最近数据库圈的一个比较大的事件是 NoSQL 先驱之一的 RethinkDB 的关张大吉,RethinkDB这个事情本身我就不多做评论了,现在这个时机去分析不免有马后炮的嫌疑,今天我想借着这个引子谈谈新型数据库的未来。

纵观过去十年数据库的发展,其实是相当迅速,随着互联网的发展以及业务数据量的不断膨胀,大家渐渐发现传统的单机RDBMS 开始出现一些瓶颈,很多业务的模型也和当初数据库设计的场景不太一样,一个最典型的思潮就是反范式设计,通过适当的数据冗余来减小 JOIN 带来的开销,当初 *-NF 的设计目的是尽可能的减小数据冗余,但现在的硬件和存储容量远非当年可比,而且存储介质也在慢慢发生变化,从磁带到磁盘到闪存,甚至最近慢慢开始变成另一个异构的分布式存储系统 (如 Google F1, TiDB),RDBMS 本身也需要进化。
在 NoSQL 蓬勃发展的这几年也是 Web 和移动端崛起的几年,但是在 NoSQL 中反范式的设计是需要以付出一致性为代价,不过这个世界的业务多种多样,大家渐渐发现将一致性交给业务去管理会极大的增加业务的复杂度,但是在数据库层做又没有太好的可以 Scale 的方案,SPOF 问题和单机性能及带宽瓶颈会成为悬在业务头上的达摩克利斯之剑。
NewSQL 的出现就是为了解决扩展性和一致性之间的矛盾,我所理解的 NewSQL 主要还是面向 OLTP 业务和轻量级的OLAP业务,大型复杂的OLAP 数据库暂时不在本文讨论的范围。对于NewSQL 来说,我觉得应该需要明确一下必备的性质,什么样的数据库才能称之为NewSQL,在我看来,应该有以下几点必备的特性:
- SQL
- ACID Transaction, 支持跨行事务
- Auto-scale
- Auto-failover
SQL 一切为了兼容性!兼容性!兼容性! SQL 的支持是和之前 NoSQL 从接口上最大的不同点, 但是在一个分布式系统上支持 SQL 和在单机 RDBMS 上也是完全不一样的,更关键的是如何更好的利用多个节点的计算能力,生成更好的执行计划,将计算逻辑尽可能的均摊到多个存储节点上,设计这样一个 SQL engine 的更像是在做一个分布式计算框架,考虑的侧重点和单机上的查询引擎是不一样的,毕竟网络的开销和延迟是单机数据库之前完全不需要考虑的。
不过 从最近几年社区的实现来看,尤其是一些 OLAP 的系统,已经有不少优秀的分布式SQL 实现 ,比如: Hive, Impala,Presto, SparkSQL 等优秀的开源项目。虽然 OLTP 的 SQL engine 和 OLAP 的侧重点有所不同,但是很多技术是相通的,但是一些单机 RDBMS 的 SQL 是很难直接应用在分布式环境下的,比如存储过程和视图等。正如刚才提到的,越来越多的业务开始接受反范式的设计,甚至很多新的业务都禁止使用存储过程和外键等,这是一个好的现象。
ACID Transaction 对于 OLTP 类型的 NewSQL 来说,最重要的特点我认为是需要支持 ACID 的跨行事务,其实隔离级别和跨行事务是个好东西,能用更少的代码写出正确的程序,这个交给业务程序员写基本费时费力还很难写对,但在分布式场景下支持分布式事务需要牺牲点什么。
本身分布式 MVCC 并不是太难做,在 Google BigTable / Spanner 这样的系统中显式的多版本已经是标配,那么其实牺牲掉的是一定的延迟,因为在分布式场景中实现分布式事务在生产环境中基本就只有两阶段提交的一种办法,不过呢,考虑到 Multi-Paxos 或者 Raft 这样的复制协议总是要 有延迟的,两阶段提交所带来的 contention cost 相比复制其实也不算太多,对于一个分布式数据库来说我们优化的目标永远是吞吐。延迟问题也可以通过缓存和灵活降低隔离级别等方法 搞定。
很多用户在进行架构设计的时候,通常会避免分布式事务,但是这其实将很多复杂度转移给了业务层,而且实现正确的事务语义是非常复杂的事情,对于开发者的要求还蛮高的,之前其实没有太多的办法,因为几乎没有一个方案能在数据库层面上支持事务,但是有些对一致性的要求很高的业务对此仍然是绕不开的。
就如同 Google 的 Senior Fellow Engineer,Jeff Dean 在 去年的一个会议上提到,作为工程师最后悔的事情就是没有在 BigTable 上支持跨行事务,以 至于在随后的 10 多年,Google 内部的团队前赴后继的在 BigTable 上造了多套事务的轮子以支撑业务,不过这个遗憾在 Spanner 中已经弥补了,也算是 happy ending。
其实 Spanner 的例子是非常好的,而且我认为 Google Spanner 及 F1 是第一个在线上大规模使用的 NewSQL 系统,很多经验和设计我们这些后来者是可以借鉴的。我认为,从使用者的角度来 说,滥用事务带来的性能问题不能作为在数据库层面上不支持的理由,很多场景如果使用得当 ,能极大的降低业务开发的复杂度。
Scale 作为一个现代的数据库,可扩展性我觉得是排在第一位的,而且这里的可扩展性值得好好说一 下,目前关系型数据库的扩展方案上,基本只有分库分表和 PROXY 中间件两种方案,但是这两种方案并没有办法做到透明的弹性扩展,而且到达一定规模后的运维成本几乎是指数级别上升,这也是大多数公司在微服务实践的过程中遇到的最大障碍,服务可以很好的做到无状态和解耦合,但是数据天然是有状态的,比较理想的情况是有一个统一的,通用的存储层,让服务层能够放开手脚。
弹性扩展的技术在很多 NoSQL 里已经有过很好的实践,目前比较成熟的 方案还是类 BigTable 式的 Region based 的方案,在 Key-Value 层面上实现水平扩展。另外值得一提的是,对于 NewSQL 这类需要支持 SQL 的数据库而言,region based 的数据切分是目前唯一的方案, 因为 SQL 的查询需要支持顺序 Scan 的数据访问方式,基于一致性哈希的方案很难支持高效的顺序访问。这
里隐含了一个假设就是真正能够支持 Scale 的 NewSQL 架构很难是基于中间件的方案,SQL above NoSQL 是目前来说唯一的可行方案,从 Google 的选型也能看出来。
基于中间件的方案的问题是中间件很难生成足够高效的执行计划,而且底 层的多个数据库实例之间并没有办法提供一个统一的事务语义,在执行跨节点的 JOIN 或者事务的时候没有办法保证一致性,另外底层的数据库实例(一般来说是 PostgreSQL 或者 MySQL) 本身并没有原生的扩展方案,需要中间件层面上额外做大量的工作,这也是为什么中间件的方案很多,但是做完美非常困难。
Failover 目前大多数的数据库的复制模型还是基于主从的方案,但是主从的方案本质上来说是没有办法脱离人工运维的,所以这个模型是很难 Scale 的 。如果需要做 Auto failover,从库何时提升成主库,主库是否完全下线,提升起来的从库是否拥有最新的数据?尤其如果出现集群脑裂的 状况,一旦 Auto failover 设计得不周全,甚至可能出现双主的严重故障。
所以数据的一致性是需要 DBA 的人工介入保证,但是在数据量比较庞大的情况下,人工可运维的规模是有上限的,比如 Google 在 F1 之前,维护了一个 100 节点左右的 MySQL 中间件集群支持同样的业 务,在这个规模之下维护的成本就已经非常高了,使得 Google 不惜以从零开始重新开发一个数据库为代价。
从 Google 在 Spanner 和 F1 以及现在流行的开源 NewSQL 方案,比如 TiDB 和 CockroachDB 等可以看到,在复制模型上都没有选择主从的模型,而是选用了 Multi-Paxos 或者 Raft 这样基于分布式选举的复制协议。
Multi-Paxos (以下出于省略暂用 Paxos 来指代,但是实际上两者有些不一样,在本文特指 Multi-Paxos) 和 Raft 的原理由于篇幅原因就不赘述了,简单来说,它们是高度自动化,强一 致的复制算法,在某节点故障的时候,支持完全自动和强一致的故障转移和自我恢复,这样才能做到用户层的透明,但是这里有一个技术的难点,即Scale 策略与这样的复制协议的融合, 多个 Paxos / Raft Group 的分裂、合并以及调度,以及相关的测试。
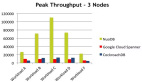
这个技术的门槛比较高 ,实现起来的复杂度也比较高,但是作为一个 Scale 的数据库来说,是一定要实现的,在目前的开源实现中,只有 PingCAP 的 TiDB 的成熟度和稳定度是比较高的,有兴趣的朋友可以参考 TiDB (github.com/pingcap/tidb) 的实现。
Failover 相关的另外一个话题是跨数据中心多活,这个基本上是所有分布式系统开发者心中的 圣杯。目前也是基本没有方案,大多数的多活的方案还是同步热备,而且很难在保证延迟的情 况下同时保持一致性,但是 Paxos 和 Raft based 的方案给多活提供了一种新的可能性,这类选举算法,只要一个 paxos / raft group 内的大多数节点复制成功,即可给客户端返回成功。
举一个简单的例子,如果这个 group 内有三个节点,分别在北京,廊坊,广州的三个数据中心,对于传统的强一致方案,一个在北京发起的写入需要等待广州的数据中心复制完毕,才能 给客户端返回成功,但是对于 paxos 或者 raft 这样的算法,其实延迟仅仅是北京和廊坊之间 数据中心的延迟,比传统方案大大的降低了延迟,虽然对于带宽的要求仍然很高,但是我觉得这是在数据库层面上未来实现跨数据中心多活的一个趋势和可行的方向。
按照 Google 在 Spanner 论文中的描述,Google 的数据中心分别位于美国西海岸,东海岸,以及中部,所以 总体的写入延迟控制在半个美国的范围内,还是可以接受的。
未来在哪里不妨把眼光稍微放远一些,其实仔细想想 NewSQL 一直在尝试解决问题是:摆脱人工运维束缚,存储层实现真正的自生长,自维护,同时用户可以以最自然的编程接口访问和存储数据。 当实现这点以后,业务才可以摆脱存储的介质,容量的限制,而专注于逻辑实现。
大规模的分布式和多租户是必然的选择,其实这个目标和云的目标是很接近的,实际上数据库是云不可或缺的一部分,不过现在的数据库都太不 Cloud-Native 了,所以如何和云更紧密结合,更好的利用云的资源调度,如何对业务透明的同时无缝的在云上自我进化是我最近思考得比较多的问 题。在这个领域Google 是走在时代前沿的,从几个 NewSQL 的开源实现者都不约而同的选 择了 Spanner 和 F1 的模型上可以看得出来。