这里是正文分隔线
1、先来扯扯大数据
互联网+概念的兴起,中国的创业者几乎把互联网+这趟车开进了所有领域,传统领域的商家人心惶惶,言必谈互联网+,仿佛不套点互联网的概念都不好意思宣传自家产品;而赶在这波潮流之前的正是燥热至今的“ 大数据 ”。
在这个上到各界研究机构、管理部门、企业,下到各大论坛、媒体、甚至商贩都能跟你聊“大数据”,你是不是觉得不拽点词儿都不敢出门。
可谁真正解析大数据背后的含义?从早期依赖结构化数据库的挖掘分析发展到现今海量、多源、非结构数据需要依赖并行算法才能解决数据的处理瓶颈,也事实上铸就了Hadoop、Spark这些技术脱颖而出;然而大数据所带来的数据噪声、真实性、完整性、解释性、误导性、合法性等等却都是不可忽视的挑战。
我们谈大数据,就像男人谈那玩意,似乎不加一个“大”就显得不够用似的,但骚年你要明白啊,科学证明,管不管用,还真不靠大。大固然可以吹嘘,但重点你还得问问家里的媳妇儿那啥感受呐( 污了… )。
小编觉得企业利用好数据修炼好内功才是重点,大数据是,小数据也可以是,深度学习是,普通数据分析也可以是。
那么不得不说的一个最核心的问题来了,在这个信息通达到任意一个生活碎片都可能产生海量交互数据的环境,除了Hadoop、除了机器学习,回归到数据的本源,你是不是可以和别人侃侃爬虫、侃侃Scrapy(读音:[ skreɪp ])
除了你的产品外,你真的拥有大数据么?
如何获取更广泛的外部数据?
是开放数据API接口?
还是几个半死不活的所谓数据交易市场?
显然太过局限,那么下面就来介绍下这个可以自定义获取几乎所有能被访问到的网站、APP数据的python爬虫框架-Scrapy。
目前,除了搜索引擎爬虫外,主流的被普遍大众所使用的技术有:
基于C++的Larbin;
基于Java的Webmagic、Nutch、Heritrix;
基于Python的Scrapy,pyspider;
基于Golang的Pholcus;
基于.NET的abot等等
如果从实用性和易懂的角度,推荐首选Python,一方面Python易于入门,各类开源库齐全,另一方面Scrapy的社区活跃,遇到问题可以及时找到答案。对于Python的2个爬虫技术,Pyspider有自己的操作界面,简单易用,但是帮助文档少,自定义空间有限;而Scrapy除了社区活跃,他的优点还在于其灵活的可自定义程度高,底层是异步框架twisted,并发优势明显(吞吐量高)。
2、什么是Scrapy
“ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 AmazonAssociates Web Services ) 或者通用的网络爬虫。”
以上是官方的说明,更详细地说,Scrapy是一个十分健壮、非常好用的 从互联网上抓取数据 的web框架。
它不仅仅提供了一些开箱即用的基本组件,还提供了强大的自定义功能。框架的学习规律就是修改配置文件,填充代码就可以了;
同样地,Scrapy只需一个配置文件就能组合各种组件和配置选项,并且可以级联多个操作如清理、组织、存储到数据库等。
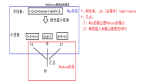
关于他的强悍,举个简单例子来说:假设你抓取的目标网站的每一页有500个条目,Scrapy可以毫不费劲地对目标网站同时发起 20 个请求 ,假设带宽足够,每个请求需要 1秒钟 完成,就相当于每秒钟爬取到20个页面,即每秒钟产生 10000个 条目数据 。再假设要把这些条目同时存储到云上,且每一个条目的存储需要3秒钟,那么处理20个请求就需要运行10000*3=30000个并发的写入请求,对于传统的多线程来说,就需要换成30000个线程,这显然地造成系统无法承载。而对于Scrapy,只要硬件够, 30000个并发也不是问题。
感受下爬虫程序运行带来的酸爽吧
3、Scrapy能做什么?
以上只是对Scrapy的一个简单的普及,事实上现在Scrapy已是一个主流的Python开源爬虫框架,它设计好了爬虫应用的基本骨架,使得用户不再需要配备大量的人力去重复造轮子,同时它也为了实现不同的应用目的留下了灵活的设计余地。使用一些其它的模块,或者配合一些中间件,可以将Scrapy扩展成为复杂的高级爬虫程序。
解决了这个顾虑后,能够发挥你的想象这有多可怕了么?当然你不会简单到认为爬虫也就是简单的爬下电影列表、图书这些吧!下面列举些小编认为可以操作的事情:
1 ) 舆情 :通过获取互联网的数据,监测舆论动向,评估事态发展并制定应对策略;
2 )热点 新闻 :监测全网新闻的数据,通过算法去监测每个新闻的转发、评论的单位时间增量趋势,发现潜在热点新闻/社会事件,以此来打造一个热点新闻源的供应商/产品也极有可能;
3 )对某类金融产品的检测和跟踪、上市公司的 年报分析 等,具体点说,已经有大神分享通过抓取雪球中粉丝量前5%的大V调仓记录,来建立量化策略实现过200%以上的收益,当然这也可能只是偶然;
4 )房地产,这个虐心又刺激的行业,可以通过爬虫获取到的 交易、价格等数据来分析未来的房产走势等等;
5 )当然也少不了来点污,作为宅男/宅女的你还可以做点羞羞的事儿,比如下面的图片,不用多展开了吧,赶紧操起键盘吧……。
以上只是简要列举一二,当然获取到的数据怎么分析也是一项不小的技术活,尤其是非结构化的文本数据的分析,推荐可使用些开源的jieba分词、SnowNLP等进行分析;这让小编想起了前几天老罗新发布的一项产品功能点—— Bigbang ,瞬间就能把一段文本语句炸裂成结构更小的词组,并达超准确的词组上语义分割,简单说就是分词技术已经可以应用到日常生活中,虽然这本身并不算什么新技术,但是这项具体的应用,让小编更加坚信了未来将会有越来越多的机器学习算法应用于生活中。
所以爬虫所能够带来更多的价值挖掘还请读者们大胆地发挥想象吧,小编已经不敢想下去了。不过小编还是提醒一句:
在你没有十足把握的情况下,不要尝试去摸一些重要部门的大门
“ 一念清净,烈焰成池 ;一念惊觉,航登彼岸”
4、关于Scrapy的一点唠叨
这个时候你是不是有个疑问:
人家有反爬虫技术啊,有Robot协议啊!
嗯,没错,事实上大部分情况下,反爬虫的需求是不能影响到网站的正常使用,一个网站功能性需求一定要高于反爬虫需求,所以大部分反爬虫一定不会恶心到正常用户的使用。也就是说,即使做了强反爬策略,爬虫依然可以伪装成人的正常访问行为,只不过是增加抓取数据的代价而已,而不可能做到百分百的防止爬虫。至于robot.txt只是约定,如公交车上贴着的【请为老弱病残孕让座】一样,遵不遵守完全在于爬虫作者的意愿。因此 爬虫与反爬虫的对弈,爬虫一定会胜。