












前言:数据分析领域自2010前后一直占据了全球信息技术的核心地位,OLAP的需求并未随着Hadoop的流行而消亡,而是被越来越理智的认可——“数据再多也需要分析、分析的主要需求还是交互查询”。本文概括了OLAP的本质原则、曾经的困境和当前的技术派系,希望能引起从业者的思考,共同促进行业进步与发展!
一. 剖析OLAP本质
OLAP(Online Analytical Processing)是一种数据处理技术,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况
二十几年前E.F. Codd提出OLAP时,也参照关系数据库提出了12条规则,但后期没有得到发展,其中有些规则在现在看来都已经不再完全适用,或者不是OLAP的特殊规则。因此我们从OLAP的本质定位上,重新确定三条原则,用以解析OLAP的历史发展:
- 1) 提供多维的业务视图(“维”是OLAP存在和核心概念)
- 2) 满足灵活的交互分析(面向决策分析需要及时响应查询需求的变更)
- 3) 提供高速的检索性能(没有人希望查询数据等待太长时间)
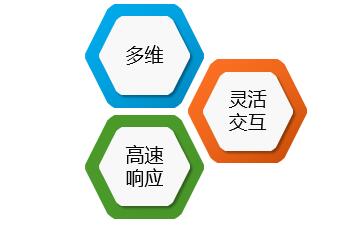
无论从E.F. Codd提出的12条规则中,还是本文提炼的三大原则中,都可以明确出OLAP是满足应用需求而研发的新技术,而且是以“维度”为核心概念的所有技术的统称。
二. OLAP vs Reporting
从事BI/DW的专业人士们,对这张架构图应该非常熟悉,其中同时出现了OLAP和Reporting两个面向用户的应用功能(数据挖掘暂且忽略)。
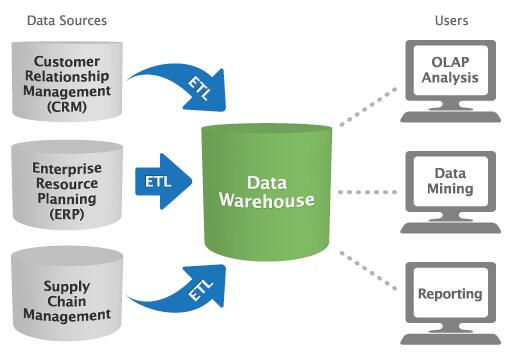
两者核心的区别在于OLAP可以让终端用户可随意更改格式,以及进行维度钻取,甚至自定义成员,而Reporting的终端用户只能按照开发人员的预置做有限交互(比如刷新参数等)。同时从后台原理上,OLAP通过预计算(空间换时间的思想)做到高速响应,Reporting一般通过对关系型数据库的模型和优化保证既定SQL的高速查询。
为什么提到Reporting,因为它是OLAP出现之前的唯一数据应用,也正是因为Reporting解决不了大规模数据的交互分析,才诞生了OLAP。
三. OLAP遇到的困难
OLAP核心三原则的“多维”通过星型/雪花模型得以保证(已经有OLTP能参考的经验)、“灵活交互”和“高速响应”通过基于“预计算”数据的交互查询而实现。这就顺理成章的让我们联想起多维表达式——MDX(MultiDimensional eXpressions),此技术在E.F.Codd提出OLAP四年后就被微软定义并使用。
Multidimensional Expressions (MDX) is a query language for OLAP databases. Much like SQL, it is a query language for relational databases.
MDX是类似SQL的查询语言,只不过查询的是OLAP数据库。
当微软发明MDX后,众多厂商都相继跟进并应用了这个非公开标准的技术,比如Oracle、SAS、Teradata、Cognos、Business Objects等等,从而使得MDX成为了OLAP领域的必备技术。

熟悉OLAP的朋友都知道MOLAP、ROLAP、HOLAP,它们都是时间与空间平衡关系的产物,比如MOLAP牺牲了空间和时效性,过度满足了查询性能,ROLAP保证了空间和时效性,却又容易丧失前端查询的高性能,最后发展出混合型的HOLAP。无论后端如何变化,前端的MDX却从来没有改变过(2008年我曾参加的面试题,里面就全部都是MDX语法)。
言归正传,为什么说OLAP的发展遇到了苦难呢,有这么几点:
1、 OLAP产品的封闭性
虽然前端查询的默认标准是MDX,但由于MDX的不够普及和易用,实际得以商业应用的软件中很多都自成一体(所谓成熟的商业软件),比如IBM Cognos等,造成前端功能的受限和不易集成。只有Microsoft SSAS、Oracle Essbase、Mondrian等少数几个可以把服务端以XML for Analysis标准开放出来,提供比较好的开发和集成能力。
2、 OLAP的预建模瓶颈
传统的OLAP软件,无论MOLAP/ROLAP/HOLAP,都会为用户的使用提前设计一个星型模型,它的好处是便于用户在一个存在相关关系的数据范围内操作,避免出现查询结果的错误。但带来的问题就是,当业务需求变化快或者业务关联更新时,模型就需要重构,而且必须由IT人员负责重构,较低的变更效率影响了使用感受。
3、 xOLAP都满足不了大数据的分析
凡事都存在量变到质变,数据量一旦大到TB、PB的程度,无论是基于文件的MOLAP,还是基于数据库的ROLAP,就都不能满足第三原则(高速响应)了。尤其很多客户已经采用Hadoop的数据架构,传统的OLAP技术就很难融入其中了!
4. OLAP可视化能力弱
熟悉OLAP产品前端操作的用户都清楚,拖拽、下钻、切片这些动作都是基于表格的,基本不能在图形上完成同样的操作,这就给OLAP带来一个基因上的缺陷,就是可视化能力不够。还不要提现在时髦的玫瑰图、网络图、桑基图等等可视化图形!
5. MDX不如SQL普及
MDX在很多统计分析功能上得天独厚,又比如协方差等计算函数,但80%的真正需求还是定位在简单的分级汇总和钻取切片排序上。无论在学习资源还是普及程度上,SQL还是拥有最多人群的数据查询技术。SQL的接受程度从在Hadoop生态的回归就能知道!
技术从来就不能阻挡需求,这些问题存在了若干年后,最近OLAP出现了很多新的技术实现,从多个方向带来了新的选择。
四. OLAP的技术派系
OLAP作为一大类市场需求始终是存在的,需要发展的只是实现它的技术(OLTP所基于的RDBMS非常稳定)。现在OLAP技术发展了20多年,正处于群雄逐鹿阶段,无论未来有没有一统江湖的完美技术,至少从现在来看,我们有必要从OLAP本质三原则梳理技术派系,以便市场参考和个人选择:
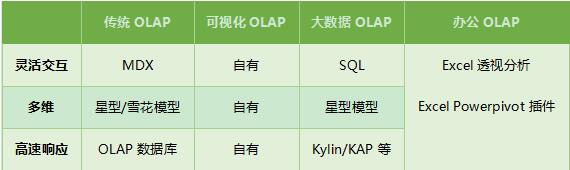
1. 传统OLAP
尊重传统是技术领域最缺少的品德,传统OLAP中尤其是Mondrian和SSAS还是有不少用户群的(前者是开源软件),反而选用Cognos、MSTR等的越来越少。
2. 可视化OLAP
十几年前,最火爆的BI产品是BO(2007年以68亿美元被SAP收购)。BO里最早的核心技术叫做“动态微立方”,就是把基于语义模型查询的结果集数据以MOLAP的方式存储在内存中,以加快后期交互分析的效率。现在同样也有各种基于内存计算的软件,但它们是以可视化为主,比如Tableau和Qlikview等。单纯定位在可视化上的OLAP只有商业软件,没有开源也没有免费的选择,这是因为可视化是个短期需求吧。
3. 大数据OLAP
Hadoop的生态系统诞生于互联网公司,从一开始就有开放的基因,这个OLAP派系最有意思的是Kylin,而且是咱中国人在Apache上的定级项目。“Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。”它与前2者最大不同点在于2个:使用SQL进行查询和支持Hadoop(SQL、SQL、SQL,重要的事情说三遍J)!准确的说,Kylin只是一个OLAP server,它的前端可以选用Smartbi等免费或者商业的软件,也可以选择自己开发。
4. 办公OLAP
最后一个派系也不可小视,那就是微软Excel(WPS等电子表格软件还难以匹敌)。虽然它也是自有的封闭技术,但它的友好性和兼容性足够强大,几乎人人电脑上都能使用,而且也确实是每个数据分析人员都略会一二的工具软件。而且它更重要的价值在于在Excel里面可以维护和处理数据,这是其它3类OLAP都无法提供的。具体介绍网上有很多,大家可以关注中国电子表格应用大会、Excelhome等网络资源。
最后还是强调OLAP是除了报表Reporting和数据挖掘Mining以外的一大类数据分析需求,在遵从“多维”、“灵活交互”和“高速响应”三个本质原则情况下,无论你是办公一族还是软件工程师、大数据专家,都有适合你的OLAP软件工具!
数据的联机分析处理,不会随着时间淡出,只会随着数据化运营的管理观念普及而加强!
















