【51CTO.com快译】
物联网数据有望发掘独特的、前所未有的业务洞察力,不过前提是企业能够成功地管理从众多物联网数据源流入的数据。许多企业试图从物联网项目获得价值,但经常遇到的一个问题是数据漂移(data drift):源设备和数据处理基础设施经常发生不可预测的变化,因而导致数据的结构、内容或含义发生变化。
无论流式处理还是批量处理,数据通常经由众多工具,从数据源进入到最后的存储位置。这条链上任何地方的变化都会导致下流系统中出现不完整、不准确或不一致的数据,无论是源系统的模式发生变化、编码字段值的含义发生变化,还是参与数据生成的软件组件出现升级或添加。
这种数据漂移的影响可能危害特别大,因为它们常常长时间没有被发现,因而让低逼真度数据污染了数据存储和随后的分析。在被发现之前,使用这种有问题的数据会导致错误的发现结果和拙劣的业务决定。等到最后发现了问题,通常借助数据科学家的手动数据清理和准备来加以解决,这给数据分析增添了硬性成本、机会成本和延误。
StreamSets Data Collector
使用StreamSets Data Collector来构建和管理大数据摄取管道将有助于缓解数据漂移的影响,同时大大缩短花在数据清理上的时间。我们在本文中将逐步介绍一种典型的使用场合:实时摄取物联网传感器生成的数据,馈入到HDFS,以便分析,并使用Impala或Hive实现可视化。
不用编写一行代码,StreamSets Data Collector就能从众多数据源摄取流数据和批量数据。StreamSets Data Collector可执行转换,并在数据流传输过程中清理数据,然后写入到众多目的地。管道部署到位后,你就能获得细粒度的数据流度量指标、检测异常数据,并发出警报,那样你就能密切关注管道性能。StreamSets Data Collector可以独立运行,也可以部署在Hadoop集群上,它提供了支持众多类型的数据源和目的地的连接件。
下列使用场合涉及从货运集装箱实时生成的数据。
数据漂移的第一个例子体现在货运集装箱使用的物联网传感器。由于长期以来的升级,生产一线的传感器运行三种不同固件版本中的一种。每种版本添加新的数据字段,改变模式。为了从该传感器数据获得价值,我们用来摄取信息的系统必须能够兼顾这种多样性。
清洁和传送数据
我们的管道从RabbitMQ系统读取数据,该系统负责从生产一线的传感器接收MQTT消息。我们进行核实,确保我们收到的消息正是想要处理的那些消息。为此,我们使用数据流选择器处理程序,为入站消息指定数据规则。然后,我们使用该规则宣布与该规则的标准匹配的所有数据都传送到下游,但是不匹配的任何数据一概被丢弃。
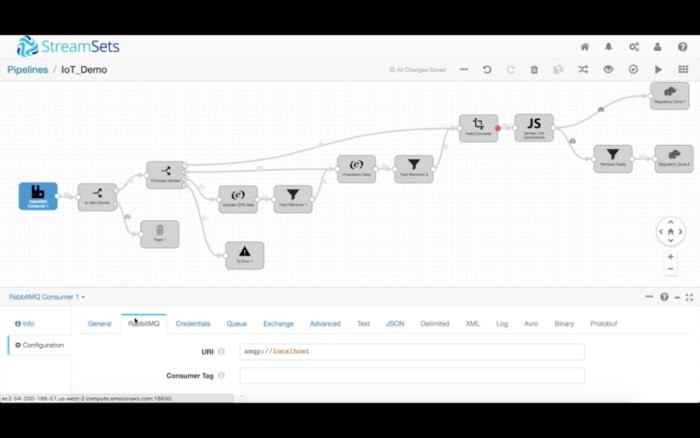
然后,我们使用另一个数据流选择器,根据设备的固件版本来传送数据。与版本1匹配的所有记录走一条路径,与版本2匹配的所有记录走另一条路径,以此类推。我们还指定了一条默认的全部捕获(catch-all)规则,将任何异常发送到一条“错误”路径。针对现代数据流,我们完全预料到数据会出现意外的变化,于是我们设立了一种从容的错误处理机制:把异常记录引到本地文件、Kafka数据流或辅助管道。那样一来,我们就能保持管道正常运行,同时事后重新处理不符合主要目的的数据。
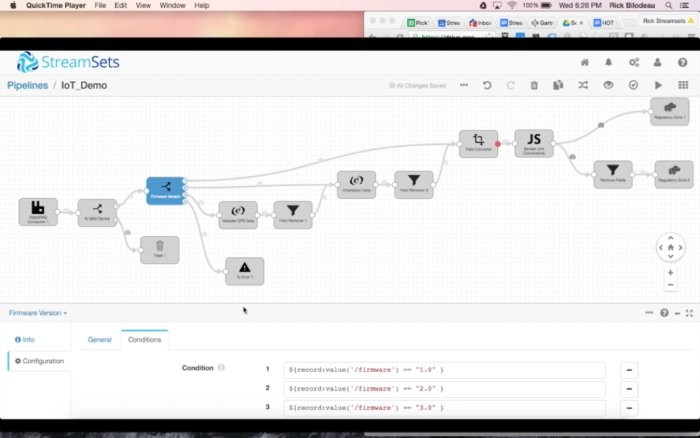
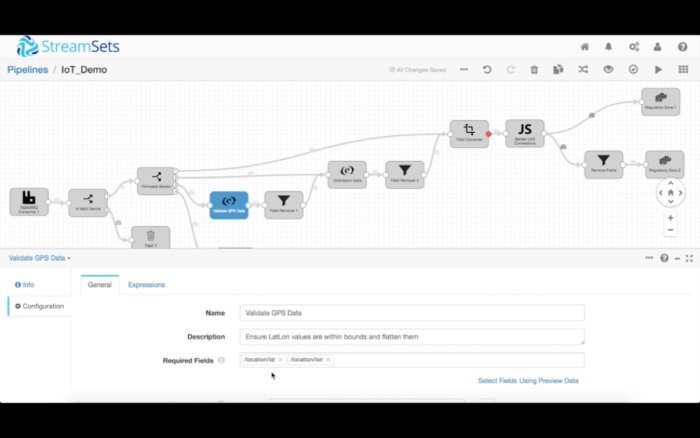
不妨从为固件版本3处理数据入手,这增添了纬度/经度数据。我们马上想要确保那些字段出现在数据集中,而且数据包含有效的值。由于位置字段是一个嵌套的结构,我们想要对它作扁平化处理,最终丢弃嵌套的数据。
同样,固件版本2包括新的方位字段(raw、pitch和roll),我们可以以一种类似的方式来核实和清洁它。
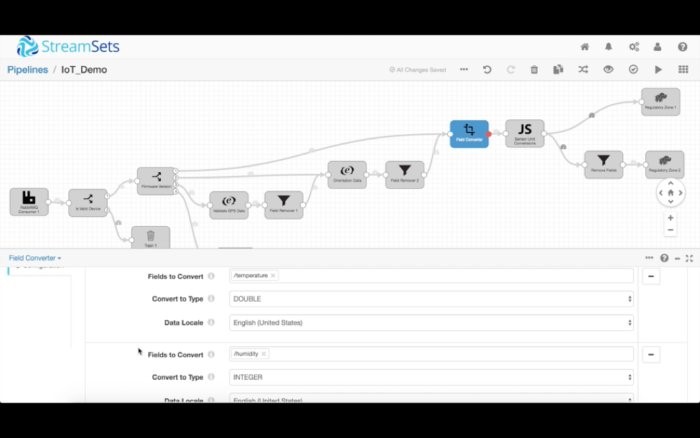
最后,所有设备版本都包含温度和湿度读数。首先,我们转换这些读数的数据类型。湿度转换成了双精度浮点型(double),湿度转换成了整型(integer),日期转换成了Unix时间戳。
然后我们使用脚本处理程序来编写一些自定义逻辑,比如将华氏度值转换成摄氏度。StreamSets脚本处理程序支持Jython、Groovy和JavaScript。
清理数据(也就是根据固件版本和最终用途来传送数据)后,我们把它发送到几个HDFS目的地。
配置目的地
StreamSets本身支持许多数据格式,比如明文、分隔文本、JSON、Protobuf和Avro。在该例子中,我们将把数据写入到一个经过压缩的Avro文件。
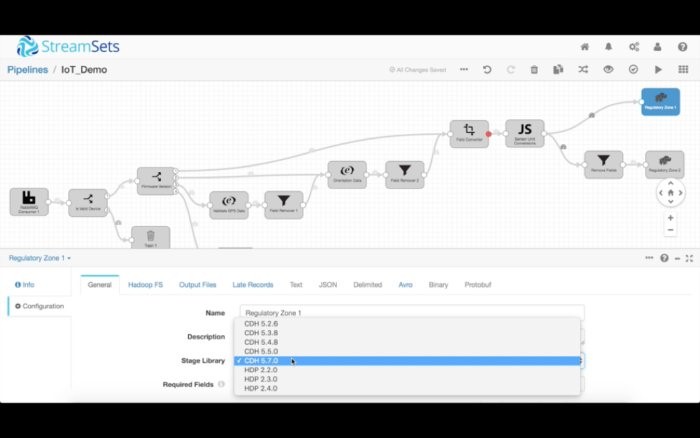
HDFS目的地可以灵活配置。你可以按照企业政策的要求来配置安全、动态配置输出文件的路径和位置,甚至决定写入多个Cloudera CDH版本。
一旦你设计好了管道,就可以切换至预览模式,使用数据样本来测试和调试数据流。你可以逐步调试每一个处理程序,在任何阶段分析数据状态。
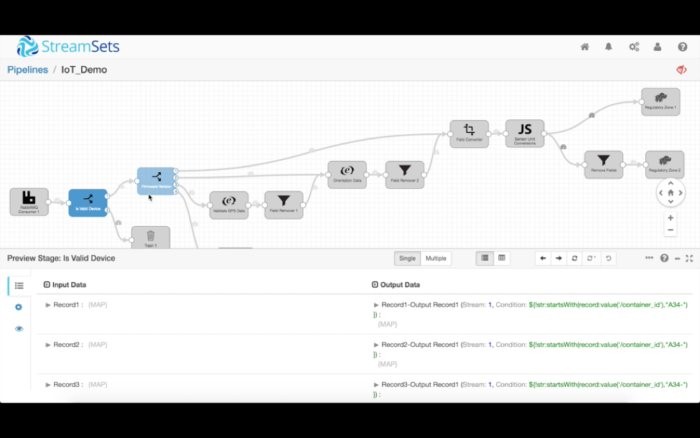
比如说,我们可以在下面看到,reading_date和temperature的数据类型被转换成了长整型和双精度浮点型。如果执行了转换数据的运算,StreamSets也会提醒你。
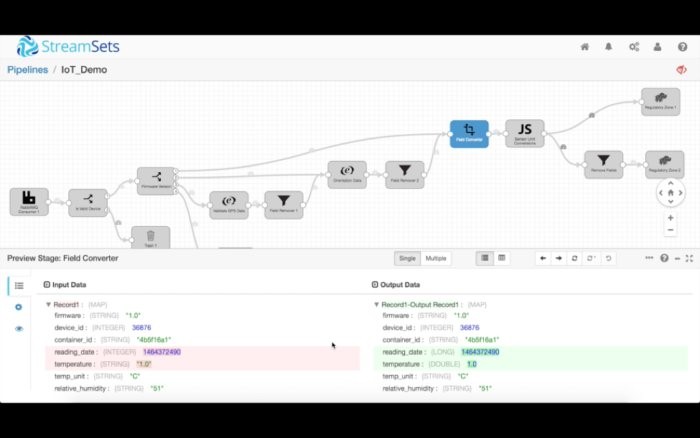
你还可以把异常或“极端情况”数据注入到数据流,看看它对你的数据流有何影响。预览模式让你可以轻松地调试复杂的管道,不需要把管道放入到生产环境。
执行管道
现在我们准备执行管道,开始将数据摄入到我们的集群中。点击“开始”按钮,用户界面就会切换至执行模式。
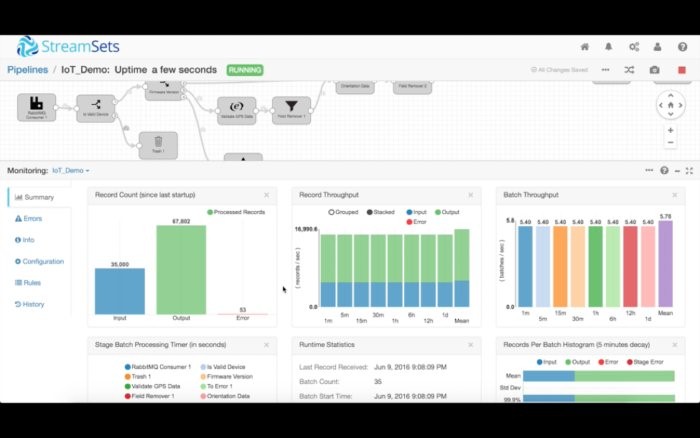
这时候,StreamSets Data Collector开始摄取数据,在内存中处理数据,然后将数据发送到目的地。屏幕底部的监控窗口显示了各个实时度量指标,比如多少记录读入、多少记录写出。你还可以查看多少时间花在了每个处理程序上,它占用了多少内存。这些度量指标以及更多的指标还可以通过Java管理扩展(JMX)来加以访问。
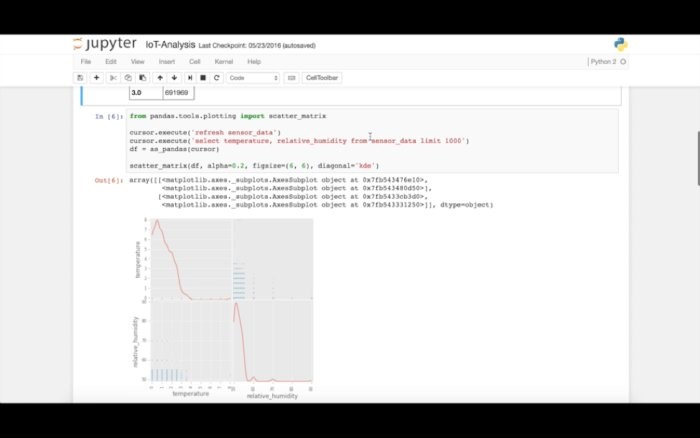
我们将数据送入到HDFDS后,立即就能开始查询Impala,并运行分析、机器学习或可视化。
如今,由于用户改动和更新系统,或者甚至更换平台,物联网设备、传感器日志、Web点击流及其他重要数据源在不断变化。数据内容、结构、行为和含义的这些变化是不可预测、未宣布、没完没了的,它们会给数据处理和分析系统及其运营带来重大危害。StreamSets Data Collector有助于管理数据基础设施不断出现的变化,驯服数据漂移,并确保数据处理系统的完整性。
原文标题:Tame unruly big data flows with StreamSets,作者:Arvind Pabhakar
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】