首先所有核心组件都会实现org.apache.flume.lifecycle.LifecycleAware接口:
Java代码
- public interface LifecycleAware {
- public void start();
- public void stop();
- public LifecycleState getLifecycleState();
- }
start方法在整个Flume启动时或者初始化组件时都会调用start方法进行组件初始化,Flume组件出现异常停止时会调用stop,getLifecycleState返回组件的生命周期状态,有IDLE, START, STOP, ERROR四个状态。
如果开发的组件需要配置,如设置一些属性;可以实现org.apache.flume.conf.Configurable接口:
Java代码
- public interface Configurable {
- public void configure(Context context);
- }
Flume在启动组件之前会调用configure来初始化组件一些配置。
1、Source
Source用于采集日志数据,有两种实现方式:轮训拉取和事件驱动机制;Source接口如下:
Java代码
- public interface Source extends LifecycleAware, NamedComponent {
- public void setChannelProcessor(ChannelProcessor channelProcessor);
- public ChannelProcessor getChannelProcessor();
- }
Source接口首先继承了LifecycleAware接口,然后只提供了ChannelProcessor的setter和getter接口,也就是说它的的所有逻辑的实现应该在LifecycleAware接口的start和stop中实现;ChannelProcessor之前介绍过用来进行日志流的过滤和Channel的选择及调度。
而Source是通过SourceFactory工厂创建,默认提供了DefaultSourceFactory,其首先通过Enum类型org.apache.flume.conf.source.SourceType查找默认实现,如exec,则找到org.apache.flume.source.ExecSource实现,如果找不到直接Class.forName(className)创建。
Source提供了两种机制: PollableSource(轮训拉取)和EventDrivenSource(事件驱动):
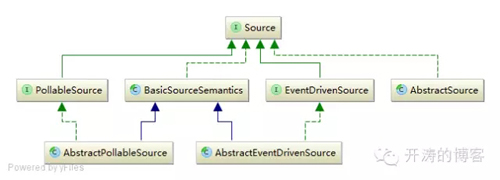
PollableSource默认提供了如下实现:
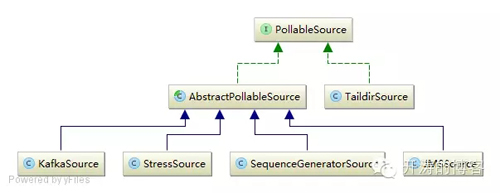
比如JMSSource实现使用javax.jms.MessageConsumer.receive(pollTimeout)主动去拉取消息。
EventDrivenSource默认提供了如下实现:

比如NetcatSource、HttpSource就是事件驱动,即被动等待;比如HttpSource就是内部启动了一个内嵌的Jetty启动了一个Servlet容器,通过FlumeHTTPServlet去接收消息。
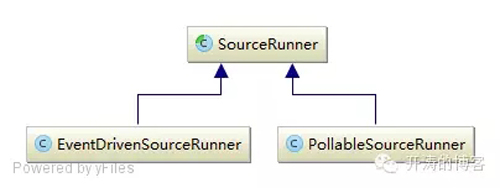
Flume提供了SourceRunner用来启动Source的流转:
Java代码
- public class EventDrivenSourceRunner extends SourceRunner {
- private LifecycleState lifecycleState;
- public EventDrivenSourceRunner() {
- lifecycleState = LifecycleState.IDLE; //启动之前是空闲状态
- }
- @Override
- public void start() {
- Source source = getSource(); //获取Source
- ChannelProcessor cp = source.getChannelProcessor(); //Channel处理器
- cp.initialize(); //初始化Channel处理器
- source.start(); //启动Source
- lifecycleState = LifecycleState.START; //本组件状态改成启动状态
- }
- @Override
- public void stop() {
- Source source = getSource(); //先停Source
- source.stop();
- ChannelProcessor cp = source.getChannelProcessor();
- cp.close();//再停Channel处理器
- lifecycleState = LifecycleState.STOP; //本组件状态改成停止状态
- }
- }
从本组件也可以看出:1、首先要初始化ChannelProcessor,其实现时初始化过滤器链;2、接着启动Source并更改本组件的状态。
Java代码
- public class PollableSourceRunner extends SourceRunner {
- @Override
- public void start() {
- PollableSource source = (PollableSource) getSource();
- ChannelProcessor cp = source.getChannelProcessor();
- cp.initialize();
- source.start();
- runner = new PollingRunner();
- runner.source = source;
- runner.counterGroup = counterGroup;
- runner.shouldStop = shouldStop;
- runnerThread = new Thread(runner);
- runnerThread.setName(getClass().getSimpleName() + "-" +
- source.getClass().getSimpleName() + "-" + source.getName());
- runnerThread.start();
- lifecycleState = LifecycleState.START;
- }
- }
而PollingRunner首先初始化组件,但是又启动了一个线程PollingRunner,其作用就是轮训拉取数据:
Java代码
- @Override
- public void run() {
- while (!shouldStop.get()) { //如果没有停止,则一直在死循环运行
- counterGroup.incrementAndGet("runner.polls");
- try {
- //调用PollableSource的process方法进行轮训拉取,然后判断是否遇到了失败补偿
- if (source.process().equals(PollableSource.Status.BACKOFF)) {/
- counterGroup.incrementAndGet("runner.backoffs");
- //失败补偿时暂停线程处理,等待超时时间之后重试
- Thread.sleep(Math.min(
- counterGroup.incrementAndGet("runner.backoffs.consecutive")
- * source.getBackOffSleepIncrement(), source.getMaxBackOffSleepInterval()));
- } else {
- counterGroup.set("runner.backoffs.consecutive", 0L);
- }
- } catch (InterruptedException e) {
- }
- }
- }
- }
- }
Flume在启动时会判断Source是PollableSource还是EventDrivenSource来选择使用PollableSourceRunner还是EventDrivenSourceRunner。
比如HttpSource实现,其通过FlumeHTTPServlet接收消息然后:
Java代码
- List<Event> events = Collections.emptyList(); //create empty list
- //首先从请求中获取Event
- events = handler.getEvents(request);
- //然后交给ChannelProcessor进行处理
- getChannelProcessor().processEventBatch(events);
到此基本的Source流程就介绍完了,其作用就是监听日志,采集,然后交给ChannelProcessor进行处理。
2、Channel
Channel用于连接Source和Sink,Source生产日志发送到Channel,Sink从Channel消费日志;也就是说通过Channel实现了Source和Sink的解耦,可以实现多对多的关联,和Source、Sink的异步化。
之前Source采集到日志后会交给ChannelProcessor处理,那么接下来我们先从ChannelProcessor入手,其依赖三个组件:
Java代码
- private final ChannelSelector selector; //Channel选择器
- private final InterceptorChain interceptorChain; //拦截器链
- private ExecutorService execService; //用于实现可选Channel的ExecutorService,默认是单线程实现
接下来看下其是如何处理Event的:
Java代码
- public void processEvent(Event event) {
- event = interceptorChain.intercept(event); //首先进行拦截器链过滤
- if (event == null) {
- return;
- }
- List<Event> events = new ArrayList<Event>(1);
- events.add(event);
- //通过Channel选择器获取必须成功处理的Channel,然后事务中执行
- List<Channel> requiredChannels = selector.getRequiredChannels(event);
- for (Channel reqChannel : requiredChannels) {
- executeChannelTransaction(reqChannel, events, false);
- }
- //通过Channel选择器获取可选的Channel,这些Channel失败是可以忽略,不影响其他Channel的处理
- List<Channel> optionalChannels = selector.getOptionalChannels(event);
- for (Channel optChannel : optionalChannels) {
- execService.submit(new OptionalChannelTransactionRunnable(optChannel, events));
- }
- }
另外内部还提供了批处理实现方法processEventBatch;对于内部事务实现的话可以参考executeChannelTransaction方法,整体事务机制类似于JDBC:
Java代码
- private static void executeChannelTransaction(Channel channel, List<Event> batch, boolean isOptional) {
- //1、获取Channel上的事务
- Transaction tx = channel.getTransaction();
- Preconditions.checkNotNull(tx, "Transaction object must not be null");
- try {
- //2、开启事务
- tx.begin();
- //3、在Channel上执行批量put操作
- for (Event event : batch) {
- channel.put(event);
- }
- //4、成功后提交事务
- tx.commit();
- } catch (Throwable t) {
- //5、异常后回滚事务
- tx.rollback();
- if (t instanceof Error) {
- LOG.error("Error while writing to channel: " +
- channel, t);
- throw (Error) t;
- } else if(!isOptional) {//如果是可选的Channel,异常忽略
- throw new ChannelException("Unable to put batch on required " +
- "channel: " + channel, t);
- }
- } finally {
- //***关闭事务
- tx.close();
- }
- }
Interceptor用于过滤Event,即传入一个Event然后进行过滤加工,然后返回一个新的Event,接口如下:
Java代码
- public interface Interceptor {
- public void initialize();
- public Event intercept(Event event);
- public List<Event> intercept(List<Event> events);
- public void close();
- }
可以看到其提供了initialize和close方法用于启动和关闭;intercept方法用于过滤或加工Event。比如HostInterceptor拦截器用于获取本机IP然后默认添加到Event的字段为host的Header中。
接下来就是ChannelSelector选择器了,其通过如下方式创建:
Java代码
- //获取ChannelSelector配置,比如agent.sources.s1.selector.type = replicating
- ChannelSelectorConfiguration selectorConfig = config.getSelectorConfiguration();
- //使用Source关联的Channel创建,比如agent.sources.s1.channels = c1 c2
- ChannelSelector selector = ChannelSelectorFactory.create(sourceChannels, selectorConfig);
ChannelSelector默认提供了两种实现:复制和多路复用:
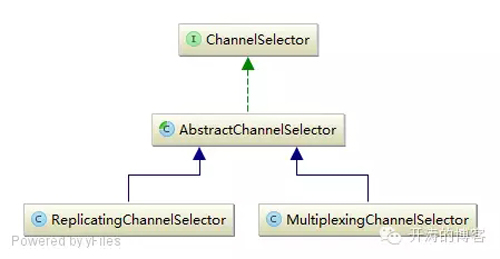
默认实现是复制选择器ReplicatingChannelSelector,即把接收到的消息复制到每一个Channel;多路复用选择器MultiplexingChannelSelector会根据Event Header中的参数进行选择,以此来选择使用哪个Channel。
而Channel是Event中转的地方,Source发布Event到Channel,Sink消费Channel的Event;Channel接口提供了如下接口用来实现Event流转:
Java代码
- public interface Channel extends LifecycleAware, NamedComponent {
- public void put(Event event) throws ChannelException;
- public Event take() throws ChannelException;
- public Transaction getTransaction();
- }
put用于发布Event,take用于消费Event,getTransaction用于事务支持。默认提供了如下Channel的实现:
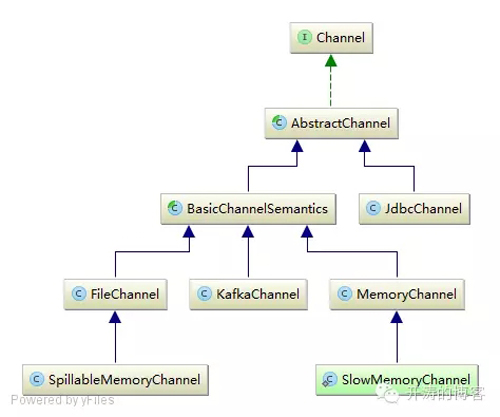
对于Channel的实现我们后续单独章节介绍。
3、Sink
Sink从Channel消费Event,然后进行转移到收集/聚合层或存储层。Sink接口如下所示:
Java代码
- public interface Sink extends LifecycleAware, NamedComponent {
- public void setChannel(Channel channel);
- public Channel getChannel();
- public Status process() throws EventDeliveryException;
- public static enum Status {
- READY, BACKOFF
- }
- }
类似于Source,其首先继承了LifecycleAware,然后提供了Channel的getter/setter方法,并提供了process方法进行消费,此方法会返回消费的状态,READY或BACKOFF。
Sink也是通过SinkFactory工厂来创建,其也提供了DefaultSinkFactory默认工厂,比如传入hdfs,会先查找Enum org.apache.flume.conf.sink.SinkType,然后找到相应的默认处理类org.apache.flume.sink.hdfs.HDFSEventSink,如果没找到默认处理类,直接通过Class.forName(className)进行反射创建。
我们知道Sink还提供了分组功能,用于把多个Sink聚合为一组进行使用,内部提供了SinkGroup用来完成这个事情。此时问题来了,如何去调度多个Sink,其内部使用了SinkProcessor来完成这个事情,默认提供了故障转移和负载均衡两个策略。
首先SinkGroup就是聚合多个Sink为一组,然后将多个Sink传给SinkProcessorFactory进行创建SinkProcessor,而策略是根据配置文件中配置的如agent.sinkgroups.g1.processor.type = load_balance来选择的。
SinkProcessor提供了如下实现:
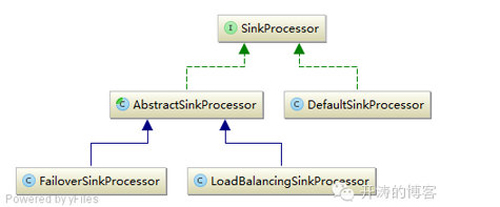
DefaultSinkProcessor:默认实现,用于单个Sink的场景使用。
FailoverSinkProcessor:故障转移实现:
Java代码
- public Status process() throws EventDeliveryException {
- Long now = System.currentTimeMillis();
- //1、首先检查失败队列的头部的Sink是否已经过了失败补偿等待时间了
- while(!failedSinks.isEmpty() && failedSinks.peek().getRefresh() < now) {
- //2、如果可以使用了,则从失败Sink队列获取队列***个Sink
- FailedSink cur = failedSinks.poll();
- Status s;
- try {
- s = cur.getSink().process(); //3、使用此Sink进行处理
- if (s == Status.READY) { //4、如果处理成功
- liveSinks.put(cur.getPriority(), cur.getSink()); //4.1、放回存活Sink队列
- activeSink = liveSinks.get(liveSinks.lastKey());
- } else {
- failedSinks.add(cur); //4.2、如果此时不是READY,即BACKOFF期间,再次放回失败队列
- }
- return s;
- } catch (Exception e) {
- cur.incFails(); //5、如果遇到异常了,则增加失败次数,并放回失败队列
- failedSinks.add(cur);
- }
- }
- Status ret = null;
- while(activeSink != null) { //6、此时失败队列中没有Sink能处理了,那么需要使用存活Sink队列进行处理
- try {
- ret = activeSink.process();
- return ret;
- } catch (Exception e) { //7、处理失败进行转移到失败队列
- activeSink = moveActiveToDeadAndGetNext();
- }
- }
- throw new EventDeliveryException("All sinks failed to process, " +
- "nothing left to failover to");
- }
失败队列是一个优先级队列,使用refresh属性排序,而refresh是通过如下机制计算的:
Java代码
- refresh = System.currentTimeMillis()
- + Math.min(maxPenalty, (1 << sequentialFailures) * FAILURE_PENALTY);
其中maxPenalty是***等待时间,默认30s,而(1 << sequentialFailures) * FAILURE_PENALTY)用于实现指数级等待时间递增, FAILURE_PENALTY是1s。
LoadBalanceSinkProcessor:用于实现Sink的负载均衡,其通过SinkSelector进行实现,类似于ChannelSelector。LoadBalanceSinkProcessor在启动时会根据配置,如agent.sinkgroups.g1.processor.selector = random进行选择,默认提供了两种选择器:
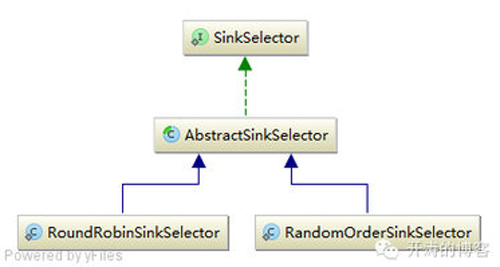
LoadBalanceSinkProcessor使用如下机制进行负载均衡:
Java代码
- public Status process() throws EventDeliveryException {
- Status status = null;
- //1、使用选择器创建相应的迭代器,也就是用来选择Sink的迭代器
- Iterator<Sink> sinkIterator = selector.createSinkIterator();
- while (sinkIterator.hasNext()) {
- Sink sink = sinkIterator.next();
- try {
- //2、选择器迭代Sink进行处理,如果成功直接break掉这次处理,此次负载均衡就算完成了
- status = sink.process();
- break;
- } catch (Exception ex) {
- //3、失败后会通知选择器,采取相应的失败退避补偿算法进行处理
- selector.informSinkFailed(sink);
- LOGGER.warn("Sink failed to consume event. "
- + "Attempting next sink if available.", ex);
- }
- }
- if (status == null) {
- throw new EventDeliveryException("All configured sinks have failed");
- }
- return status;
- }
如上的核心就是怎么创建迭代器,如何进行失败退避补偿处理,首先我们看下RoundRobinSinkSelector实现,其内部是通过通用的RoundRobinOrderSelector选择器实现:
Java代码
- public Iterator<T> createIterator() {
- //1、获取存活的Sink索引,
- List<Integer> activeIndices = getIndexList();
- int size = activeIndices.size();
- //2、如果上次记录的下一个存活Sink的位置超过了size,那么从队列头重新开始计数
- if (nextHead >= size) {
- nextHead = 0;
- }
- //3、获取本次使用的起始位置
- int begin = nextHead++;
- if (nextHead == activeIndices.size()) {
- nextHead = 0;
- }
- //4、从该位置开始迭代,其实现类似于环形队列,比如整个队列是5,起始位置是3,则按照 3、4、0、1、2的顺序进行轮训,实现了轮训算法
- int[] indexOrder = new int[size];
- for (int i = 0; i < size; i++) {
- indexOrder[i] = activeIndices.get((begin + i) % size);
- }
- //indexOrder是迭代顺序,getObjects返回相关的Sinks;
- return new SpecificOrderIterator<T>(indexOrder, getObjects());
- }
getIndexList实现如下:
Java代码
- protected List<Integer> getIndexList() {
- long now = System.currentTimeMillis();
- List<Integer> indexList = new ArrayList<Integer>();
- int i = 0;
- for (T obj : stateMap.keySet()) {
- if (!isShouldBackOff() || stateMap.get(obj).restoreTime < now) {
- indexList.add(i);
- }
- i++;
- }
- return indexList;
- }
isShouldBackOff()表示是否开启退避算法支持,如果不开启,则认为每个Sink都是存活的,每次都会重试,通过agent.sinkgroups.g1.processor.backoff = true配置开启,默认false;restoreTime和之前介绍的refresh一样,是退避补偿等待时间,算法类似,就不多介绍了。
那么什么时候调用Sink进行消费呢?其类似于SourceRunner,Sink提供了SinkRunner进行轮训拉取处理,SinkRunner会轮训调度SinkProcessor消费Channel的消息,然后调用Sink进行转移。SinkProcessor之前介绍过,其负责消息复制/路由。
SinkRunner实现如下:
Java代码
- public void start() {
- SinkProcessor policy = getPolicy();
- policy.start();
- runner = new PollingRunner();
- runner.policy = policy;
- runner.counterGroup = counterGroup;
- runner.shouldStop = new AtomicBoolean();
- runnerThread = new Thread(runner);
- runnerThread.setName("SinkRunner-PollingRunner-" +
- policy.getClass().getSimpleName());
- runnerThread.start();
- lifecycleState = LifecycleState.START;
- }
即获取SinkProcessor然后启动它,接着启动轮训线程去处理。PollingRunner线程负责轮训消息,核心实现如下:
Java代码
- public void run() {
- while (!shouldStop.get()) { //如果没有停止
- try {
- if (policy.process().equals(Sink.Status.BACKOFF)) {//如果处理失败了,进行退避补偿处理
- counterGroup.incrementAndGet("runner.backoffs");
- Thread.sleep(Math.min(
- counterGroup.incrementAndGet("runner.backoffs.consecutive")
- * backoffSleepIncrement, maxBackoffSleep)); //暂停退避补偿设定的超时时间
- } else {
- counterGroup.set("runner.backoffs.consecutive", 0L);
- }
- } catch (Exception e) {
- try {
- Thread.sleep(maxBackoffSleep); //如果遇到异常则等待***退避时间
- } catch (InterruptedException ex) {
- Thread.currentThread().interrupt();
- }
- }
- }
- }
整体实现类似于PollableSourceRunner实现,整体处理都是交给SinkProcessor完成的。SinkProcessor会轮训Sink的process方法进行处理;此处以LoggerSink为例:
Java代码
- @Override
- public Status process() throws EventDeliveryException {
- Status result = Status.READY;
- Channel channel = getChannel();
- //1、获取事务
- Transaction transaction = channel.getTransaction();
- Event event = null;
- try {
- //2、开启事务
- transaction.begin();
- //3、从Channel获取Event
- event = channel.take();
- if (event != null) {
- if (logger.isInfoEnabled()) {
- logger.info("Event: " + EventHelper.dumpEvent(event, maxBytesToLog));
- }
- } else {//4、如果Channel中没有Event,则默认进入故障补偿机制,即防止死循环造成CPU负载高
- result = Status.BACKOFF;
- }
- //5、成功后提交事务
- transaction.commit();
- } catch (Exception ex) {
- //6、失败后回滚事务
- transaction.rollback();
- throw new EventDeliveryException("Failed to log event: " + event, ex);
- } finally {
- //7、关闭事务
- transaction.close();
- }
- return result;
- }
Sink中一些实现是支持批处理的,比如RollingFileSink:
Java代码
- //1、开启事务
- //2、批处理
- for (int i = 0; i < batchSize; i++) {
- event = channel.take();
- if (event != null) {
- sinkCounter.incrementEventDrainAttemptCount();
- eventAttemptCounter++;
- serializer.write(event);
- }
- }
- //3、提交/回滚事务、关闭事务
定义一个批处理大小然后在事务中执行批处理。
【本文是51CTO专栏作者张开涛的原创文章,作者微信公众号:开涛的博客,id:kaitao-1234567】