【51CTO.com原创稿件】
【讲师简介】
刘斌,道客巴巴在线文档分享平台联合创始人&CTO, 10年IT从业经验,擅长前端与服务器端开发技术、WEB服务器分布式集群部署、高并发调优、数据库性能优化。目前主要负责道客巴巴平台的架构与实现,10亿文档的分布式存储与数据挖据、服务器安全防护、文档智能分类技术与高性能分布式检索,为文档跨平台阅读提供解决方案。
道客巴巴是一个专注于电子文档的在线分享平台,用户在此平台上不但可以自由交换文档,还可以分享最新的行业资讯。是一个自由交流、平等学习、开放式的互动平台。从2008年成立以来,文档数据量已达10亿,从技术来讲,平均每个文档的大小是2兆,这样总共有2PB的空间。由于所有的文件要支持跨平台阅读,需要做一些数据挖掘的操作,所以所有的文件要经过处理生成目标文件。原始文件和目标,即文档本身,大约有6PB。同时还有一些网站的日志,其他的数据,大约有2PB,这样总的数据量是接近8PB。当然这个数据还没有做冗余,因为数据全部是多份存储的,所以可能还要乘以3。
面对如此庞大的数据量,如何保证它的存储安全,如何避免由于单机的故障导致的数据丢失,如何避免计算机的其他硬件故障导致服务停止,在10亿文档当中如何快速定位到用户所需要的文档,等等问题,都显得尤为重要。
文档的安全存储
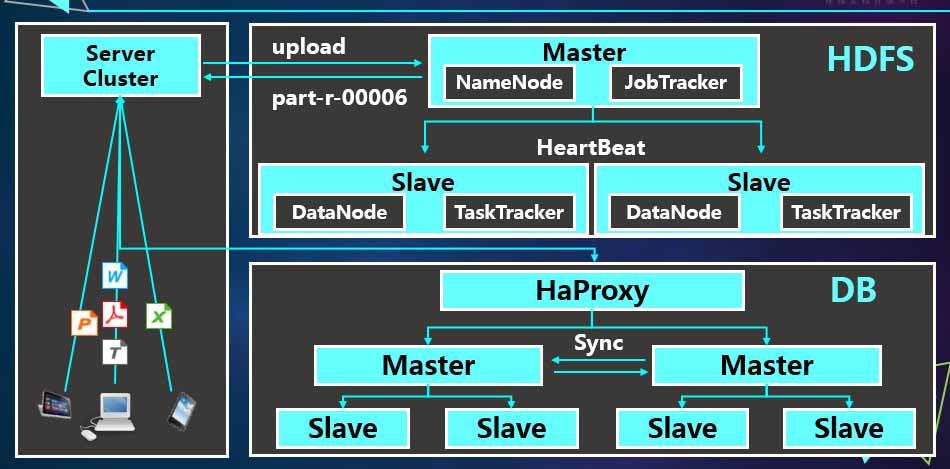
文档的安全存储
刘斌首先介绍了道客巴巴数据平台的总体框架。如果按照原始的方式,拿到文档直接写到linuxC盘的某个目录下,如果磁盘出现故障,数据就丢失了。即使做一个red5,当硬件出现故障时,数据还是会丢失。道客巴巴采用的方式是hadoop,hadoop是一个分布式文件存储系统,当用户传一个文件到集群服务器后,集群服务器本身也是一个客户端,到hadoop客户端。hadoop客户端大概是一个50个节点的集群,首先有一个master节点,master节点有两个服务,datenode服务和tasktracker服务。当传一个文件A传到服务器上的时候,首先要做的是把文件拆成三份,A1、A2、A3,同时每一份又保留多个副本,这个份数和副本保留在不同的节点。当用户请求文件的时候,平台从三台计算机分别读取这个文件,同时把结果汇总到节点,反馈给用户。这样一来,有效地利用了每台计算机的计算资源,以及它的IO,甚至是网络空间。保留多个副本是为了保证在任何情况下,数据都是安全的。
当拿到文件后,datenode会生成一个文件的标识:文件名。因为文档本身不仅仅是文件,还有属性,包括大小、上传人、时间的信息。道客巴巴使用的是原始的结构化的数据库。数据库本身也是一个负载,下面有两个主节点,这两个主节点是双面同步的,也是数据库的一个读写节点。同时每个节点下面又分摊了同节点,甚至在同节点下面还有一层其他同节点,这样可以保证在任何情况下,当单机数据库出现问题的时候,服务不会停止。同时客户端有一个数据库,也有一个检测,如果发现里面数据库出现故障,会连到其他数据库。所以平台所有的构架都是一个分布式的构架,这样就有效地避免了在任何情况下导致数据丢失的情况。
跨平台阅读
上传到网站的文档的格式可以是office、PDF,甚至是文本,而手机可能不会支持js阅读,或者没有office阅读。如何解决这样的问题?道客巴巴的做法是把所有的文档经过统一的转换,生成目标格式(jmflash或其他),这样无论是在手机还是在客户端都可以阅读。同时,对这个文档做了保护操作,除非上传者允许下载,否则是无法下载的。如果想用页面另存的方式下载,在连网的情况下有可能可以看,但是脱离网络后是看不到的,因为另存的仅仅是转换后的目标格式,它必须依赖道客巴巴的平台和软件,才可以阅读。
在客户端,用的是原生的方式来解析文档。解析的过程不需要访问网络,其性能、效率非常高。如果用户没有安装道客巴巴的客户端,就提供一个web平台,相当于一个网页版。网页版依然保留了原有的格式。
当把一个很复杂的PPT转化成目标格式时,会使用图片。根据手机的分辨率生成和用户手机分辨率匹配的图片。保证不管使用什么手机,或者pad,图片都是清晰的,在放大的时候,后端有一个集群的环境,对它在线实时渲染。道客巴巴收集了大约几十万的手机库,只要通过agent去访问的时候,能得到这个手机的物理分辨率,再根据物理分辨率生成相应的图片,这是道客巴巴网站的跨平台业务部分。
数据挖掘
跨平台阅读生成一个web的图片,同时会生成缩略图,这个缩略图就是为了让用户方便的预览这个文档,一般在列表产生模式的时候会采用这一步,最重要的一点就是文本提取,做数据挖掘,这是核心。同样这个目标文件也是保存到分布式存储服务里,所以目标文件也绝对是安全的,永远不会丢失的。
有些用户可能会上传一些非法文档,可能涉黄、涉黑、涉暴,这类的文档是不允许发布。道客巴巴有一个图片积累的几十万的非法词库,同时有一个文本数据,即分词的库,这个分词库包含一千多万的词库,同时分词的词库,也包含非法词库。当用户上传文档的时候,用词库对这个文本进行分词,单台计算机一秒可以做到50个,所以这一步非常快。如果分词结果在非法词库里出现了,这个文档就是非法的。
如果有些文档是一个图片,如何识别?ACR能识别一部分文档,为了确保非法文档不发布,道客巴巴又加了一个人工复合流程,由强大的审核团队对计算机没有过滤出来的文档进行再次过滤,这样就保证了发到平台的文档一定是优质的。
拿到分词数据后首先要做滤重。首先是进行MB5验证,如果MB5验证失败了,这个文档只保留一个副本。由于文档量相当大,所以要提供一个搜索的环境,用户可以快速地在这10亿文档中搜索到自己的文档。最后一步是核心的智能分类,如何在用户阅读某一篇文档的时候,洞察出用户所关心的是什么,之后就可以主动的对用户进行文档推送。
文档的分布式检索
此处的检索不是简单的标题检索,道客巴巴采取的是分布式的检索架构,大约有50个节点。录入的时候,把文档的分词结果录入到分布式搜索服务上,但这个分词结果和前面所说的一千万的分词结果是不一样的。例如,一个句子“我是中国人”,分出来的结果可能只有中国人是一个词。道客巴巴采用的方式是,把“我是中国人”做一个索引保存起来,“我”和“是”也不是两个词,以字为单位又做一个索引,保存到分布式搜索上。当用户检索文档的时候,指令发送到搜索服务器上,搜索的时候会把指令分发到不同的服务器,每个服务器大约从2千万的文档中进行检索,最终把检索的结果汇总到主服务器里面。然后主服务器再进行一些结果的排序、优化,把最优质的文档展示给用户。这就是检索的流程,只需几毫秒就可以完成。而做分片是为了保证数据在任何情况下都可以提供正常的服务。
当用户没有搜索到自己想要的文档的时候,道客巴巴会用人机结合的方式来解决。用户可以把自己的需求发到道客巴巴网站上,会有千万个用户协助完成。当然,这项协助是付费的。
文档智能分类
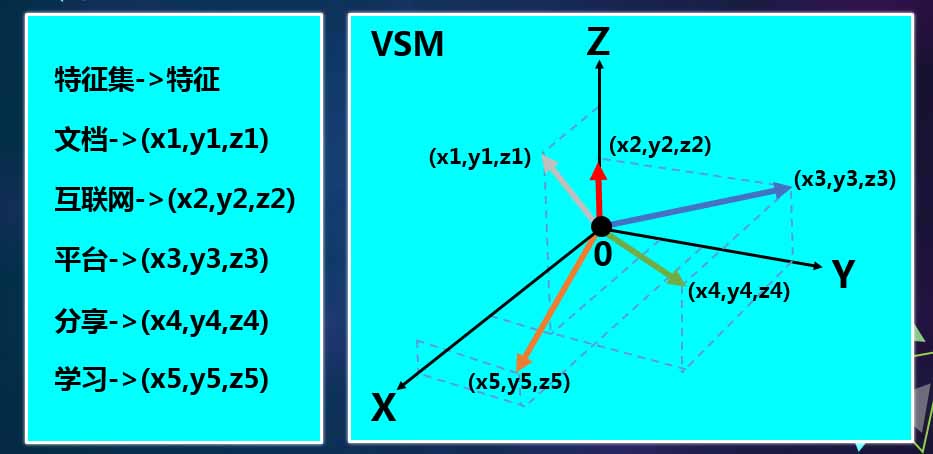
文档智能分类
如何将一个文档转换成一个空间项的模型是分类的目标,图中的模型是一个多维的空间,对于一个空间项的模型无非是有两个元素:特征集和特征值。特征集就是向链,特征值就是方向。分词有一个结果就是特征集。道客巴巴采用TFIDF的方案完成特征值。TF就是文本的词频。为了辨别哪些是对文档具有决定性的词,道客巴巴采用IDF的概念(逆向文本词频)。
把一篇大的分类看成一个文章。一旦做计算机预算的时候,道客巴巴采用的是一个平均分数的算法,用当前这个词的词频,减去miu,再除以西格玛,miu是平均值,西格玛是平衡差。
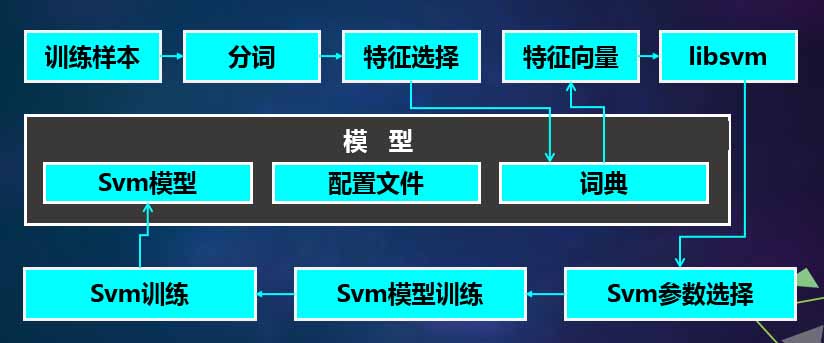
通过这两种方式,得到了一个模型。首先对样本进行训练,这个样本其实就是某个分类下的部分,文档。然后进行分词、特征选择。通过辞典能测出它的特征向量,就是得到SVM的中间向模型。采用SVM模型,得到所有分类的节点,就是所有分类的值。道客巴巴目前是2千个分类,每2千个分类之后就对应了这样一个数据。当有了这样的数据之后,就要拿到一个新的文档进行比较了。
对于新的文档首先也是进行分词,然后构造它的特征向量。这时候会到不同的分类,如何比较分类值?有两个分类向量模型,做运算其实就是除以以前的运算,但是有转到AV空间上是不一样的,有一个公式,算出来值如果越接近于1,文档就是属于这个分类的。实际上一篇文档可能是属于多篇分类。这就是进行分类的流程。得到这样一个结果后,在用手机访问文档的时候,可以分析出来用户所关注的是什么,通过这种分类算法,到库里面匹配,比如85%相似的文档会推荐给用户,这样大大提高了用户的阅读效果。

刘斌介绍说,这种算法在10亿文档中得到了考验,确实是有效的。同时,还有很多细节需要完善,他希望能与各位专家共同交流、共同进步,为互联网用户提供更优质、更便捷、更完善的服务。
本文由刘斌于2016年8月,在WOT2016移动互联网技术峰会数据分析专场《道客巴巴十亿文档的数据挖掘与应用》主题演讲整理而成。WOT2016大数据峰会将于2016年11月25-26日在北京粤财JW万豪酒店召开,届时,数十位大数据领域一线专家、数据技术先行者将齐聚现场,在围绕机器学习、实时计算、系统架构、NoSQL技术实践等前沿技术话题展开深度交流和沟通探讨的同时,分享大数据领域最新实践和最热门的行业应用。了解WOT2016大数据技术峰会更多信息,请登陆大会官网:http://wot.51cto.com/2016bigdata/
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】