












本文为鄂维南院士访谈整理,文中探讨了中国在大数据发展中受到了哪些因素的制约。
近来,大数据如浪潮般席卷全球。越来越多的国家开始从战略层面认识大数据,中国亦如此。然而任何发展都不应盲目跟从,而应该在发展中不断认识其发展的意义与遇到的困难挑战,要做到及时发现总结,才能更好的发展。
那么,制约我国大数据发展的因素有哪些呢?
1.优质可用数据缺乏
很多人看到这点可能会感到奇怪。这几年数据交易机构如雨后春笋,“数据变现”成为很多拥有数据积累的传统企业的新的生财法。如图,2015年以来,各地加速建立大数据交易平台,数据交易市场异常火热。
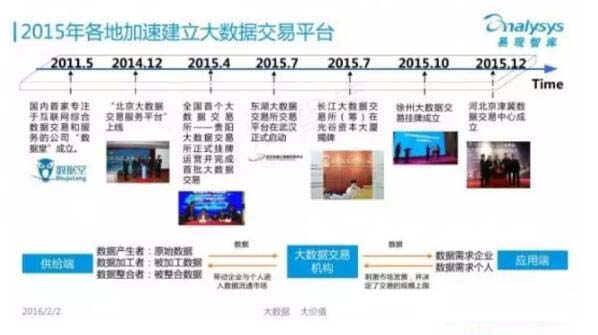
我们常常说,大数据最高的层次就是要用数据来形成智慧,使得社会各方面可以运转起来。做数据分析先要整合数据,这是我们通常的理念。而数据本身我们可以从三个层面来看。
首先是“有没有”,就是数据交易问题。目前,我国大数据需求端以互联网企业为主,覆盖面不广,在O2O趋势下,大型互联网厂商尝试引入外部数据支撑金融、生活、语音、旅游、健康和教育等多种服务。
然而在具体的领域或行业内,我国普遍未形成成型的数据采集、加工、分析和应用链条,大量数据源未被激活,大多数数据拥有者没有数据价值外化的路径。比如,各医疗健康类应用收集了大量的数据,但没有像Sermo.com那样面向医药公司售卖数据。与国外相比我国的政府、公共服务、农业应用基本缺位,电信和银行业更缺少与外部数据的碰撞。
另外,其实数据交易这件事本身就是一个悖论。数据作为一种商品有一定的特殊性,我用了别人也可以用,没有任何消耗,可以在市场卖很多遍。这就产生一个问题,你这个数据到市场卖,根据经济学观点它的价值是零,你卖给我我可以用更低的价格卖给别人,所以数据交易理论上来说也是不可行的。
其次是“好不好”,也就是数据质量问题。大数据概念火了以后,很多机构觉得数据存起来就是宝,于是积攒了大量零碎数据放在那里,到底能发挥什么作用也未可知。而在和许多真正想用数据做些事情的机构的合作中我们发现,即便是政府机构这样的权威数据持有方,也存在很多数据缺失、数据错误、噪音多各方面的问题。当然这并不是说我们就不能做数据分析了。我们常常在讲大数据就用大数据方法,小数据就用小数据方法,完美的数据是永远等不来的。但这样会导致什么问题呢?在实际项目实施过程中,我们的数据科学家们不得不花费大量时间在数据清洗上,这其实是对本来就紧缺的数据人员的一种浪费。
最后是“让不让”,即数据孤岛和数据开放问题。理论上我们中国有很多数据,但不同部门数据存在在不同的地方,格式也不一样。政府内部本身整合各部门的数据就已经是一件很头大的事情,更不要提大规模的数据开放。同时数据开放面临一个严重问题就是隐私问题,脱敏远远不够,隐私问题是一个无底洞。比如我们把一个人的支付宝3个月数据拿过来,就可以很轻易的知道这个人今天在门口便利店买了一瓶水,昨天在淘宝买了沙发,每隔三个月会有一笔万元的支出。那我们就可以很容易推断这个人刚换了一个租房子的地方,就能了解他的消费习惯。这个数据其实完全是脱敏的,没有名字、没有号码,但丝毫不妨碍我们通过算法完全的勾勒出这个人的画像。
2.技术与业务的鸿沟
大数据行业发展至今,技术与业务之间依然存在巨大着鸿沟。首先,就是数据分析技术本身。数据源企业为实现数据价值变现,尝试多种方法,甚至自己组建数据分析团队,可是数据分析是个技术活,1%的误差都会极大地影响市场份额,术业有专攻,数据变现还是需要专业的数据分析人才来实现。
随着大数据概念的火热,做大数据的公司越来越多,产品做得五花八门,数据建模看似谁都可以涉足,但现在数据分析的技术,方法,模型,算法都有了非常大的改进,跟过去六七十年代完全不一样,不是说做几个SAAS软件或者RAAS软件就是大数据了,虽然短期看市场火热,但长远来说这条路是走不通的,大数据行业发展,技术才是真正的发力点,提高行业准入门槛尤为重要。
基于此,鄂维南院士将海外成熟的大数据建模分析技术带回国内,并组织成立了北京大数据研究院和普林科技,北京大数据研究院专注于顶层设计,探索大数据行业产学研相结的发展模式,普林科技负责落地实施,从业务层面推动大数据行业发展。
其次中国的数据有它的特色,例如在金融行业,目前大部分银行采用的是风险评分卡,运用专家经验定义风险变量,基于定性认识进行评分,通过事后风险回检优化评分卡,风险预警功能较差。虽然央行征信中心与国内少数技术领先银行使用的是风险评分模型,但模型方法相对陈旧,如央行所用FICO评分模型为上世纪80年代基于逻辑回归算法构建的评分体系,逻辑回归算法适合处理线性数据,但实际问题往往是非线性的,特别是信用风险评估场景下。此外,FICO模型没有针对我国具体业务进行场景细分,建模逻辑并不完全符合我国实际情况,因此导致准确率不足,风险预警能力差。
基于此,中国人民银行征信中心首次与国内大数据公司合作,这次合作中普林科技应用国际领先的大数据建模分析技术,运用决策树,随机森林,AdaBOOST,GBDT,SVM等算法,通过对信用报告的数字化解读与深入洞察,准确预测了违约风险,对贷款审批、贷中管理形成指导,新模型对好坏账户的区分度远高于行业平均水平。此次合作表明我国的大数据难题更需要适应国情的解决方案与本土的技术人才,这对我们的市场提出了一个新问题。
3.人才难觅
我们国家大数据发展最大的优势就是市场大,最大的劣势恰巧就是缺乏相应人才,人才缺乏的程度非常严重。首先在国际市场方面,我们要跟国外公司争人才,然而国外大数据行业同样十分火热。而不论在国内还是国外,跟企业竞争人才都是一项艰巨的事业,比如在世界上最好的大学之一的美国普林斯顿大学,想找数学家也是非常困难,人才很容易被大公司挖走,每年都有非常好的数据分析人才被企业挖走。所以人才难觅不只是口头说说,更是一个亟待解决的问题。
目前为止,我们国家仍然没有良好的培育大数据人才的机制,大数据教育主要面临以下三个问题。
首先,大数据是一个交叉学科,涉及统计学,管理,编程等多学科,知识点复杂,培训课程编辑难度大,缺乏系统的学习教程;
其次,现阶段大数据教育大多还停留在理论知识上,理论与实战严重脱节,学习者缺乏良好的实践机会;
再次,大数据教育的根本目的是为了解决业务上面临的实际问题,用科学的手段推动业务的进展,然而现阶段的大数据教育机构普遍缺乏相应的业务经验,产学研结合并不密切。
针对这些问题,鄂维南院士讲到:“其实我个人在这方面想了很长时间,就是怎样才能在中国真正建设一个具有国际标准、国际水平的大数据平台?我们国家拥有这么大的市场,我们在做大数据行业同时,一定要想着做就要做到这个领域领先水平。但要达到这个目标,有一点很关键,必须要有一个国际化标准的研究平台,因此,我带头成立了北京大数据研究院,而这个研究院所要做得事情,就是把人才培养教育和科研创新和市场化、产业化结合在一起。”














