【51CTO.com原创稿件】企业规模不同,日志运维的方式就有所不同。在WOT2016移动互联网技术峰会上,来自新浪微博的资深系统开发工程师于炳哲,同与会者深入分析了小企业与大企业的日志运维问题,手机微博日志系统架构相关的调优,以及自己对日志运维的反思。
小企业日志运维
小企业日志运维关注点在于:成本、数据规模以及维护的难度。首先,我们来看看小企业在不同规模下的日志架构。小企业日志架构的特点:扩展相对简单、业务复杂度低、业务依赖度低、历史遗留问题相对较少,所以重构成本相对较低、可投入的资源相对较少。
其实对于小企业来讲可能都会经历几个阶段,首先是开荒的阶段,即是服务刚刚上线,还处于测试和开发的阶段。这时候,企业的应用可能就是布置一台或者两台服务器,此时没有必要做一套完整的日志架构。用纯文本 + grep + awk + sed即可完成日志的提取。如果使用传统的数据库,可以在开发中将重要数据直接写入数据库。或者使用第三方监控,采用业务接口监控(lua -> nginx shard dict -> DB(graphite))。
然后,进入数据增长阶段。此时的架构变成了分布式,也就是日志可能在不同的服务器上,业务也已经上线,这时候需要及时的反馈信息,需要专业的运维人员做日志架构设计。如下图的基于ALK简单的设计:
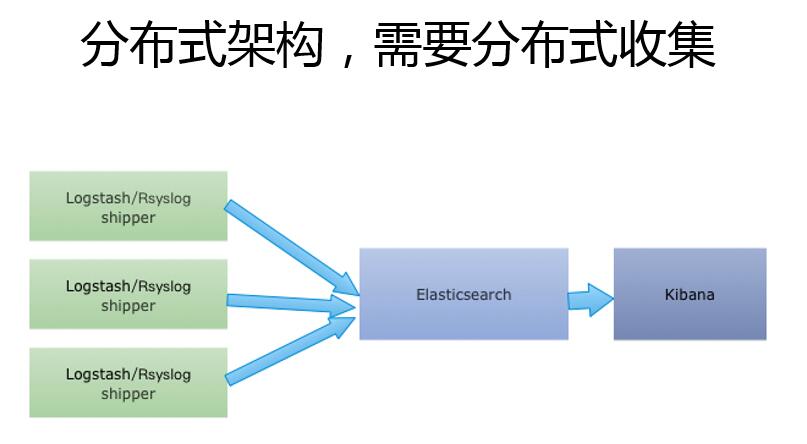
随着日志的逐渐增多,业务的逐渐扩展,进入了日志服务器中转阶段,此时需要收集的日志总量还未达到Elasticsearch(单数据节点)的写入量,企业对日志数据的安全性要求并不是特别高,同时对单点问题也不是很重视。在尽量少的运维投入下,希望快速构建。不要有太高的技术门槛。
这时候架构可能就会变成这样,这是一个大家中小企业,或者在50人以下,KPI在几万左右的厂商,基本就可以采用这种架构。就是说你的前面是日志agent,把日志直接写到日志服务器上,直接落磁盘。在这个上面用logstash或者其他的一些日志处理的组件,直接进行收集,把日志写到ES里。在这个阶段还没有到达一个ES的性能瓶颈,我一直强调的是在整个日志的架构当中不需要一下把这个架构架的特别***,而是要强调这种渐进的方式,因为成本是很重要的,对于小企业来讲。
这时提出了一个新的要求,就是前端服务器已无法承载增幅的日志量,日志需要统一归档,就此进入队列阶段。这时需要考虑数据安全问题,保障日志安全不丢失。同时需要一写多读。所谓一写多读就是你的日志架构是往一个地方写,同时有多个地方进行消费,比如说业务部门,或者是你的运维部门。
现在比较流行的一个日志处理的架构,前端也是agent写入,同时中间使用kafka或者redis这种缓冲的队列做相应的队列存储。然后通过logstash indexer,把这个数据写到ES里面,或者写到DB里面。同时我这里面用了kibana做一些数据展示。在这个里面你要考虑队列的选型问题,首先队列选型问题,如果使用redis可能涉及到一个成本的问题,它的内存,如果数据比较多的话,你的内存是比较昂贵的,在成本上面可能要考虑。另外还有一个是分布式的问题,如果你用redis进行分布式方面的话,它本身是不支持这种的,你可能需要一些其他的组件来做这个redis的分布式。其实我比较建议的是使用开包即用的kafka,它可以说是天生的分布式的队列,它是用磁盘做这种数据存储的,所以在成本方面也是相对比较低廉的。
在此,我想强调的是存储的扩展,比如说ES存储的扩展,这个可能是一个常用的、常规的一个扩展架构,就是一个分角色的架构。最前端用client,前面挂一个LB的方式做负载均衡,然后把数据写到client上。随后在client和ES的Node进行交互,同时使用master进行整个集群数据状况的一些保存。对于一些中小规模的企业,能做到这一步基本就够用。
***,对于小企业日志运维,我有以下几点补充:一是,一切架构设计都要以测试为先,同时做好监控。二是,涉及到logstash和Rsyslog的问题,logstash本身可能涉及到的它的整个日志传输,涉及到一些不可控的问题,它虽然是开源的,但是它很多的一些过程并没有很好的自带的监控,丢不丢日志,传输过程中有没有问题,实际上你是不知道的,你只能是通过业务两边进行对数。三是,Rsyslog提供impstats监控模块。impstats模块专门做事件级别的监控,已经精确到某一个事件是成功还是失败的这种监控,而且性能非常好。通过Rsyslog的rmpc的模块,我们可以做整个日志传输的监控。***,Elasticsearch的监控可以使用自带的插件。Elasticsearch的监控我推荐,如果是在人力投入并不是特别强的公司,可以直接完全使用它自带的一些插件,同时可以使用比如说Elasticsearchmabo这种插件。
大企业日志运维
大企业日志系统的特点和关注点在于:成本、运营与运维数据复杂性、历史遗留问题较多、各部门相互依赖、应对业务突增情况的能力以及丢失率监控&SLA(针对日志传输丢失情况的长久数据,都要保存到SLA里面,在SLA里面做一些你系统的一些评价,就是你这个系统到底靠不靠谱,其实是要用SLA来衡量的。)。
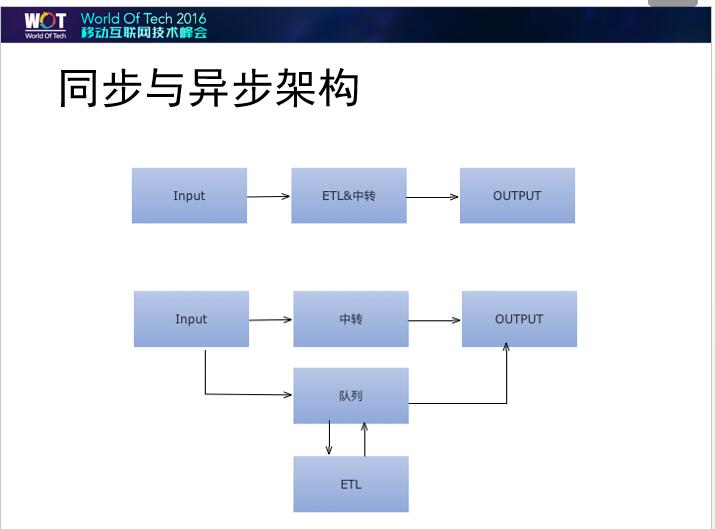
谈到大规模的日志传输,我们首先要考虑这个架构到底要怎么设计,到底是使用同步架构还是使用异步架构。什么叫同步架构?就是ETL、格式整理和转发放在一起。这会存在一个什么问题?如果整个业务比较平稳的话还好。但是如果业务突然间出现爆增等突发情况的时候,上面的架构就会出现问题。你需要解析的,可能就放在那个地方,后面的数据又转发不出去,前的服务发生了什么你可能根本不知道。此时,就需要把传输和解析进行分隔。
因此,我建议在设计日志传输架构的时候尽量设计成异步架构。
如何控制成本和优化业务呢?日志量越大成本就会越大,日志量大不是可以用来自豪的事情。可以用来自豪的是,你的成本做了多少意义的事情。在大企业的日志传输中其实存在很多垃圾数据,没有收集的意义。所以我们首先要做的就是对日志进行分类。然后就是对格式进行协定,对日志进行合并以及分级传输,实现运维侵入开发。
以Rsyslog为例,首先所有日志要有志tag,以其进行区分。然后需要高保的tag调用高保RuleSet,其他的日志tag以syslogfacility-text进行区分,通过syslogfacility-text来写入普通的通道。***使用rsyslog的action中的属性:action.execOnlyEveryNthTime实现按比例丢弃。
接下来,我重点介绍一下日志降级。日志降级是用来干什么的?在企业的业务量遇到突发情况的时候,需要对服务进行降级。为什么要降级?因为正常情况下,日志量处于一个比较平稳的状态,一点点的传。类似于某某明星离婚的时候,这个日志量就会爆增。为什么会爆增呢?首先日志是有一个特点的,在正常情况下可能就记录一下infor或者这些日志,但是如果出现错误的时候,这个错误量就会跟着这个业务量一样样的往上涨。这时就要考虑日志降级的问题,如果不降级的话,很有可能把下行带宽全部打满,遭遇计算量、带宽以及磁盘三个瓶颈。
以手机微博为例,我们来看看日志降级的逻辑。首先,就是要动态调整各个日志tag的级别。然后,它定义了两种级别:是否转发与是否落磁盘。

这是一个逻辑的图,这里面我们用了一个PHP的动态加载库,它可以把你相应的降级规则,就是对某一个日志,在需要降级的时候把它降到哪个通道里,把它降到哪个级别里的定义。然后我们会和监控进行连接,当监控发现某些业务突然出现突增的时候。这里面当然是基于规则,如果说这个规则满足的时候,就开始进行降级。
在大企业日志运维的情况下,我们需要注意,企业的日志传输是需要监控的,对于架构的每个环节都需要进行测试,主要是压测。此外,***通过队列解藕各个部门的依赖,并实现运维侵入开发,及时发现问题反馈给开发,发现开发中的不合乎规范的问题,并提供解决方案。
微博日志系统架构及相关调优
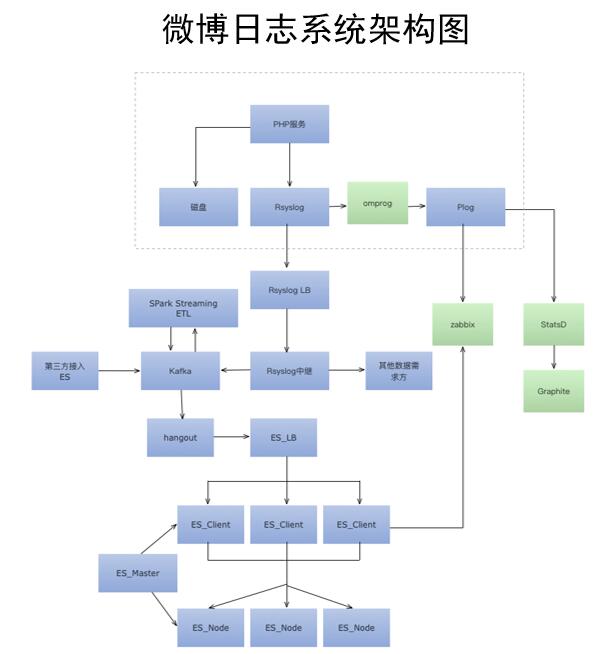
调优从来就没有一个标准的答案,所有调优一定要从内部了解系统开始,调优一定要基于测试与监控。下面,我们以Elasticsearch和Rsyslog的调优为例来具体了解一下:
◆Elasticsearch的调优
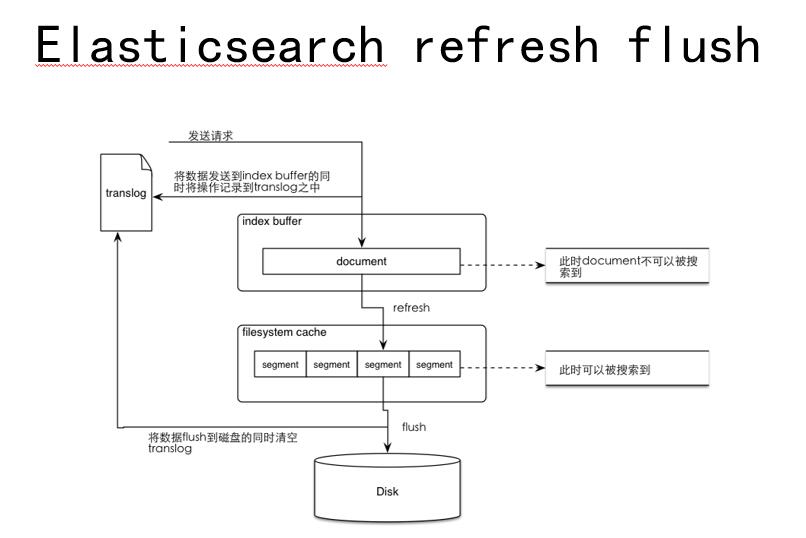
我们经常强调Elasticsearch的调优到底在调什么,我们首先要看一下一条数据写进来的时候是经过怎样的过程。首先是把数据写到index-buffer当中,在这个阶段你的数据还是搜索不到的。然后会有异步的程序把这个数据从index-buffer当中refresh出来,这个就是refresh阶段。一讲到Elasticsearch调优的时候,肯定大家就要讲到有一个调优项叫做index-buffer refresh,这个refresh的间隔时间。然后就到了这个flosystem cache这一层,到了这一层的时候你的数据是可以被搜到了,因为它可能就进行切分。***一步是磁盘操作flush,把数据从flosystem-cache刷到磁盘当中。进入disk层有个merge阶段,也就是说其实在ES当中是有一个异步的进程,Merge这个数据,就是把system进行合并,这个操作因为它是IO操作,它对性能的损耗是比较大的。再就是translog,它实际是一个数据库记录操作日志,把所有的对ES的操作首先先记到translog当中,如果在系统写入发生异常的时候,从translog把操作进行恢复。在flush写入之后,删除translog。
至此,我们可以看到,在写入的过程中,ES的性能主要merge、flush、reflush,还有translog的flush的阶段被消耗。了解到这个过程,我们就可以参照ES的官方文档,去对相应的各个阶段进行调优。当然首先要知道企业的性能状态,如果IO有问题就调merge,如果CPU的问题可以考虑在reflush方面做调整。
然后就是调优的方向,merge官方默认参数是按照SSD的磁盘来做的调优,实际它是不太适合机械磁盘这种服务的。因此,我建议如果涉及到IO问题,可以考虑把merge的进程数调低。在数据写入特别大时,采取网络限流。在内核层面,ES配置文件里含有了一些系统提供的很好的参数。
◆Rsyslog的调优
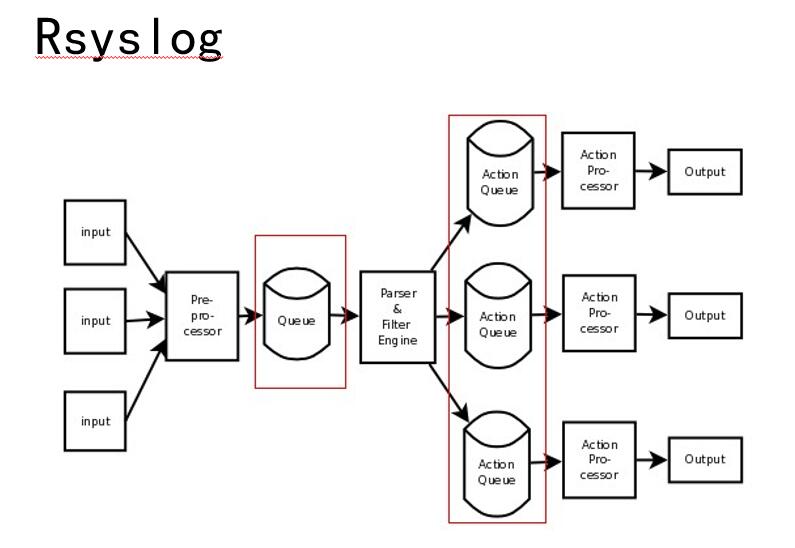
如图所示,这是Rsyslog一个内部队列,Rsyslog的内部也是比较复杂的。首先是input的这个进程,接着是预处理的阶段,比如它会进行一些分类,把你的某一个日志tag按照一个什么分类写到一个什么地方。再往后就是filter Engine,在这之前会有一个Queue,就是说这个数据在内部会维护一个队列,然后Filter到这个队列里主动拉取数据。后面是Action processor,它在前面也有每一个事件的队列,Action的进程会从相应的队列当中写数据。这就是的内部的结构。
Rsyslog主要有Main queue和Action queue两种类型的队列,四种队列设置,分别是:Direct queue、Disk queue、In-memory queue(LinkedList、FixdArray)、Disk-assisted memory queue。

总结
日志量就是成本,所以不要以花了多少钱而自豪,而是要以做了多少事作为目标。要传输有价值的数据!要多注意业务优化。此外,一定要记住:选择哪一种架构由具体的场景决定,不要过度设计,但要尽量快速迭代。
【讲师简介】
于炳哲,现就职于新浪微博-手机微博移动服务保障部,任系统开发工程师,负责手机微博服务端和客户端的日志收集、传输等工作,以及目前新浪网&新浪微博***的Elasticsearch集群的维护与相关中间件的开发维护工作。主要专注于日志相关技术,关注日志处理,传输,存储;等相关领域,对大规模数据量下的日志治理有一定的经验。曾就职于北京问日科技(365日历)从事Java服务端开发和日志处理,运维监控报警等相关工作。
本文由于炳哲于2016年8月,在WOT2016移动互联网技术峰会运维与安全专场《日志漫谈-不同规模下的日志运维与优化》主题演讲整理而成。WOT2016大数据峰会将 于2016年11月25-26日在北京粤财JW万豪酒店召开,届时,数十位大数据领域一线专家、数据技术先行者将齐聚现场,在围绕机器学习、实时计算、系统架构、NoSQL技术实践等前沿技术话题展开深度交流和沟通探讨的同时,分享大数据领域***实践和最热门的行业应用。了解WOT2016大数据技术峰会更多信息,请登陆大会官网:http://wot.51cto.com/2016bigdata/
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】