我们想要告诉大家的是成为大数据工程师需要掌握的知识体系,而作为初学者,你可以先从简单的入手,慢慢在学更深的知识,拿出高考的恒心和坚持来,肯定能行。
值得一提的是,目前大数据工程师的月薪都是20K起,月收入两万的薪资是不是很诱人?而且大数据工程师是非常容易找到工作的,所以……Why not
不扯犊子了,由于篇幅所限,这一部分内容主要包括数据可视化、机器学习和算法三个分支。
数据可视化
R
R不仅是编程语言,同时也R具有强大的统计计算功能和便捷的数据可视化系统。在此,推荐大家看一本书,这本书叫做《R数据可视化手册》。
《R数据可视化手册》重点讲解R的绘图系统,指导读者通过绘图系统实现数据可视化。书中提供了快速绘制高质量图形的150多种技巧,每个技巧用来解决一个特定的绘图需求。读者可以通过目录快速定位到自己遇到的问题,查阅相应的解决方案。同时,作者在大部分的技巧之后会进行一些讨论和延伸,介绍一些总结出的绘图技巧。 《R数据可视化手册》侧重于解决具体问题,是R数据可视化的实战秘籍。《R数据可视化手册》中绝大多数的绘图案例都是以强大、灵活制图而着称的R包ggplot2实现的,充分展现了ggplot2生动、翔实的一面。从如何画点图、线图、柱状图,到如何添加注解、修改坐标轴和图例,再到分面的使用和颜色的选取等,本书都有清晰的讲解。
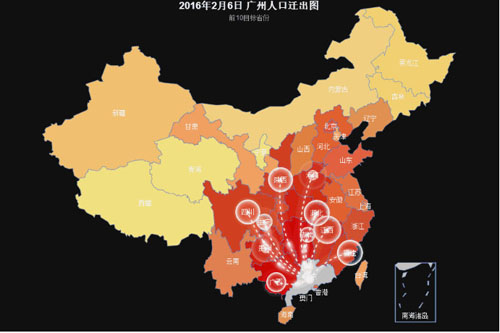
此书在网上就可以购买得到,当然也有电子版。在此,我们放出一张用R做出来的可视化作品。
D3.js
D3 (Data-Driven Documents)是基于数据的文档操作javascript库,D3能够把数据和HTML、SVG、CSS结合起来,创造出可交互的数据图表。
ECharts
ECharts是一款数据可视化的纯JavaScript图标库,其拥有混搭图表、拖拽重计算、制作数据视图、动态类型切换、图例开关、数据区域选择、值域漫游、多维度堆积等非常丰富的功能。
ECharts (Enterprise Charts 商业产品图表库)是基于HTML5 Canvas的一个纯Javascript图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。创新的拖拽重计算、数据视图、值域漫游等特性大大增强了用户体验,赋予了用户对数据进行挖掘、整合的能力。
ECharts提供商业产品常用图表库,底层基于ZRender,创建了坐标系,图例,提示,工具箱等基础组件,并在此上构建出折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)、地图、力导向布局图,同时支持任意维度的堆积和多图表混合展现。
Excel
Excel中大量的公式函数可以应用选择,使用Microsoft Excel可以执行计算,分析信息并管理电子表格或网页中的数据信息列表与数据资料图表制作,可以实现许多方便的功能,带给使用者方便。与其配套组合的有:Word、PowerPoint、Access、InfoPath及Outlook,Publisher
事实上,Excel完全可以满足大家日常工作中图表制作和数据可视化的需求,所以,想要进入大数据行业,学好Excel是基础。
Python
Python 的科学栈相当成熟,各种应用场景都有相关的模块,包括机器学习和数据分析。数据可视化是发现数据和展示结果的重要一环,只不过过去以来,相对于 R 这样的工具,发展还是落后一些。
幸运的是,过去几年出现了很多新的Python数据可视化库,弥补了一些这方面的差距。matplotlib 已经成为事实上的数据可视化方面最主要的库,此外还有很多其他库,例如vispy,bokeh, seaborn, pyga, folium 和 networkx,这些库有些是构建在 matplotlib 之上,还有些有其他一些功能。
报表类:FineReport
工作中数据可视化呈现的最多场景就是报表了。大数据工程师要做的可视化可不单单是表格数据展示,还有将数据从数据仓库中抽取得到实时呈现和展示。
FineReport是国内数一数二的报表工具,功能之强大已经完全覆盖掉大部分企业日常办公数据呈现的需求,与excel不同的是,FineReport的部署结果是一个数据展现分析平台,背后是数据中心,能够实现数据的全管理,而excel专注于单机的数据分析。
机器学习
机器学习基础
聚类
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
在数据挖掘中,聚类也是很重要的一个概念。
传统的聚类分析计算方法主要有如下几种:
1、划分方法(partitioning methods)
2、层次方法(hierarchical methods)
3、基于密度的方法(density-based methods)
4、基于网格的方法(grid-based methods)
5、基于模型的方法(model-based methods)
当然聚类方法还有:传递闭包法,布尔矩阵法,直接聚类法,相关性分析聚类,基于统计的聚类方法等。
时间序列
时间序列(或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。构成要素:长期趋势,季节变动,循环变动,不规则变动。
种类:
绝对数时间序列
时期序列:由时期总量指标排列而成的时间序列 。
相对数时间序列
把一系列同种相对数指标按时间先后顺序排列而成的时间序列叫做相对数时间序列。
平均数时间序列
平均数时间序列是指由一系列同类平均指标按时间先后顺序排列的时间序列。
保证序列中各期指标数值的可比性
(一)时期长短***一致
(二)总体范围应该一致
(三)指标的经济内容应该统一
(四)计算方法应该统一
(五)计算价格和计量单位可比
推荐系统
定义:它是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程”。
推荐系统有3个重要的模块:用户建模模块、推荐对象建模模块、推荐算法模块。通用的推荐系统模型流程如图。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。
回归分析
回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;在线性回归中,按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多元线性回归分析。
文本挖掘
所谓PaaS实际上是指将软件研发的平台(计世资讯定义为业务基础平台)作为一种服务,以SaaS的模式提交给用户。因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。在2007年国内外SaaS厂商先后推出自己的PAAS平台。
IaaS
IaaS(Infrastructure as a Service),即基础设施即服务。
消费者通过Internet 可以从完善的计算机基础设施获得服务。这类服务称为基础设施即服务。基于 Internet 的服务(如存储和数据库)是 IaaS的一部分。Internet上其他类型的服务包括平台即服务(Platform as a Service,PaaS)和软件即服务(Software as a Service,SaaS)。PaaS提供了用户可以访问的完整或部分的应用程序开发,SaaS则提供了完整的可直接使用的应用程序,比如通过 Internet管理企业资源。
Openstack
OpenStack是一个开源的云计算管理平台项目,由几个主要的组件组合起来完成具体工作。OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。OpenStack通过各种互补的服务提供了基础设施即服务(IaaS)的解决方案,每个服务提供API以进行集成。
OpenStack是IaaS(基础设施即服务)组件,让任何人都可以自行建立和提供云端运算服务。
此外,OpenStack也用作建立防火墙内的“私有云”(Private Cloud),提供机构或企业内各部门共享资源。
Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。Docker 容器通过 Docker 镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。