是Kafka 没有实现JMS (Java Message Service). 然而, Kafka是一个持久化消息的高吞吐量系统 , 支持队列和话题语意, 使用 ZooKeeper形成集群节点。
Kafka 实现了订阅-发布的企业级集成,支持并行化,以及性能和容错的企业级特性。
Figure 1-6 给出了订阅-发布架构的高层视角,消息在broker传输,服务于分区的话题。
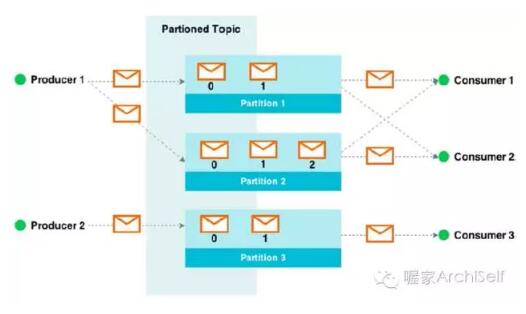
Figure 1-6. Kafka 分区主题示例
使用 Kafka在我们架构中的引导点 ,主要用于接受数据并推送到Spark
Streaming. 详情参见 kafka.apache.org.
机器学习
当我们以无限收敛模型处理小数据采样时,在架构中讨论机器学习还为时尚早。我们是充分利用现有的分层或特殊语言来使用机器学习,例如
Spark中的 Spark MLlib。
Spark MLlib
MLlib是Spark上的机器学习库, 充分利用了 Spark Direct Acyclic Graph (DAG) 执行引擎, 所提供的API 集合方便地集成到Spark中. 它由各种的算法组成 :基本统计, 逻辑回归, k-means 聚类, 从混合高斯到奇异值分解以及多维朴素贝叶斯。
通过 Spark MLlib 这些开箱即用算法,可以用几行代码就能过简单地训练数据并构建预测模型a 详情参见 spark.apache.org/mllib.
NoSQL 存储
NoSQL 存储是数据架构的基础组件,因为它们可以摄取大量数据,提供弹性伸缩,高可用性以及开箱即用。Couchbase 和 ElasticSearch是两种我们聚焦的技术,先做简单讨论,稍后使用它们。
Couchbase
Couchbase是一个面向文档的NoSQL数据库,提供了一个灵活的模型轻松缩放,以及一致性的高性能。使用 Couchbase作为文档数据存储,基本上重定向从前端来的所有查询 到 Couchbase 防止了关系型数据库的高吞吐量读操作。详情参见 couchbase.com.
ElasticSearch
ElasticSearch 是一种非常流行的 NoSQL 技术,拥有可伸缩分布式索引引擎和搜索特性,相当于一般架构中Apache Lucene 加上实时数据分析和全文搜索.
ElasticSearch是ELK平台的一部分( ElasticSearch + Logstash + Kibana,),是由Elastic公司发布的。三个产品结合在一起提供了数据采集,存储和可视化最好的端到端平台:
- Logstash 从各种数据源采集数据,例如社交数据,日志,消息队列,或者传感器,支持数据的丰富性和转换,然后传输到一个索引系统例如ElasticSearch.
- ElasticSearch 在一个弹性伸缩的分布式系统中索引数据,无缝提供了多语言库,很容易在应用中实现实时搜索和分析。
- Kibana 是一个定制化的用户界面,可以构建从简单到复杂的仪表盘,来探索和可视化ElasticSearch 索引的数据。
Figure 1-7 展示了Elastic产品的结构.
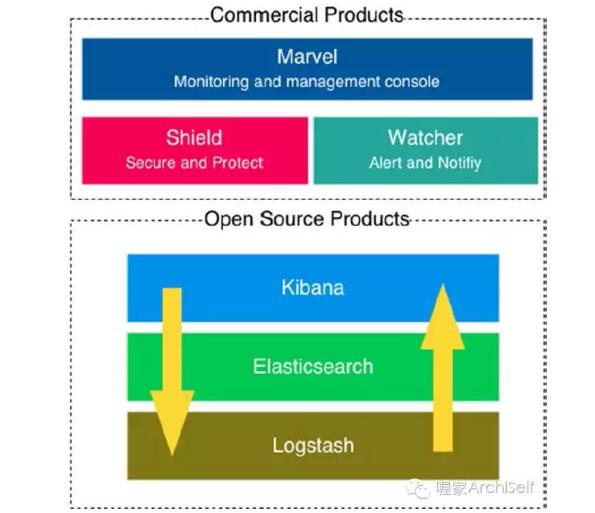
Figure 1-7. ElasticSearch 开源产品
如前图所示, Elastic 也提供了商用产品例如Marvel,基于Kibana的一个监控控制台; Shield, 一个安全框架, 例如提供授权和认证; Watcher, 一个告警和通知系统. 但不使用这些商用产品。我们主要使用ElasticSearch作为搜索引擎来持有Spark产生的产品。在处理和聚合之后,数据在ElasticSearch中被索引,使第三方系统通过ElasticSearch引擎查询数据。另一方面,我们也使用 ELK来处理日志和虚拟化分析,而不只是平台操作视角。详情参见 elastic.co.
创建有长远规划的大数据架构
记住所有这些大数据技术,现在来构建我们的架构。
架构概览
从高层视角来看, 我们的架构看起来象另一个电子商务应用架构,需要如下:
- 一个web应用,访客可以用它导航一个产品目录
- 一个日志摄取应用:拉取日志并处理它们
- 一个机器学习应用:为访客触发推荐
- 一个处理引擎:作为该架构的中央处理集群
- 一个搜索引擎:拉取处理数据的分析
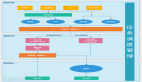
Figure 1-8 展示了这些不同应用如何在该架构组织起来的。
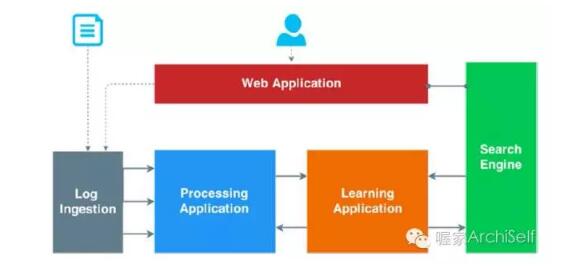
Figure 1-8. 架构概貌
日志摄取
日志摄取应用被用作消费应用日志例如web 访问日志. 为了简化使用场景,提供一个web访问日志,模拟访客浏览产品目录,这些日志代表了点击流日志,既用作长时处理也用作实时推荐。架构有两个选项:第一个是以Flume来传输日志;第二个是以LEK 来创建访问分析。
Figure 1-9 展示了ELK 和Flume是如何处理日志的.
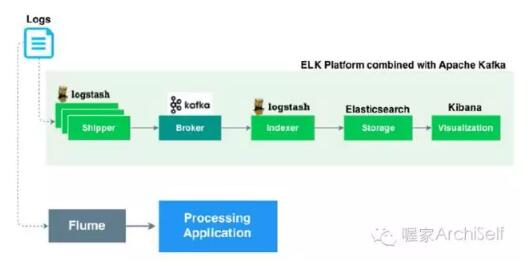
Figure 1-9. 摄取数据
我们在架构中使用ELK ,因为LEK的三个产品无缝集成,能够比使用Flume给我们更多的价值 。
机器学习
机器学习应用接收数据流,构建推荐引擎。这一应用使用一个基本的算法来基于Spark MLlib 介绍 机器学习的概念。
Figure 1-10 展示了该机器学习应用如何使用Kafka 接收数据,然后发送给Spark 处理,最后在ElasticSearch 建立索引为将来使用做准备。
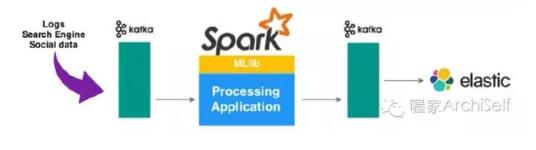
Figure 1-10. 机器学习
处理引擎
处理引擎是该架构的心脏; 它接收各种源的数据,代理合适模型的处理。
Figure 1-11 展示了由Hive组成的处理引擎如何接收数据,以及Spark的实时/准实时处理。
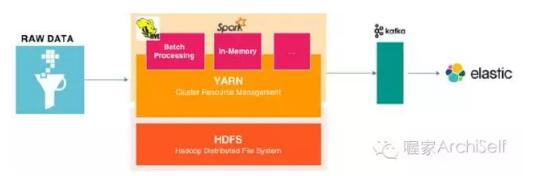
Figure 1-11. Processing engine
这里使用Kafka 与 Logstash结合把数据分发给ElasticSearch. Spark位于 Hadoop 集群的顶端, 但不说必须的。为了简化起见,不建立 Hadoop集群,而是以standalone模式运行Spark。显然,应用同样可以部署在所选择的Hadoop 发布版上。
搜索引擎
搜索引擎充分利用处理引擎所处理的数据,同时暴露出专有的RESTful API以便于分析使用。
【本文来自51CTO专栏作者老曹的原创文章,作者微信公众号:喔家ArchiSelf,id:wrieless-com】