作者| Hal Hodson
策划 | Aileen 魏子敏
编译 | 姜范波 Molly
【导语】人工智能正在进军唇语解读阵地。谷歌DeepMind和牛津大学应用深度学习实验室的一个项目正利用BBC的大量节目数据,创造唇语解读系统,把人类专家远远地甩在身后。
这套系统的训练材料包括约5000小时、6个不同的电视节目,如Newslight,BBC Breakfast 和Question Time。总体而言,视频包含了118,000个句子。
牛津大学和DeepMind的研究人员用2010年1月至2015年12月播出的节目训练了这套系统,并用2016年3月至9月的节目来做测试。
这里是一段没有字幕的剪辑↓↓
同样一段剪辑,但是人工智能系统已经给出了字幕↓↓

人工智能制胜之道
对数据集中随机选择的200个片段,在唇语解读这件事上,人工智能完胜人类专家。
在测试数据集上,人类专家无错误注释的字数仅有12.4%,而人工智能达到46.8%。同时,它犯的许多错误是很小的缺省,如少了一个词尾的“s”。这样的成绩,也完胜其它的自动唇语解读系统。
“这是迈向全自动唇语解读系统的一大步。”芬兰奥卢大学的周子恒(音译)说:“没有那个巨大的数据集,我们无法检验像深度学习这样的新技术。”
两个星期前,一个名为LipNet的类似深度学习系统——同样是牛津大学开发的——在一个名为GRID的数据集上胜过了人类。但是GRID只包含了由51个独立单词组成的词表,而BBC数据集包含了近17,500个独立单词,挑战要大得多。
另外,BBC数据集的语法来自广泛的真实人类语言,而GRID的33,000个句子语法单一,都是同样的模式,预测起来要简单得多。
DeepMind向牛津大学的这个小组表示,他们将开放BBC数据集以供训练用。 来自LipNet的Yannis Assael说,他非常渴望能使用这个数据集。
唇语解读之路
为了让BBC数据集可供自动唇语解读所用,视频片段需先用机器学习进行处理。问题在于,音频流和视频流经常有1秒左右的延迟,这使得人工智能几乎无法在所说的单词和相应的口型之间建立联系。
但是,假设大多数的视频和音频对应完好,一个计算机系统可以学会将声音和口型正确地对应起来。基于这个信息,系统找出那些不匹配的的,将它们重新匹配。这样自动处理了所有的5000小时的视频和音频资料后,唇语解读的挑战就可以开始了——这个挑战对人工而言,是艰巨的。
在此之前,大家已经进行了许多相关的尝试。他们使用卷积神经网络(CNNs)来从静止的图像中预测音位(phoneme)和视位(viseme)。这两个概念分别是声音和图像中可以辨认出来的语言的最小单位。然后人们接着尝试去识别词汇及词组。
大神们使用离散余弦变换(DCT),深度瓶颈特征(DBF)等等手段来进行词汇及词组的预测。总的来讲,此前的研究有两个方面,其一是使用CTC(Connectionist Temporal Classification),这中方法首先在帧的层次上给出预测,然后把输出的字符流按照合适的方式组合起来。这种方法的缺陷是词汇与词汇之间是独立的。另一个方向是训练序列-序列模型。这种方式是读取整个输入序列,然后再进行预测。对这个系统帮助***的就是Chan等人的论文《Vinyals. Listen, attend and spell》。论文中提出了一种很精致的声音到文字的序列-序列方法。
这套唇语识别系统由一套“看-听-同步-写”网络组成。它可以在有声音或没有声音的情况下,通过识别讲话人的面部,输出视频里面讲的句子。在输出向量Y=(y1,y2,...,yl)中,定义每一个输出字符yi都是前面左右字符y<i的条件分布,输出图像序列
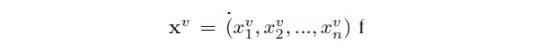
来进行唇语识别,输入音频序列
![]()
进行辅助。这样,模型的输出的概率分布为
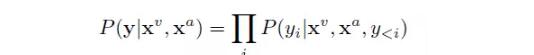
系统由三个主要部分组成:图像编码、音频编码和文字解码。
下图是系统的示意图↓↓
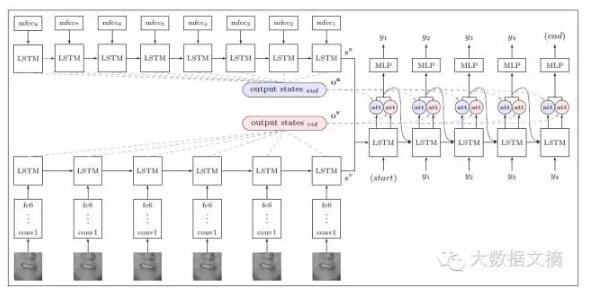
其中,s 为状态向量,o为编码器的输出。***会输出字符序列的概率分布。

这套系统可以应用在许多方面,当然不包括唇语窃听:) 。它可以在嘈杂的环境中,向手机发送文字信息,这样你的siri就可以不必听你讲清楚了。也可以为档案中无声的电影进行配音。还可以处理同时有好多人说话的情况。当然,它还有很多可以改进的空间,比如它的输入是一个视频的完整的唇语动作。但是在实时的视频处理中,它只能获得当前所有的唇语动作,未来的唇语动作显然是无法获得的。
接下来的问题是如何应用人工智能的唇语解读新能力。我们不必担心计算机通过解读唇语来偷听我们的谈话,因为长距离麦克风的偷听能力在多数情况下要好得多。
周子恒认为,唇语解读最有可能用在用户设备上,帮助它们理解人类想要说的。
Assael 说:“我们相信,机器唇语解读器有非常大的应用前景,比如改进助听器,公共场所的无声指令(Siri再也不必听到你的声音了),嘈杂环境下的语音识别等。”
来源:https://www.newscientist.com/article/2113299-googles-deepmind-ai-can-lip-read-tv-shows-better-than-a-pro/
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】