最近在学习Flume源码,所以想写一份Flume源码学习的笔记供需要的朋友一起学习参考。
1、Flume介绍
Flume是cloudera公司开源的一款分布式、可靠地进行大量日志数据采集、聚合和并转移到存储中;通过事务机制提供了可靠的消息传输支持,自带负载均衡机制来支撑水平扩展;并且提供了一些默认组件供直接使用。
Flume目前常见的应用场景:日志--->Flume--->实时计算(如Kafka+Storm) 、日志--->Flume--->离线计算(如HDFS、HBase)、日志--->Flume--->ElasticSearch。
2、整体架构
Flume主要分为三个组件:Source、Channel、Sink;数据流如下图所示:
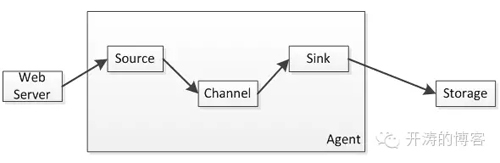
1、Source负责日志流入,比如从文件、网络、Kafka等数据源流入数据,数据流入的方式有两种轮训拉取和事件驱动;
2、Channel负责数据聚合/暂存,比如暂存到内存、本地文件、数据库、Kafka等,日志数据不会在管道停留很长时间,很快会被Sink消费掉;
3、Sink负责数据转移到存储,比如从Channel拿到日志后直接存储到HDFS、HBase、Kafka、ElasticSearch等,然后再有如Hadoop、Storm、ElasticSearch之类的进行数据分析或查询。
一个Agent会同时存在这三个组件,Source和Sink都是异步执行的,相互之间不会影响。
假设我们有采集并索引Nginx访问日志,我们可以按照如下方式部署:
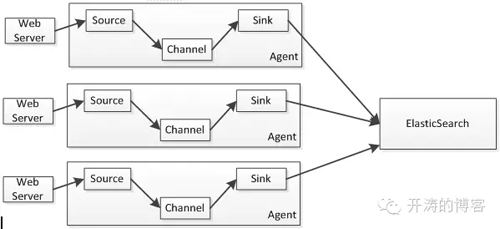
1、Agent和Web Server是部署在同一台机器;
2、Source使用ExecSource并使用tail命令采集日志;
3、Channel使用MemoryChannel,因为日志数据丢点也不算什么大问题;
4、Sink使用ElasticSearchSink写入到ElasticSearch,此处可以配置多个ElasticSearch服务器IP:PORT列表以便提升处理能力。
以上介绍了日志是如何流的,对于复杂的日志采集,我们需要对Source日志进行过滤、写到多个Channel、对Sink进行失败处理/负载均衡等处理,这些Flume默认都提供了支持:
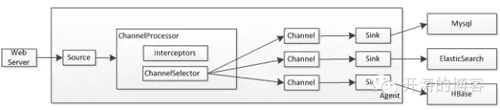
1、Source采集的日志会传入ChannelProcessor组件,其首先通过Interceptor进行日志过滤,如果接触过Servlet的话这个概念是类似的,可以参考《Servlet3.1规范翻译——过滤器 》 ;过滤器可以过滤掉日志,也可以修改日志内容;
2、过滤完成后接下来会交给ChannelSelector进行处理,默认提供了两种选择器:复制或多路复用选择器;复制即把一个日志复制到多个Channel;而多路复用会根据配置的选择器条件,把符合条件的路由到相应的Channel;在写多个Channel时可能存在存在失败的情况,对于失败的处理有两种:稍后重试或者忽略。重试一般采用指数级时间进行重试。
我们之前说过Source生产日志给Channel、Sink从Channel消费日志;它俩完全是异步的,因此Sink只需要监听自己关系的Channel变化即可。
到此我们可以对Source日志进行过滤/修改,把一个消息复制/路由到多个Channel,对于Sink的话也应该存在写失败的情况,Flume默认提供了如下策略:

默认策略就是一个Sink,失败了则这个事务就失败了,会稍后重试。
Flume还提供了故障转移策略:

Failover策略是给多个Sink定义优先级,假设其中一个失败了,则路由到下一个优先级的Sink;Sink只要抛出一次异常就会被认为是失败了,则从存活Sink中移除,然后指数级时间等待重试,默认是等待1s开始重试,***等待重试时间是30s。
Flume也提供了负载均衡策略:

负载均衡算法默认提供了两种:轮训和随机;其通过抽象一个类似ChannelSelector的SinkSelector进行选择,失败补偿机制和Failover中的算法类似,但是默认是关闭失败补偿的,需要配置backoff参数为true开启。
到此Flume涉及的一些核心组件就介绍完了,对于Source和Sink如何异步、Channel提供的事务机制等我们后续分析组件时再讲。
假设我们需要采集非常多的客户端日志并对他们进行一些缓冲或集中的处理,就可以部署一个聚合层,整体架构类似于如下:
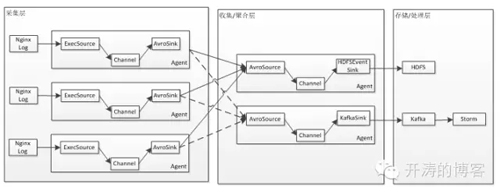
1、首先是日志采集层,该层的Agent和应用部署在同一台机器上,负责采集如Nginx访问日志;然后通过RPC将日志流入到收集/聚合层;在这一层应该快速的采集到日志然后流入到收集/聚合层;
2、收集/聚合层进行日志的收集或聚合,并且可以进行容错处理,如故障转移或负载均衡,以提升可靠性;另外可以在该层开启文件Channel,做数据缓冲区;
3、收集/聚合层对数据进行过滤或修改然后进行存储或处理;比如存储到HDFS,或者流入Kafka然后通过Storm对数据进行实时处理。
到此从Flume核心组件到一般的部署架构我们就大体了解了,而涉及的一些实现细节在接下来的部分进行详细介绍。
【本文是51CTO专栏作者张开涛的原创文章,作者微信公众号:开涛的博客,id:kaitao-1234567】