日前,由51CTO传媒精心打造的WOT2016大数据峰会在北京盛大开幕。本次大会议题涵盖实时计算、机器学习、等九大数据领域前沿技术专场,百度大数据平台架构师侯珏、HBase核心贡献者 Ted Yu、一点资讯大数据平台研发总监田超等应邀出席并发表演讲。

一点资讯大数据平台研发总监田超发表演讲
在大会现场,一点资讯大数据总监田超深度透析用户点击反馈背后的系统设计,并以一点资讯实时反馈平台为例,分享了支撑一点资讯亿级别用户实时计算系统的设计理念和心得。
他表示,实时的数据处理能力对于一个现代互联网公司来说是必要的组成部分,一点资讯作为一家融合了“搜索”和“推荐”的兴趣引擎平台,根据不同场景、频道下的点击反馈形成数据矩阵,对数据进行深层次挖掘,并通过大规模实时点击反馈系统和大规模机器学习进行智能推荐,从而为用户提供兼具共性与个性的移动价值阅读,实现了用户体验的提升。
以下是演讲节选:
大家好,很高兴今天与大家分享一点资讯关于大数据技术的一些心得。作为近两年来在移动资讯领域发展最快的公司之一,目前,一点资讯的日活达4800万。此外,我想在这里特别强调的是,一点资讯主动订阅用户数已达4700万。作为一家融合了搜索和推荐的技术驱动资讯平台,与单纯被动根据用户历史记录进行推荐不同,我们更注重自由订阅来给予用户主动表达的出口,通过全网化的智能客户端,不仅为大家带来有趣、有料的新闻,也更提供有用、有品的资讯。
实时点击反馈平台打造***推荐服务
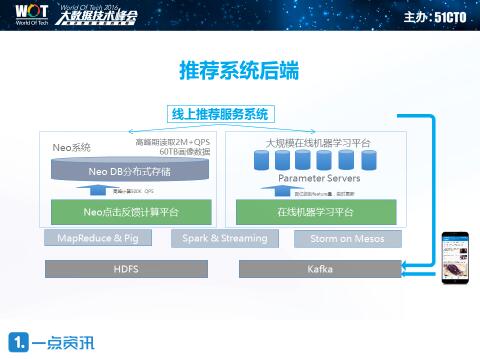
上图是今天我们主要讲的,点击反馈相关推荐的部分。主要包括两个,左手边叫Neo的系统是今天的主题,也就是点击反馈计算平台。
因为这次论坛的主题是实时计算,所以我们也回顾一下整个推荐系统里面实时计算所涉及的三个方面的应用场景:***部分是实时画像中的后验指标,包括了用户画像,内容画像和频道画像等。第二部分,应用场景是我们实时的数据分析,让我们在做不同实验时,了解到不同人群、文章点击率的变化。第三部就是在线的机器学习,后面我会详细介绍。
值得注意的是,虽然推荐服务系统为我们带来很多便利,但同时也面临不少问题和挑战,下面我将从一点资讯的平台为例,为大家分别阐述五个方面的主要问题以及解决方式。
问题1:如何统一各种近似的实时Pipeline
***个问题就是近似的pipeline大家怎么样去统一?做实时计算时,大家常常发现你的Storm、spark跑着各种各样相近但又不同的作业,这些作业中80%运算是相同的。
在一点资讯内部,我们设计了一套叫Neo的点击反馈平台系统,统一了主要的实时点击反馈计算逻辑。Neo系统的核心数据结构是一个Multi-Dimensional Matrix,用以描述用户在各个维度和粒度的兴趣属性和基础属性两部分,可以在不同维度和数据粒度上进行各种聚合运算。其次,我们围绕着核心数据结构构造了整个运行时的framwork,可以支持用户自定义自己的算子。
问题2:实时计算和离线计算的统一
第二个问题说实时计算和离线计算怎么样统一?
实时计算与离线计算的统计是流式计算领域里的研究热点之一,对于我们的生产工作来说也有着比较重要的实际意义,市面上有一些开源和技术和论文包括Spark、SummingBird、Google DataFlow等都对如何实现有自己的解决方案。一点资讯采用的是Lambda architecture,对于核心计算逻辑有一套统一的数据结构抽象和计算算子抽象。我们本质上处理的是事件流在不同矩阵上以不同粒度聚合的问题,这里尤其是对于矩阵的Delta和Base之间的计算,我们给出了一套比较完整的抽象。这一套核心代码可以同时跑在Storm/JStorm, Spark、Mapeduce上。
问题3:数据变化如何追踪与Debug
我们的平台除了考虑到了上面所述的数据结构和计算模型外,还考虑到了时间的因素。时间是一个非常重要的维度,对于我们的计算引擎也是一个挑战。总结来说,包括这几个问题:不同类型的Feature需要不同的淘汰策略,需要能够计算各种时间周期上的feature、需要能够知道数据历史变化的状态、数据分析需要追踪指标变化曲线。
对于这些问题,我们构建了比较完整的windowingmodol的实时计算模型:在hbase上存储细粒度的delta数据,这一部分的数据是实时更新的,每次更新时计算pipeline会通过kafka写入一个WAL,有一个Pusher组件会监听这个WAL,并可以根据自定义的策略对不同的数据表采用不同的window计算模型;在pusher层面,支持各种时间窗口淘汰策略,包括Fixedwindow,session window,slidingwindow,decay,last value win等,
问题4:高性能存储引擎
一点资讯在高峰期产生的2M+QPS的读请求,和200K+的更新量,因此对我们线上的分布式存储系统会有比较高的性能要求,市面上线程的分布式存储方案都不能解决我们面临的问题。
因此我们开发了自己的分布式存储系统NeoDB,底层基于Rocksdb,上层使用ThriftRPC,我们对系统层次做了很多的优化,,包括把一些部分计算可以推到***下节点上、减少Compaction的层次,控制Compaction对于读请求的影响、控制写放大,优化缓存***率等。
问题5:如何监控和维护整个系统
***一个问题怎么样做监控和维护整个系统。这里面涉及到一些问题,主要包括怎么对数据流lag做监控报警。对流式计算如何做profiling,线上如何做负载均衡等。我们针对这些问题开发了两个系统,一个是监控我们做了YMetric的监控系统。客户端兼容codahale metrics库,会将metric汇总发送到Kafka中,并由我们统一的Storm Pipeline进行聚合计算,结果存储在openTSDB之中。我们的这套系统支持多Metric的自定义计算、报警、Trending预测等。
另外一个系统是ycluster服务,她有点像Apache Helix,但是我们做的更为简单易用,YCluster是一套基于Zookeeper的分布式负载均衡和机群管理系统,支持Multiple Service Namespace、Hash Sharding、Multiple Replica。同时我们基于YCluster做了Neo系统的Smart Client,通过这套Smart Client完成路由和负载均衡的工作,我们支持多种不同负载均衡的算法,包括简单的Random和Round-Robin、,同时我们做了一个叫做link Scheduler的负载均衡的算法,可以支持多数据中心中的本地优先调度,并支持相同副本的优先调度,从而大幅度提升了缓存***率。
我们这套东西大概线上跑了一年多了不到两年,目前承担了一点资讯一直以来快速服务的增长,这里面就是今天我跟大家介绍的东西,另外补充一点是说,我们也欢迎对一点资讯感兴趣的同学加入进来。