













关系型数据库几乎是许多开发者和DBA对于传统三层架构应用的唯一选择。使用这一场景有很多原因,数据建模方法,查询语言与数据交互,保证数据的一致性部署,并能够为复杂的应用服务。
然而,这不是解决所有数据存储问题的唯一方案,也是NoSQL 产生的原因。NoSQL 提供了新的方法而不是采用面向标准SQL的范式。

NoSQL 技术与高伸缩性无缝融合,很多技术同时具备了高分布性和高性能,是大数据分析的存储基石。大多数时间里,它们使 现有RDBMS 技术所实现的架构更加完整,例如 作为缓存服务器,搜索引擎,非结构化存储,易变信息存储等。主要分为4类:
- Key/value
- 列存储
- 面向文档的存储
- 图存储
现在深入到各种技术,选择最适用于使用场景的技术。
Key/Value
***个也是最早的 NoSQL 数据存储就是key/value. 这些数据就像字典一样根据key来匹配value,通常使用在需要高性能的基本信息存储,例如需要快速读写的session信息,这些存储在这样的情景非常高效,也通常具有高伸缩性。
Key/value也经常被用于上下文的队列化来保证数据不丢失,例如日志架构或搜索引擎的索引架构。Redis 和Riak KV 是非常有名的key/value数据存储; Redis 使用的更加广泛,因为它有着一个内存型 K/V 存储,并且持久化是可选的。Redis 经常用于web应用中来存储session相关的数据,例如node或者-
PHP的 web应用 ; 每秒钟可以提取成千上万的session信息而没有性能损失。另一个典型场景是后面要讲到的序列化:Redis位于 Logstash 和 ElasticSearch 之间来存储t ElasticSearch 查询中的索引。
Column
由于要存储超大量的记录信息 到达了key/value存储限制的时候就需要用到列存储。列存储技术对于RDBMS世界的工程师可能不太容易理解,但事实上非常简单。RDBMS 中数据是按行存储的,而列存储中是按列的。使用列数据库的主要好处是能高速访问海量数据。 RDBMS的一行在硬盘上是一个连续的存储,多行可能存储在硬盘不同的位置,使访问稍显复杂,在列数据库中的一列数据是连续存储的。
举个例子,考虑在RDBMS中查询索引博客的标题,尤其是有数百万数据的时候,需要大量的IO操作,而在列数据库中,这样的查询只是一次访问。这样的数据库在从特定簇提取海量数据中非常顺手,但此消彼长的是缺乏灵活性。使用最多的列存储数据库是
Google Cloud Bigtable, 但开源的列存储数据库是Apache HBase 和Cassandra.
列存储数据库的另一个好处是容易伸缩,这些列在海量存储时具有高伸缩性。这就是为什么它们主要用于保存非易变且长久保留信息的原因。
Document
列存储数据库对于含有比较深嵌套结构的结构化数据的存储不是***的,这种场景需要使用面向文档的数据存储。数据实际上以key/value 存储,但是所有压缩的数据叫做文档。 文档依赖于一个结构或者编码例如XML, 但更多时候是 JSON (JavaScript Object Notation).
尽管文档型数据库对于数据的结构化存储和表达都非常有用,但也有其脆弱的一面,特别是与数据的交互性操作。它们基本上要遍历整个文档,例如当读取某个特定字段的时候,遍历可能会影响性能。
当需要存储嵌套信息的时候,可以采用文档型数据库。例如,考虑怎样表达应用中的一个账户,大概有以下信息:
基础信息:姓名,生日,照片 ,URL, 创建日期等等
复杂信息: 地址,认证方法(password, Facebook, 等第三方认证),兴趣等等。
这也是NoSQL 文档型数据库经常用到web应用的原因: 表达嵌套对象非常容易,由于都使用JSON,还可以与前端的JavaScript技术无缝集成。
使用最多的文档型数据库是MongoDB, Couchbase, 和 Apache CouchDB,都非常容易安装和启动,有很好的文档说明,而且都是可伸缩的,除此之外,它们也是开放现代web应用的明确选择。
Graph
Graph 数据库与其它数据库有着本质的区别。它使用了不同的范式来表达数据——树结构,节点和边连接起来叫做关系。这些数据库是随着社交网络而诞生的,例如表达用户的好友网络,他们的好友关系等等。对于其它类型的数据存储,可能把一个用户的好友关系存储在一个文档中,但是,存储好友关系还依然非常复杂;使用图数据库就非常简单,为每个好友创建节点,通过关系连接他们,依赖查询的需要和范围浏览图。
***的图数据库是Neo4j, 象前面所说的,主要使用场景是处理复杂的关系信息,例如实体间的连接,也可以用于分类的场景。
Figure 2-1 展示了在图数据库中3个实体是如何连接的。
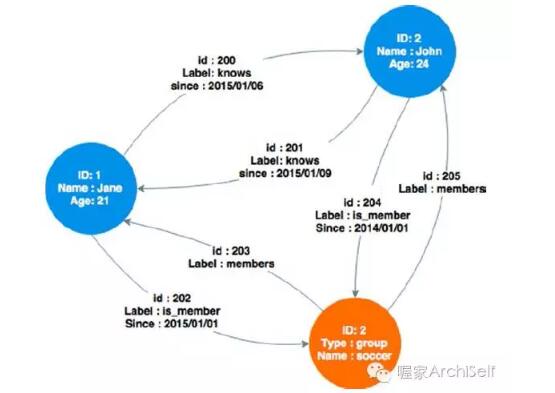
图中的两天账户节点Jane 和 John, 它们之间的每一条边定义了他们的关系,在某天相互认识,另一组节点连接的两个账户展示了Jane 和 Joh在某天后都成为了足球组的成员。
使用场景中的NoSQL
根据使用场景,首先需要一个文档型的 NoSQL数据库,将存储在关系型数据库中的数据结构化的一个 JSON 文档. 如前所述,传统的RDBMSs 将数据存储到多个有关系的表,当得到一个完整对象时变得比较复杂和低效。在Figure 2-2. 中可以看到一个账户被分割成多个表的例子。
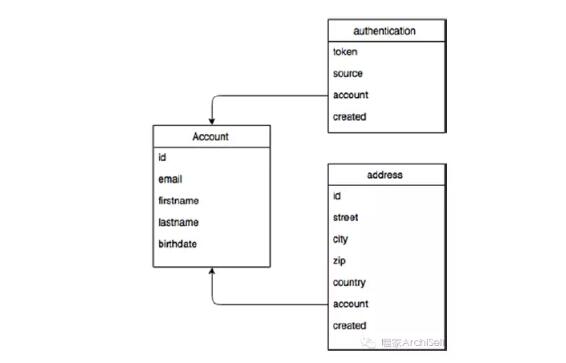
如果要获得所有的账户信息,基本上需要join两到三个表。现在考虑这样的情形: 需要处理所有用户在应用中的每一次连接,这些连接有着不同的商业逻辑。 ***,想要账户自身的视图。通过传递一个账户标识通过API从全部用户视图中得到一个怎样的文档呢?
- { "id": "account_identifier", "email": "account@email.com", "firstname": "account_firstname", "lastname": "account_lastname", "birthdate": "account_birthdate", "authentication": [{ "token": "authentication_token_1", "source": "authenticaton_source_1", "created": "16-12-12" }, { "token": "authentication_token_2", "source": "authenticaton_source_2", "created": "16-12-12" }], "address": [{ "street": "address_street_1", "city": "address_city_1" "zip": "address_zip_1" "country": "address_country_1" "created": "16-12-12" }]}
好处显而易见: 通过保持一个实体的 JSON 表达,可以更快更好的访问数据。进一步,将这一方法通用化,从NoSQL数据库读取所有的读操作,而让所有的写操作 (create, update,delete) 还在RDBMS上 .但必须实现一个逻辑来维持 RDBMS到NoSQL 的数据同步,如果没在缓存中的话还要创建一个关系型数据库的对象。
在NoSQL高效可伸缩地创建文档时为什么还要保持 RDBMS呢?因为这不是应用的真正目的。我不想产生一个Big Bang 的影响. 假设RDBMS已经准备好了,但因为RDBMS缺乏灵活性而集成了一个NoSQL存储。希望充分利用两个***的技术 —— 特别是RDBMS的数据一致性和NoSQL的伸缩性 。
【本文来自51CTO专栏作者老曹的原创文章,作者微信公众号:喔家ArchiSelf,id:wrieless-com】

















