小编说:从数据分析的角度来看,数据挖掘与机器学习有很多相似之处,但不同之处也十分明显,例如,数据挖掘并没有机器学习探索人的学习机制这一科学发现任务,数据挖掘中的数据分析是针对海量数据进行的,等等。从某种意义上说,机器学习的科学成分更重一些,而数据挖掘的技术成分更重一些。
本文选自《大数据架构详解:从数据获取到深度学习》

机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。其专门研究计算机是怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。
数据挖掘是从海量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘中用到了大量的机器学习界提供的数据分析技术和数据库界提供的数据管理技术。
学习能力是智能行为的一个非常重要的特征,不具有学习能力的系统很难称之为一个真正的智能系统,而机器学习则希望(计算机)系统能够利用经验来改善自身的性能,因此该领域一直是人工智能的核心研究领域之一。在计算机系统中,“经验”通常是以数据的形式存在的,因此,机器学习不仅涉及对人的认知学习过程的探索,还涉及对数据的分析处理。实际上,机器学习已经成为计算机数据分析技术的创新源头之一。由于几乎所有的学科都要面对数据分析任务,因此机器学习已经开始影响到计算机科学的众多领域,甚至影响到计算机科学之外的很多学科。机器学习是数据挖掘中的一种重要工具。然而数据挖掘不仅仅要研究、拓展、应用一些机器学习方法,还要通过许多非机器学习技术解决数据仓储、大规模数据、数据噪声等实践问题。机器学习的涉及面也很宽,常用在数据挖掘上的方法通常只是“从数据学习”。然而机器学习不仅仅可以用在数据挖掘上,一些机器学习的子领域甚至与数据挖掘关系不大,如增强学习与自动控制等。所以笔者认为,数据挖掘是从目的而言的,机器学习是从方法而言的,两个领域有相当大的交集,但不能等同。
典型的数据挖掘和机器学习过程
下图是一个典型的推荐类应用,需要找到“符合条件的”潜在人员。要从用户数据中得出这张列表,首先需要挖掘出客户特征,然后选择一个合适的模型来进行预测,***从用户数据中得出结果。
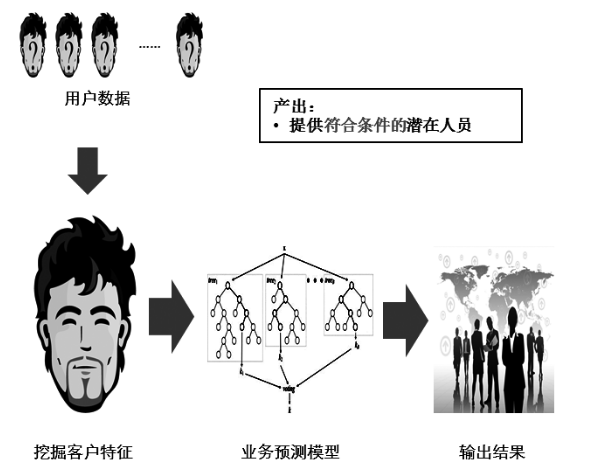
把上述例子中的用户列表获取过程进行细分,有如下几个部分。
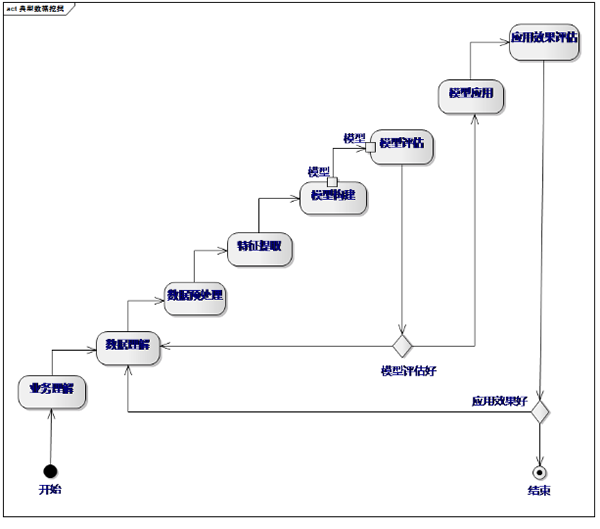
业务理解:理解业务本身,其本质是什么?是分类问题还是回归问题?数据怎么获取?应用哪些模型才能解决?
数据理解:获取数据之后,分析数据里面有什么内容、数据是否准确,为下一步的预处理做准备。
数据预处理:原始数据会有噪声,格式化也不好,所以为了保证预测的准确性,需要进行数据的预处理。
特征提取:特征提取是机器学习最重要、最耗时的一个阶段。
模型构建:使用适当的算法,获取预期准确的值。
模型评估:根据测试集来评估模型的准确度。
模型应用:将模型部署、应用到实际生产环境中。
应用效果评估:根据最终的业务,评估最终的应用效果。
整个过程会不断反复,模型也会不断调整,直至达到理想效果。
机器学习&数据挖掘应用案例
1 尿布和啤酒的故事
先来看一则有关数据挖掘的故事——“尿布与啤酒”。
总部位于美国阿肯色州的世界著名商业零售连锁企业沃尔玛拥有世界上***的数据仓库系统。为了能够准确了解顾客在其门店的购买习惯,沃尔玛对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。沃尔玛数据仓库里集中了其各门店的详细原始交易数据,在这些原始交易数据的基础上,沃尔玛利用NCR数据挖掘工具对这些数据进行分析和挖掘。一个意外的发现是:跟尿布一起购买最多的商品竟然是啤酒!这是数据挖掘技术对历史数据进行分析的结果,反映了数据的内在规律。那么,这个结果符合现实情况吗?是否有利用价值?
于是,沃尔玛派出市场调查人员和分析师对这一数据挖掘结果进行调查分析,从而揭示出隐藏在“尿布与啤酒”背后的美国人的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买完尿布后又随手带回了他们喜欢的啤酒。
既然尿布与啤酒一起被购买的机会很多,于是沃尔玛就在其各家门店将尿布与啤酒摆放在一起,结果是尿布与啤酒的销售量双双增长。
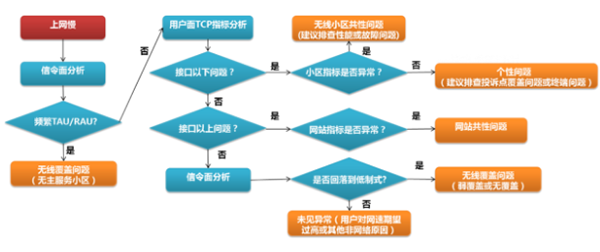
2 决策树用于电信领域故障快速定位
电信领域比较常见的应用场景是决策树,利用决策树来进行故障定位。比如,用户投诉上网慢,其中就有很多种原因,有可能是网络的问题,也有可能是用户手机的问题,还有可能是用户自身感受的问题。怎样快速分析和定位出问题,给用户
一个满意的答复?这就需要用到决策树。
下图就是一个典型的用户投诉上网慢的决策树的样例。
3 图像识别领域
百度的百度识图能够有效地处理特定物体的检测识别(如人脸、文字或商品)、通用图像的分类标注。

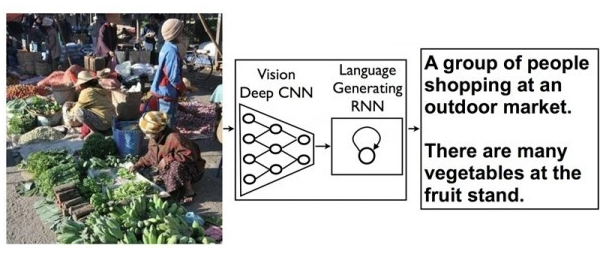
来自Google研究院的科学家发表了一篇博文,展示了Google在图形识别领域的***研究进展。或许未来Google的图形识别引擎不仅能够识别出图片中的对象,还能够对整个场景进行简短而准确的描述。这种突破性的概念来自机器语言翻译方面的研究成果:通过一种递归神经网络(RNN)将一种语言的语句转换成向量表达,并采用第二种RNN将向量表达转换成目标语言的语句。

而Google将以上过程中的***种RNN用深度卷积神经网络CNN替代,这种网络可以用来识别图像中的物体。通过这种方法可以实现将图像中的对象转换成语句,对图像场景进行描述。概念虽然简单,但实现起来十分复杂,科学家表示目前实验产生的语句合理性不错,但距离***仍有差距,这项研究目前仅处于早期阶段。下图展示了通过此方法识别图像对象并产生描述的过程。
4 自然语言识别
自然语言识别一直是一个非常热门的领域,最有名的是苹果的Siri,支持资源输入,调用手机自带的天气预报、日常安排、搜索资料等应用,还能够不断学习新的声音和语调,提供对话式的应答。
微软的Skype Translator可以实现中英文之间的实时语音翻译功能,将使得英文和中文普通话之间的实时语音对话成为现实。
Skype Translator的运作机制如图。
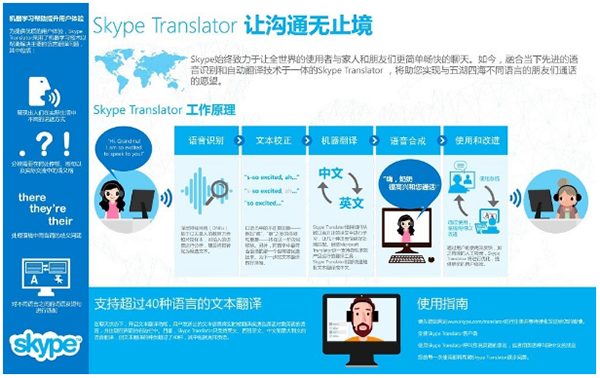
在准备好的数据被录入机器学习系统后,机器学习软件会在这些对话和环境涉及的单词中搭建一个统计模型。当用户说话时,软件会在该统计模型中寻找相似的内容,然后应用到预先“学到”的转换程序中,将音频转换为文本,再将文本转换成另一种语言。
虽然语音识别一直是近几十年来的重要研究课题,但是该技术的发展普遍受到错误率高、麦克风敏感度差异、噪声环境等因素的阻碍。将深层神经网络(DNNs)技术引入语音识别,极大地降低了错误率、提高了可靠性,最终使这项语音翻译技术得以广泛应用。