【51CTO.com原创稿件】著名的开源分布式缓存服务 Codis 的作者,PingCAP 联合创始人& CTO ,资深 infrastructure 工程师的黄东旭,擅长分布式存储系统的设计与实现,开源狂热分子的技术大神级别人物。即使在互联网如此繁荣的今天,在数据库这片边界模糊且不确定地带,他还在努力寻找确定性的实践方向。
在数据库的平行世界里,黄东旭以不同的方式在追随着自己的内心。他认为,通常传统的关系型数据库无法满足海量数据处理和分析时,新一轮的窗口期也随之需求开启,但是各类劣势架构、内存架构、 NoSQL 等方案都不能满足自己理想的解决方案,这些都不够美,很少能够把分布式事务与弹性扩展做到完美。
绝对的理性与感性,在黄东旭的身上看似矛盾,直到 2012 年底,他看到 Google 发布的两篇论文,如同棱镜般,折射出他自己内心微烁的光彩。这两篇论文描述了 Google 内部使用的一个海量关系型数据库 F1/Spanner ,解决了关系型数据库、弹性扩展以及全球分布的问题,并在生产中大规模使用。“如果这个能实现,对数据存储领域来说将是颠覆性的”,黄东旭为完美方案的出现而兴奋, PingCAP 的 TiDB 在此基础上诞生了。
当然,每向前进一步,都需要付出巨大的努力。在启动 TiDB 项目之前,黄东旭先完成了一个开源分布式的 Redis 集群方案 Codis ,这个项目完成以后让他们觉得虽然缓存的水平扩展问题有了解决方案,但是底层的关系型数据库(主要是 MySQL 为主)并没有一个优雅的扩展方案。业界除了在业务层分库分表,或者使用中间件等折衷方案外,并没有其他太多的办法,有些业务可能能迁移到 NoSQL 之上,例如 HBase 、 C* 等,跟很多的业务没法平滑迁移,几乎需要重写全部逻辑。如果采用分库分表和中间件的方案,扩展以及高可用的方案会带来大量额外的运维成本,比如无法使用跨 shard 的 join、子查询、跨行事务等。
但是作为一个基础软件工程师的黄东旭他们不希望将这些复杂度转嫁给业务层,所以就开始重新审视整个数据库,希望从根本上解决 MySQL 的扩展问题,而不是再造一个中间件。
“如果创造一个全新的东西,使它有一天能够成为生产力,那种感觉真好!”
在 2012 、 2013 年期间,黄东旭他们就开始研究了Google 发表的一系列关于新一代分布式数据库 Spanner 和 F1 的论文以及相关的学术界的进展,直到 2015 年,他们觉得基本所有的技术问题和架构都已经思考得差不多了,于是决定出来全职去重新开始完整的实现一个新的数据库,也就是今天的主角——下一代开源 NewSQL 数据库 TiDB 。
当然了,创造并不意味着开始,它需要面临的是无限的投入和无限的博弈来适应互联网的竞争和审视,真正做到让开发者和企业受益,才是真正的开始。
TiDB在整体架构基本是参考 Google Spanner 和 F1 的设计,上分两层为 TiDB 和 TiKV 。 TiDB 对应的是 Google F1, 是一层无状态的 SQL Layer ,兼容绝大多数 MySQL 语法,对外暴露 MySQL 网络协议,负责解析用户的 SQL 语句,生成分布式的 Query Plan,翻译成底层 Key Value 操作发送给 TiKV , TiKV 是真正的存储数据的地方,对应的是 Google Spanner ,是一个分布式 Key Value 数据库,支持弹性水平扩展,自动的灾难恢复和故障转移(高可用),以及 ACID 跨行事务。值得一提的是 TiKV 并不像 HBase 或者 BigTable 那样依赖底层的分布式文件系统,在性能和灵活性上能更好,这个对于在线业务来说是非常重要。
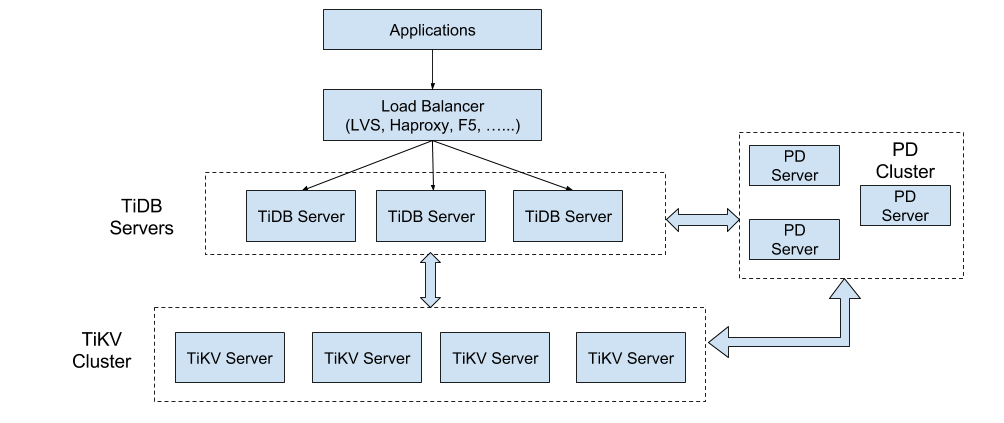
▲ TiDB 整体架构
这群理想很丰沛,这不被骨感现实所惑的人。在 TiDB 研发语言的选择过程中,放弃了 Java 而采用 Go 。
TiDB整个项目分为两层,TiDB 作为 SQL 层,采用 Go 语言开发, TiKV 作为下边的分布式存储引擎,采用 Rust 语言开发。在架构上确实类似 FoundationDB,也是基于两层的结构。 FoundationDB 的 SQL Layer 采用 Java ,底层是 C++ ,不过在去年,被 Apple 收购了。
在选择编程语言并没有融入太多的个人喜好偏向, SQL 层选择 Go 相对 Java 来说:
第一是 他们团队的背景使用 Go 的开发效率更高,而且性能尚可,尤其对于高并发程序而言,可以使用 goroutine / channel 等工具用更少的代码写出正确的程序;
第二是 在标准库中很多包对网络程序开发非常友好,这个对于一个分布式系统来说非常重要;
第三是 在存储引擎底层对于性能要求很高,Go 毕竟是一个带有 GC 和 Runtime 的语言,在 TiKV 层可以选择的方案并不多,过去基本只有 C 或 C++,不过近两年随着 Rust 语言的成熟,又在经过长时间的思考和大量实验,最终他们团队选择了 Rust。
Rust 这门静态语言的定位是取代 C++,最大的特点是通过很多语法的限制来避免开发者写出内存泄露和 data race 的程序,将很多问题解决在编译期,使得运行时不需要花费额外的代价进行 GC 之类的事情,保证高性能。所以,写出安全的程序,这正是 C++ 程序的很大的一个痛点。
虽然在 C++ 11 中有了很多的改进,但是由于历史包袱太重或者第三方包库开发者的水平参差不齐。但是重要的原因不因为别的,正是他们的背后并不是一个 C++ 背景很深的团队,所以最后放弃了 C++ 11 而选择了 Rust 。
Rust 不仅有安全和高性能的特点,同时语法更加现代,开发效率更高,另外拥有非常完善的包管理机制(Cargo),使得在能写出非常高性能且安全的程序同时,开发效率比起 Go并没有下降太多,对于目前来说是一个非常正确的选择。作为 Rust 社区内全球最大的开源项目之一,也得到了 Rust 语言官方团队的很大支持,黄东旭表示,包括一些他们需要的第三方库,Rust team 都会放在很高优先级上去开发或者在社区里推进。另外 Rust 早已发布 1.0,语法也早已稳定,是一个非常有前途的系统编程语言。
轮番在Google中刷出了存在感后,还一直在没有尽头的草原上奔跑,黄东旭认为只有聚焦,专注,才能摆脱掉令人迷惑的干扰。在不断的探索后,终于寻找到了实现事务模型的方式。
TiDB 的事务模型通过参考了 Google 的 Percolator。该论文发表于 2010 年,是描述 Google 在 BigTable 上的构建 ACID 跨行事务框架用于保证索引更新的一致性。算法的核心思想是两阶段提交,但是传统的分布式两阶段提交的问题是单点的事务管理器没法扩展,会成为整个系统的瓶颈,Percolator 使用了一个两级锁的机制实现了去中心化的事务管理器,使得整个系统的可扩展性大大提升。
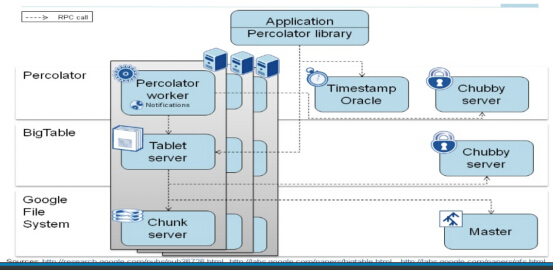
▲ Goolge Percolator内部实现
TiDB 将这个模型应用在底层的存储引擎中,并做了很多工程上的优化,黄东旭举例说,通过 batch 和 pipeline 等手段大大提升了授时服务的吞吐,使用 Raft + RockDB 来替代原文的 BigTable 性能更好,另外采用乐观事务机制追求更高的吞吐,不过是从算法层面,是 Percolator 实现。
TiDB 对比 NOSQL
TiDB 对于这些 NoSQL 来说,最大的特点是编程接口是 SQL,SQL对于开发者而言是更加灵活的操作数据库的方式,且对 MySQL 有着极高的兼容性—原业务的 MySQL切换到 TiDB 几乎一行代码都不用修改就可以完成。TiDB 在支持 SQL 的同时有没有丧失 HBase 这样的系统的弹性扩展能力,业务层不需要再去关心数据库的容量,不用去考虑分库分表,也不用像过去那样投入很大的运维力量,扩容只需简单加机器就好,存储节点故障对业务透明,而且数据库本身具有自我修复的能力,保证数据不会丢失。
对于 MongoDB 也是一样,更重要的是不需要改变用户已有的习惯和程序,而且为了定义未来的云上的数据库形态,TiDB 设计的目标是单集群需要可以 Scale 到 1000 以上物理节点的规模,支持 P 级别容量,万亿以上的行的结构化数据存储,在这个前提约束下的设计和技术选型和 MongoDB 很不一样,在大数据量的情况下 TiDB 的表现更稳定,扩展更加平滑。
TiDB 的 SQL 优化器是黄东旭他们从头开始实现的一个面向分布式存储设计的查询优化器,使用了很多学术界很新的查询优化技术和分布式计算框架的思想,保证 MySQL 兼容性的前提下比 MySQL 在复杂查询下表现要好得多。
传统数据库的痛点解决
任何企业,如果使用传统的单机关系型数据库,在数据量持续增长下,或者对业务的可用性有严格要求的情况下,可能都会面临单点故障和单点容量限制的问题,这个问题最近几年在互联网行业尤其突出,目前来说除了上面提到的分库分表和中间件也并没有其他的方案解决,几乎苦不堪言。
TiDB 基于更先进的 Raft 算法来实现了存储层的水平扩展基础上加上了分布式事务,构建了完整的 SQL 查询层,在保证不丧失 ACID 事务的前提下,支持 JOIN ,子查询等复杂查询,另外对外暴露 MySQL 接口,让用户几乎在无侵入性的前提下,解决大量结构化数据的存储问题。考虑到传统行业和互联网行业的代差大概在 3 年左右,另外这个时间在不断的缩短,最近随着 TiDB 趋于稳定,越来越多的互联网在使用 TiDB ,相信未来会成为扩展数据库的一个新的主流选择。
TiDB 的应用场景
应用场景是典型的 OLTP 场景,范围很大,覆盖到任何企业。在关系型数据库上遇到扩展性问题、同时需要强一致事务、需要实现多数据中心强一致和高可用,都是 TiDB 的典型用户。TiDB 对 MySQL 的支持很完善,基于目前使用着 MySQL 的用户或企业,希望寻求更优雅的水平扩展方案,都是非常不错的选择。
其实目前在统计大多数线上生产环境中使用的用户基本都是互联网场景,从 MySQL 过来。TiDB 目前暂时不支持存储过程和视图,所以前提条件是已有业务中没有这类操作。
在项目开始第一天就确定了 TiDB 最大兼容 MySQL ,黄东旭坦言, MySQL 是一个单机的数据库,而且查询优化器是针对单机场景设计,基于这架构上去做一个分布式数据库的难度很大。
而此时,他们决定选择一条更彻底的道路,就是重写整个 SQL Parser 和查询优化引擎。虽然看上去几乎是不可能完成的事情,但是实际做下来他们觉得在一个更良好设计和复杂度控制下,反而是一条更轻松的路。而选择完全的 MySQL 兼容这个事情带来的好处不仅限于对用户的友好度,更重要的是能从 MySQL 社区吸取大量的测试。这对于一个数据库产品来说,做出来并不难,如何证明你是对的,这才是更重要的!黄东旭他们不断的从 MySQL 社区收集了千万级的测试用例来保证每个模块的正确性,和对 MySQL 行为的一致性。
TiDB 项目开源的程度
TiDB 项目是100% 开源,致力于做一个具有国际水准的顶级开源项目,从 Github repo 本身其实很难看出来这是一个背后是国人主导的开源项目,所有的提交记录,所有的协作,Roadmap ,Issue tracking ,中英文文档,以及代码审核都是开源的。
而项目已经迭代到 Beta 4 版本,从线上用户的反馈,主要的功能已经基本完善稳定。黄东旭表示,接下来重要的工作会是持续的性能优化和继续提升稳定性,还有在更大容量,更恶劣严苛的集群环境下持续测试。当然周边工具,部署教程,更多的设计文档也是在持续的丰富中。
TiDB 的未来
从更长远的角度,一切东西都会运行在云端,数据库也不例外。在海量数据,大规模集群的前提下,关系型数据库的设计和理论还有很多东西需要探索,这种集群规模之下,一切依赖人工的运维都将会失效,因为人是没法 scale ,数据库需要具有自我修复和自我扩展的能力,也只有这样,才能更好的利用集群的计算资源,这也为什么 TiDB 团队对自己的定位是要做 Cloud-Native 的数据库,他们在为未来做很多基础性的研究和准备,包含对 Kubernetes 和分布式数据库的结合上也做了很多探索性的工作。
黄东旭希望 TiDB 定义下一代关系型数据库,未来开发者能够真正专注自己的业务,不用在关心数据库有多大,并发可能会有多高,什么时候需要扩容一下,选哪个 sharding key 好等这些问题都应该被隐藏在一个很简单的 SQL interface 之下。
TiDB 有了非常不错的开头,他们做到了,在下一代关系型数据库里面,每个人都能感受到这种技术所带来生产力的美好!
开源项目地址:https://github.com/pingcap/tidb
PS:黄东旭将在11月26号出席WOT2016大数据技术峰会,届时在NoSQL实践技术专场分享《NewSQL in action: Patterns and Tools》内容,敬请关注。
WOT2016大数据技术峰会官网:http://wot.51cto.com/
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】