周斌给大家系统介绍了大数据、深度学习、人工智能等前沿技术在腾讯云安全中的应用。
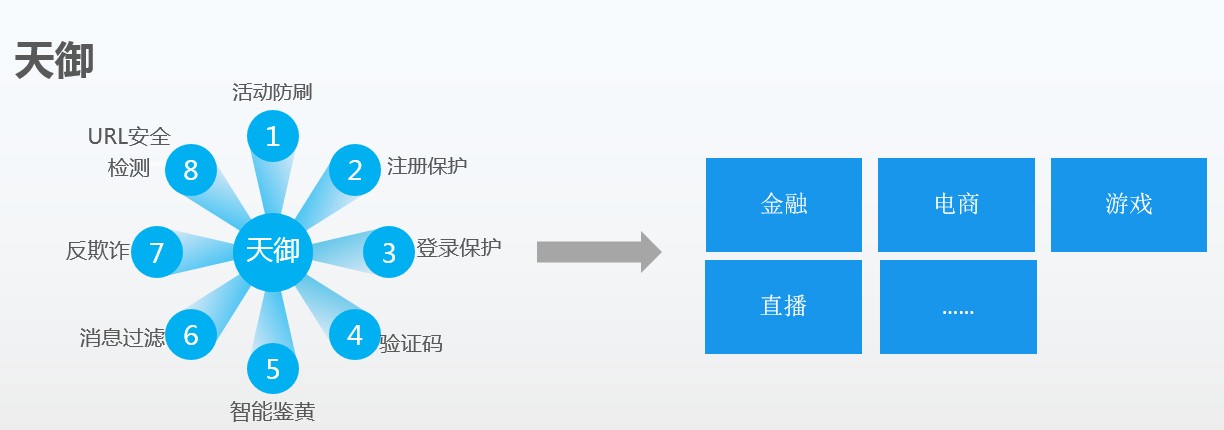
腾讯云的天御业务安全防护系统,正是腾讯云安全在AI实践上的重要体现。基于腾讯内外部每天PB级数据量的安全大数据,天御的AI引擎能够整合所有对抗经验和数据能力,形成多个解决单一安全问题的服务。经过业务中的正向和反向的反馈,天御系统更能够不断优化。目前,天御已为开发者提供包括活动防刷、注册保护、登录保护、消息过滤、图片鉴黄、验证码、反欺诈等服务,帮助京东、滴滴出行、58同城、斗鱼TV等企业保障业务安全。
以下是周斌本次分享的部分节选:
从与黑产的斗争中,腾讯的安全系统从最初的半自动化策略规则集,到基于大数据画像的策略引擎,再到基于深度学习的智能对抗引擎,正一步步实现脱胎换骨的变化。这并非简单的模式变化,它所带来的将是对系统整体架构的全面变革。
数据+算法,腾讯云形成智能的安全引擎
安全系统的数据分析平台,我们会分为4个层次进行,首先是接入层,将所有纬度的数据进行集中,包括从基础网络到业务特征,像网络流量、行为、内容等多个纬度,这样做的原因是所有分类和学习算法,必须要有基础底层数据,越真实越好,这样可以保证机器模型可以精确学习。
其次是引擎和数据层,通过底层的模型,对前期采到的数据进行分类、建模、修正,最后作为结果数据输出到业务场景中。
那么,我们从头来看,海量数据是AI的基础。通过业务数据、风险数据、行业协同数据、以及公共数据,我们构建出构建用于风险识别的智能引擎,引擎区分出正常群体和风险群体。而单个个体通过智能引擎后,最终得出是否风险个体的结论。
算法和模型是深度学习的灵魂。机器学习中,不论是否是深层,最常见的形式是监督学习。监督训练需要依赖于有标签的数据才能进行训练。然而有标签的数据通常是稀缺的,因此对于许多问题,很难获得足够多的样本来训练一个复杂的模型。对于具有强大表达能力的深度网络模型,在不充足的数据上进行训练将会导致过拟合。过拟合简单点说,是指在训练集上可以获得很好的效果,但是在其他数据集上效果就不好甚至非常差。
监督学习的另一个问题是局部最优问题。使用监督学习方法来对浅层网络(只有一个隐藏层)进行训练通常能够使参数收敛到合理的范围内。但是当用这种方法来训练深度网络的时候,并不能取得很好的效果。特别的,使用监督学习方法训练神经网络时,通常会涉及到优化问题。
鉴于监督学习存在的这些问题,两千年中期,使用无监督学习的理念开始兴起。无监督学习不依赖有标签样本,他可以帮助特定的深度网络进行“预训练”。但是这方面的研究还是在进行中。
回到安全上的深度学习模型训练上,有监督学习能否解决问题?我们的回答是:能!
首先,腾讯经过18年的黑产对抗积累,已积累了大规模的标注数据,平台每天处理超过35万亿条实时计算、超过300亿的IM消息、20亿的UGC图片、沉淀下超过400PB存储数据!我们有丰富的恶意语料库、恶意图片库可以用来进行模型训练。但是黑产是在不断演进的,新的恶意形态出现该怎么办?我们采取了两个思路:
第一是在算法上,我们引入多目标优化算法,可以解决样本不足时的过拟合问题;
第二是在半监督深度学习上的尝试,不同于人工全量标注样本,我们只标记关键点样本,再由这些关键点样本进行扩展,最后再拿得到的样本进行训练。
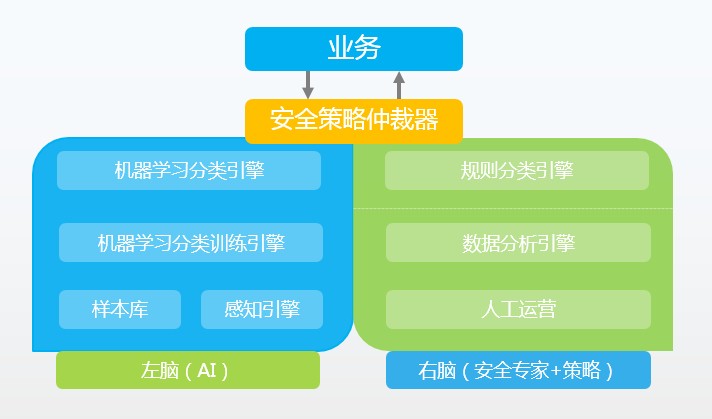
数据+算法,我们形成了智能的安全引擎。左脑进行计算和学习,右脑用专家规则来调整方向。
实际应用中的例子——基于实时挖掘的身份鉴定
众所周知,互联网安全产品中,识别是否真人是否本人是一个关键的基础的问题。很多年前就有这样的一个笑话,你不知道跟你聊天的是只猫还是一只狗。现在我们还得问,你知道跟你聊天的是人还是机器?是人的话是他本人吗?是不是人?这是识别自然人的范畴。是他本人吗?是否有帐号盗用或者共用的可能?在活动防刷、金融反欺诈等领域,身份鉴定都是一个绕不开的问题。来看下我们是怎么做的?首先,我们基于大数据,使用多标签精准刻画建立用户画像。
用户画像涉及的维度有风险画像,包含用户的恶意指数、活跃指数、负反馈指数等。行为序列,用于刻画用户在产品中的行为轨迹。帐号画像,包含用户的社交倾向,比如是否热衷原创、是否乐于分享、是否乐于互动等,帐号画像还有一个重要的维度是行为轨迹,包含用户使用产品的区域倾向和时间段倾向。IP画像,主要包含IP属性和安全标签,我们会记录该IP是否肉鸡IP、作弊IP等,另外还有针对设备的画像等等。
接下来看下我们使用的算法,我们使用的是基于多目标优化的深度学习算法。为什么使用多目标优化?前面我们提到有监督深度学习的两个问题:过拟合与局部最优。我们希望模型精度足够高,同时过拟合情况足够小,传统的方法是将交叉熵(也就是误差),和规范化 (这个是用来衡量是否过拟合的一个量化)进行加权,组成一个最终的目标来训练模型。 多目标优化是同时将误差和规范化作为目标,也就是模型要求同时达到最优。
这样可以全面覆盖搜索空间,最终实现跳出局部最优,避免过拟合。这三张图显示了迭代的过程。横坐标和竖坐标分别表示误差和规范化,构成了搜索空间。通过个体间的信息交换机制,经过若干轮迭代,算法在搜索空间中越过了很多局部最优,得到了较好的结果。就可以根据需要选择其中一个模型应用到生产环境中实施打击。
整个实现过程,我们使用了2TB的画像数据,涉及到380个细分维度,我们使用的底层分析平台保证了身份鉴定整个自学习过程以实时的方式实现。安全策略的精准度至少能达到两个9。
另外一个基于深度学习的应用是色情图片识别,腾讯的色情图片识别依托于腾讯优图的DeepEye主动识别模型,应用在空间、QQ、天御直播鉴黄上,效果在业内处于领先优势。
因为腾讯有着十余年黑产对抗经验,有天然的海量大数据,也有着成功应用于的智能对抗方法,我们能很好地识别自然人和黑产用户,很好地识别垃圾文本、恶意图片,很好地发现更多的恶意模式,我们将这些成熟的业务安全能力开发出来,为互联网金融、电商、游戏、直播提供业务安全解决方案,共享我们的黑产对抗成果。
这也是以SaaS化服务模式,将这些数据和能力整合,在腾讯云上向业界开放了反黑产利器——天御。一年来,天御已经帮助我们大量电商企业应对刷单、金融企业应对诈骗、直播客户鉴黄上发挥了重要作用。今年的一些电商活动中,天御直接拦下了超过80%恶意刷单。