喜大普奔!OnionScan0.2终于发布啦!在新版OnionScan中,最引人注目的一个新功能就是“custom crawls”(自定义爬取)。我们将会通过这篇文章来教会大家如何去使用这个强大的功能。【 OnionScan 0.2下载地址 】

可能对暗网比较了解的同学都知道OnionScan是个什么东西吧?OnionScan是一款非常棒的工具,你可以用它来扫描暗网中的隐藏服务,并收集一些潜在的泄漏数据。除此之外,OnionScan也可以帮助你搜索出各种匿名服务的标识,例如比特币钱包地址、PGP密钥、以及电子邮件地址等等。
但是,暗网中的很多服务数据都是以非标准的数据格式发布的,不同的服务很可能使用的是不同的数据格式,这也就使得我们很难用软件工具来对这些数据进行自动化处理。
不过别担心,OnionScan可以帮助我们解决这个难题。OnionScan允许我们自定义各个网站之间的关系,然后我们可以将这些关系导入至OnionScan的关联引擎(Correlation Engine)之中。接下来,系统会像处理其他标识符那样来帮助我们对这些关系进行关联和分类。
接下来,我们以暗网市场Hansa来作为讲解实例。当我们在收集该市场中的数据时,我们首先要收集的往往是市场中处于在售状态的商品名称和商品类别,有时我们可能还需要收集这些商品的供应商信息。实际上,我们可以直接访问产品的/listing页面来获取所有的这些信息。
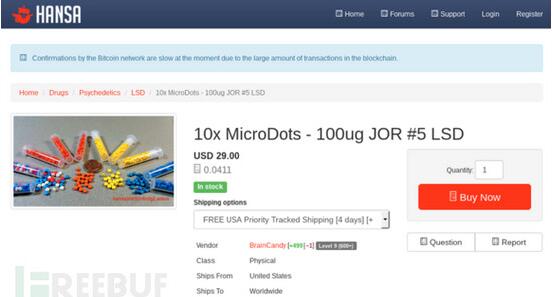
但是,我们现在要自己动手制作一个暗网爬虫。我们将使用这个爬虫来爬取并导出我们所需的数据,然后再对这些数据进行处理,***再将其转换成我们可以进行自动化分析的数据格式。在OnionScan0.2的帮助下,我们只需要定义一个简单的配置文件就可以轻松实现这些操作了。相关代码如下所示:
- {
- "onion":"hansamkt2rr6nfg3.onion",
- "base":"/",
- "exclude":["/forums","/support","/login","/register","?showFilters=true","/img","/inc", "/css", "/link", "/dashboard","/feedback", "/terms", "/message"],
- "relationships":[{"name":"Listing",
- "triggeridentifierregex":"/listing/([0-9]*)/",
- "extrarelationships":[
- {
- "name":"Title",
- "type":"listing-title",
- "regex":"
- (.*)
- " }, { "name":"Vendor", "type":"username", "regex":" " }, { "name":"Price", "type":"price", "regex":" (USD[^<]*) " }, { "name":"Category", "type":"category", "regex":"
- ([^<]*)
- ", "rollup": true } ] } ] }
上面这段代码可能看起来非常的复杂,不过别担心,接下来我们会给大家一一进行讲解。
代码开头的“onion”参数定义的是我们所要扫描的暗网服务(”onion”:”hansamkt2rr6nfg3.onion”)。“base”参数定义的是我们要从网站的哪个路径开始执行扫描,在这里我们准备从网站的根目录开始扫描(”base”:”/”)。与普通网站一样,大多数暗网服务同样只在网站子目录中才会保存有效数据,例如刚才的“listing”目录。在这种情况下,我们就可以使用“base”参数来告诉OnionScan从网站的哪一部分开始执行扫描,这样可以为我们节省大量的时间。
“exclude”参数可以让OnionScan排除某些类型的扫描对象,例如“/forums”、“/support”、“/login”、以及“/register”。通常情况下,这些链接我们***不要去碰,因为它们有可能会进行某些我们不希望发生的行为。
接下来就是“relationships”参数了,这个参数中定义的逻辑才是这个爬虫最核心的部分。
我们的逻辑关系主要是由“name”和“triggeridentifierregex”这两个参数定义的。其中的正则表达式主要应用于目标网站的URL地址,当正则表达式匹配到关系中的剩余规则时,就会触发相应的操作。在这个例子中,我们在OnionScan中定义了正则表达式“/listing/([0-9]*)/”,它将会触发URL地址中的Listing关系。需要注意的是,OnionScan还会根据URL地址中的“([0-9]*)”来识别资源之间的关系。
每一个关系都有一个“extrarelationships”参数,这个参数中定义的关系是OnionScan在进行搜索操作时需要用到的。
比如说,在我们的配置文件中,我们定义了四个额外的关系,即“Title”、“Vendor”、 “Price”和“Category”。每一个额外定义的关系都需要定义“name”和“type”参数,OnionScan的关联引擎将需要使用到这部分数据。除此之外,我们还要在关系中定义一个正则表达式,即“regex”参数,我们可以通过这个正则表达式来提取目标页面中的数据关系。
在Hansa市场这个例子中可以看到,我们可以通过正则表达式“”来从产品的/listing页面中提取出厂商信息。类似地,我们也可以通过这种方法提取出产品的标题、价格、以及分类目录。
“rollup”参数是OnionScan中的一个指令,这个指令可以让OnionScan对我们所搜索到的产品分类数量进行数据统计,并以可视化的形式输出统计结果。
现在,我们已经通过配置文件来告诉OnionScan应该从Hansa市场中提取哪些数据了,但是OnionScan应该如何使用这个配置文件呢?
接下来,先将我们刚才定义好的配置文件放到“service-configs”文件夹中,然后通过下列命令来让OnionScan对市场执行扫描操作:
- ./onionscan -scans web --depth 1 --crawlconfigdir./service-configs/ --webport 8080 --verbose hansamkt2rr6nfg3.onion
搜索结果如下图所示:
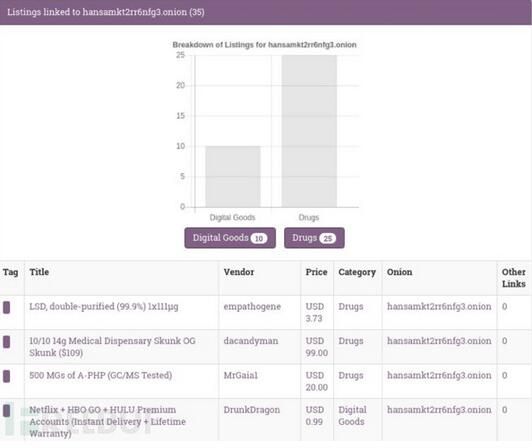
从上面这张图片中可以看到,我们只需要定义一个简单的配置文件,OnionScan就可以帮我们完成剩下的操作。我们之所以可以获取到这张统计表格,是因为我们之前将“rollup”参数设为了“true”,所以OnionScan才会给我们提供这样一份可视化的统计数据。