一、关于文本内容的情感分析
一篇文章反映了什么态度?褒义还是贬义?肯定还是否定?喜怒哀乐愁,反映的是哪种情绪特征?对这些内容的分析就是情感分析,或者叫情感倾向分析。情感倾向 可认为是主体对某一客体主观存在的内心喜恶,内在评价的一种倾向。当然,有正常阅读能力的人,在看了一篇文章后能够判断文章的情感和极性,但这是主观体 验,不是量化数据。在对文章进行分析的时候,通常需要进行量化的分析,显得更加直观、客观。
情感分析基本上有两种方法,一种是极性分析,一种是情感类别分析。前者分析文章的总体态度是肯定还是否定,后者分析文章反映了喜怒哀乐愁中的哪种情感。
仍然以政府工作报告为例,这次是新鲜出炉的2015年度政府工作报告。
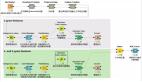
下面是这份报告的情感极性分析结果:

下面是这份报告的情感类别分析结果:

可以看出,政府工作报告在情感极性上,以正面情感为主,其次是中立情感,在情感类别上,以好的情感为主,其次是乐的情感。不愧是政府工作报告。
二、如何进行文本内容的情感分析
1、情感分析的2种方法
情感分析的方法主要分为两类:一种是基于情感词典的方法;一种是基于机器学习的方法。
基于情感词典的方法,需要用到标注好的情感词典。这类词典,英文多,中文少。不过还好,中文的也能够找到几个,包括①台湾大学研发的中文情感极性词典 NTUSD;②大连理工大学的情感本体词汇;③知网发布”情感分析用词语集(beta版)”;④哈工大信息检索研究室开源的《同义词词林》可以用于情感词典的扩充。这几个词典各有特色,都是免费,这点赞一个。
基于机器学习的方法,需要的材料就比较麻烦些,需要的是大量的人工标注的语料作为训练集,通过提取文本特征,构建分类器来实现情感的分类。比如要进行情感 极性的判断,就需要几百上千个反映正面情感的文章,和几百上千个关于负面情感的文章;要进行情感分类的判断,那么每种情感都需要大量文章作为语料。实际上 非常难办到。如果能获得分级的语料,就比较好办,比如像豆瓣网的电影评论,每个评论都有对应的星级,总共五个星级,每个星级对应的评论集合就构成了这一等 级的语料。根据这些语料进行机器学习,就能对新的评论,自动进行分级。机器学习最简单的方式是用朴素贝叶斯分类器进行分类。
2、情感分析的算法
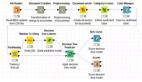
由于情感词典比语料更容易获取,所以用情感词典进行情感分析。算法就是思路,用情感词典进行分析,主要采用以下步骤进行(以情感极性分析为例):
- ①读取情感词典。获得褒义词列表、贬义词列表、中性词列表;获得情感分类词列表及其情感强度。
- ②处理要分析的文本。主要是读取文本,按句子拆分,每个句子进行分词。
- ③计算句子的情感得分。查找句子中每个词语的情感分类,读取其情感强度,用正面情感得分减去负面情感得分,得到句子的情感总分。同时分别计算正面情感的总 分和负面情感的总分,有中性情感的类似处理。需要注意的是,句子中有否定词和程度副词,会影响句子的情感走向和强度,比如”很不喜欢”,分解成”很 不 喜欢”,如果只计算喜欢就是错误的,因为前面有”不”,情感完全相反,还有个”很”说明程度很强烈。因此还需要判断是否有否定词,如果有要反转情感倾向, 要检查是否有程度副词,如果有要进行加权处理。所以,这里还需要一个《否定词库》和《程度副词库》,这两个词库哪里找呢?google吧。
- ④计算文章的情感得分。所有句子的情感得分之和,就是整篇文章的情感得分。
三、R中如何进行情感分析
①首先,需要加载以下的库:
- library(stringr) #对字符进行操作
- library(rJava) #分词需要调用java
- library(Rwordseg) #用于分词
- library(ggplot2) #用于展示图形结果
②其次,需要读取词库,读取词库中的每一类情感词表,用list的格式存储。
③然后,读取要分析的文本,按句子间隔,每句为一行,建立list。
③分词。如何分词在前面的文章中有介绍。
④匹配词表,计算每句话的情感得分,再计算整篇文章的总分和各类情感的总分。
⑤根据结果绘图。
以上谈了思路,具体代码略过。因为代码还需要优化,不太适合展示出来。