【51CTO.com原创稿件】大家好,廉哥又来刷存在感了!记得上次在《运维支持和IT管理决策》里和大家聊到“充当‘二线’人员,去处理由服务台和‘一线’运维和支持人员提升上来的安全事故。”后,有小伙伴私信我问:既然有一线、二线人员,那么有没有三线、四线的呢?我很喜欢您的发散思维,的确真的有!我来和大家捋一捋吧:“一般来说:一线人员指的是服务台和运维支持类人员;二线人员则指的是专门的技术和管理部门;而三线是指那些负责软件开发以及系统构架方面的;说道四线支持可以指的服务提供商或者是那些外包商等。”好,那么这次,哥跟大家来漫谈一下一、二线人员的江湖—事件/问题的管理流程。基本的知识,哥就不在这里班门弄斧了,想必小伙伴已从ITIL那里了解领会得比我透彻多了。所以我只谈谈这些理论映射到平时工作中的一些感悟。
在IT日常运维中,企业里时常存在这样的现象:某些问题或服务的处理方式和步骤过度的依赖处理人员的个人经验,而无规范的流程可以依据或参考。这样导致了问题处理或服务提供质量的参差不齐、因人而异,更不用说知识或技巧的沉淀与积累了。可见,IT运维最基本的要素就是要梳理流程,简单说来就是制定操作中可遵循和复用的步骤。
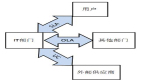
我们先来厘清三个概念。常见的运维流程包括事件、事故和问题三大类。事件是指某种IT服务或是被监控项到达了门限值而发出的警告,以及某种操作所触发的通知等。比如说:磁盘空间即将耗尽、某个系统补丁完成、或对某个用户登录密码的解锁操作等。事件一般包括信息和警告两种,信息多来自于系统的自动记录,因而无需运维人员做出响应。如:应用户请求通过磁带恢复了他在某个时间点误删的邮件,系统相应的自动留下操作记录。而警告则是由监控工具在达到某些门限设定值所产生,需要人工干预和调查。如某个实习生突发上传了大量文件导致网络磁盘使用率超过90%。事件虽然仅起到告知的作用,但运维人员不可忽视,如不处理,则可能陷入恶性循环,升级成事故和问题。
事故是指计划外的IT服务中断或服务质量骤降。如:远程虚拟桌面服务的中断导致正在出差用户无法访问企业内资源,或者是某用户利用企业内网观看在线视频而拖慢了整体的内、外网访问速度。事故也包括一些尚未产生影响的配置项(Configuration Items,下面将提到)丢失。如:做镜像互备的两个磁盘中的一个损坏,但服务尚未中断。对于处理人员来说,有时候能够快速找到那些虽“能治标但不能治本”的事故处理方法可能会比花更多的时间去研究症结更容易被用户所接受和认可。
如果说处理事故是利用应急措施尽快恢复IT服务的话,那么解决问题则是通过查找根源来预防中断的再次发生,以及对那些实在无法避免的尽量降低其影响的过程。如:通过架设备用线路来防止企业租用的电信网络突然中断而导致无法正常继续业务情况的发生。常见的“80-20原则”在此体现为:80%的IT服务中断来自于20%的事故或问题。因此对于问题管理可用被/主动相互结合的方式,即:在日常运维阶段,被动的对出现的问题查找根本原因并予以解决;而在服务发布和变更阶段(以后会花篇幅专门和大家介绍的哦),主动并提前设计好可能出现的问题和处理流程以防范于未然,从而体现“磨刀不误砍柴功”的道理。
各种事件、事故和问题的发现也应做到主/被动相结合。即:由系统自动勘测主动以多种通讯方式告知相关角色人员和由一般用户或其他IT人员通过Web界面、电话或邮件等方式所被动产生。此处特别值得强调的是Web界面设计或选型上应体现如下特点:
1. 各项条目尽可能的是菜单选择式,并有默认值,这样既方便对提交者进行“提问思路”的引导,也方便系统对后台“问题和知名错误知识库”和CMDB〔配置管理数据库)的自动配对和自动流转。
2. 从系统的投资回报率(ROI)的角度来看,越容易提交就越会被用户所频繁使用,例如仅通过三五步操作便可完成。这样既快捷又高效。
3. 为每一个案子(ticket)都自动设置计时/倒计时,截止时间的功能以方便后期评估。
4. 在系统建立之初,运用传统的“紧急程度”和“影响范围”的二象图,定义并设置各种优先级,影响范围和紧急程度等选项。
5. 预先设置的分类越有条理越丰富,越节约处理人员定位和解决的时间。
6. 设定一些预定义的处理路径并能准确读取系统目录里IT角色信息,以方便案子的自动流转和必要时各部门的联动。
7. 通过类似SOAP(Solution Option Analysis Process)的预定义书写格式来规范诊断和处理人员的工作日志并实现智能的导入数据库。这里特别分享一下哥的一个运维经验:如果在案子的整个处理过程中使用了“受影响的配置项(CI)”和错误代码等方面的信息的话,该案子对于事后查找与借鉴将十分有用。因为问题描述不尽相同,但这些特征字段却是很容易定位的。
8. 案子解决后,能通过邮件的形式向用户发放调查问卷,这样既能获取反馈和满意度,又能为时候的考核与审计提供***手资料。
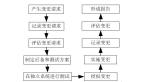
可以按照“录入-分类-分级-诊断-处理”的基本原理来设定一个通用流程(参考下图):
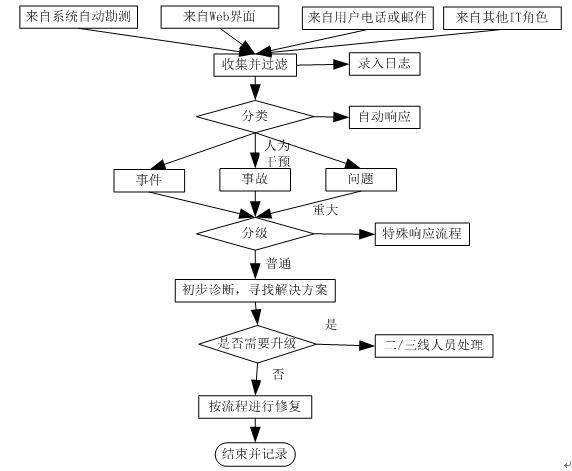
可见,通过设定和规范流程,运维人员的处理步骤和责任显得更为清晰。
既然我们重点谈论的是安全,那么从安全设计和治理角度来说,一般可遵从的是《信息安全应急响应计划规范》,而最直接的方法就是从信息系统的CIA三个基本特性入手,进行风险识别与分析。大家还记得那个“魔性”的PDCA(plan do check act)吗?所以说还是那个原则:对于处置流程和应急预案要定期rehearsal和update。
另外,运维人员应该更注重的是事后分析和防止重现。因此从管理的角度,应该每月产生案子汇总的详细报表(如下图所示)、举行事件管理会议对发生的事件从多维度进行分析和评估;而有条件的话,应该每半年对现有流程进行回顾,回顾内容包括流程关键衡量指标、执行效率,跟踪验证支持工具的有效性,提出与时俱进的改进流程。

还记得哥在本漫谈的开篇就抛出的那个写作提纲吗?现在我把事件/问题管理和下次将要讲到的配置管理和变更管理的关系给大家提前啰嗦一下:事件/问题管理需要从配置管理数据库中查询配置项的属性和配置项间的关联关系来定位故障和帮助快速的恢复。
鉴于变更可能引发事件而且可能波及不止一个用户,因此呼叫中心应当及时了解变更管理流程中所涉及到的正在发生的变更信息,并更新至热线电话的greeting里让用户打进来后就能***时间获知。而在事件的解决过程中,如果涉及到需要对基础架构、应用系统或者是网站页面等进行变更时,一定要通过发起变更请求这样的变更流程来正确解决。
好了,这次先聊到这里吧。屈指算来,我们的漫谈已经坚持了十多期了,回首看来,真心不易。让哥用约翰列侬的那首著名的《Imagine》结束这场漫谈并召唤大家速来互动吧。希望我们的漫谈也能和这次曲子一样时常能引起您的共鸣与认同。
You may say I'm a dreamer
But I'm not the only one
I hope someday you'll join us
And the world will live as one
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】