在Google的三驾马车里面,Google File System是永垂不朽的,也是基本上没有人去做什么进一步的研究的。
BigTable是看不懂的,读起来需要很多时间精力。
唯独MapReduce,是霓虹灯前面闪烁的星星,撕逼战斗的主角,众人追捧和喊打的对象。自从MapReduce这个词出来以后,不知道有多少篇论文发表出来,又不知道有多少口诛笔伐的文章。
我曾经在HANA篇里写过围绕MapReduce,Google和Michael StoneBraker等等database的元老之间的论战。欢迎大家先读读这篇八卦文。为了避免重复,这篇文章里,我就不再展开这部分的话题了。
作为论文来说MapReduce严格的来讲不能算作一篇论文,因为它讲述了两件不同的事情。其一是一个叫做MapReduce的编程模型。其二是大规模数据处理的体系架构的实现。
这篇论文将两者以某种方式混杂在一起来达到不可告人的目的,并且把这个体系吹得非常的牛,但是却并没有讨论一些Google内部造就知道的局限性,以我对某狗的某些表现来看,恐怕我的小人之心觉得有意为之的可能性比较大。
因此当智商比较低的Yahoo活雷锋抄袭MapReduce的时候弄出的Hadoop是不伦不类,这才有了后来Hadoop V2以及Yarn的引进。当然这是后话。
作为同样抄袭对象的微软就显得老道很多。微软内部支撑大数据分析的平台Cosmos是狠狠的抄袭了Google的File system却很大程度上摒弃了MapReduce这个框架。
我们先看看作为编程模型的MapReduce。所谓MapReduce的意思是任何的事情只要都严格遵循Map Shuffle Reduce三个阶段就好。
其中Shuffle是系统自己提供的而Map和Reduce则用户需要写代码。Map是一个per record的操作。
任何两个record之间都相互独立。Reduce是个per key的操作,相同key的所有record都在一起被同时操作,不同的key在不同的group下面,可以独立运行。
这就像是说我们有一把大砍刀,一个锤子。
世界上的万事万物都可以先砍几刀再锤几下,就能搞定。至于刀怎么砍,锤子怎么锤,那就算个人的手艺了。 从计算模型的角度来看,这个模型极其的粗糙。
所以现在连Google自己都不好意思继续鼓吹MapReduce了。从做数据库的人的角度来看这无非是一个select一个groupby,这些花样197x的时候在SystemR里都被玩过了。数据库领域玩这些花样无数遍。真看不出有任何值得鼓吹的道理。
因此,在计算模型的角度上来说,我觉得Google在很大程度上误导和夸大了MapReduce的实际适用范围,也可能是自己把自己也给忽悠了。
在Google内部MapReduce最大的应用是作为inverted index的build的平台。所谓inverted index是information retrieval里面一个重要的概念,简单的讲是从单词到包含单词的文本的一个索引。我们搜索internet,google需要爬虫把网页爬下来,然后建立出网页里面的单词到这个网页的索引。
这样我们输入关键字搜索的时候,对应的页面才能出来。也正因为是这样,所以Google的论文里面用了word count这个例子。下图是word count的MapReduce的一个示意图。
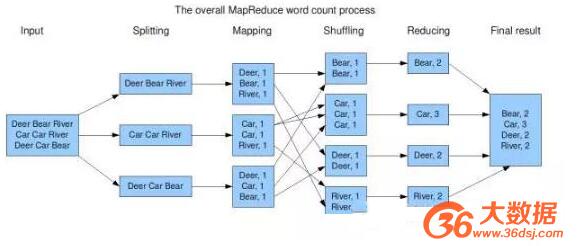
然而我们需要知道的是,Google后来公布的信息显示它的广告系统是一直运行在MySQL的cluster的,该做join的时候也是做join的。
MapReduce作为一个编程模型来说,显然不是万能的药。可是因为编程模型涉及的是世界观方法论的问题。
于是催生了无数篇论文,大致的套路都是我们怎么样用MapReduce去解决这个那个问题。这些论文催生了无数PhD,帮助很多老师申请到了很多的钱。
我觉得很大程度上都掉进了google的神话和这个编程模型的坑。 MapReduce这篇论文的另外一个方面是系统实现。我们可以把题目写成:如何用一堆廉价PC去稳定的实现超大规模的并行数据处理。
我想这无疑可以体现出这篇论文真正有意义的地方。的确,数据库的工业界和学术界都玩了几十年了,有哪个不是用高端的机器。
在MapReduce论文出来的那个时候,谁能处理1个PB的数据我给谁跪了。但是Google就能啊。我得意的笑我得意的笑。
所以Google以它十分牛逼的数据处理平台,去吹嘘那个没有什么价值的编程模型。而数据库的人以攻击Google十分不行的编程模型,却故意不去看Google那个十分强悍的数据处理平台。
这场冯京对马凉的比赛,我觉得毫无意义。 那么我们来看看为什么Google可以做到那么大规模的数据处理。
首先这个系统的第一条,很简单,所有的中间结果可以写入到一个稳定的,不因为单机的失败而不能工作的分布式海量文件系统。GFS的伟大可见一斑。没有GFS,玩你妹的MapReduce。没有一个database厂商做出过伟大的GFS,当然也就没办法做出这么牛叉的MapReduce了。
这个系统的第二条也很简单,能够对单个worker进行自动监视和retry。这一点就使得单个节点的失败不是问题,系统可以自动的进行管理。加上Google一直保持着绝不泄密的资源管理系统Borg。使得Google对于worker能够进行有效的管理。
Borg这个系统存在有10多年了,但是Google故意什么都不告诉大家,论文里也假装没有。我第一次听说是几个从Google出来的人在Twitter想重新搞这样一个东西。然而一直到以docker为代表的容器技术的出现,才使得大家知道google的Borg作为一个资源管理和虚拟化系统到底是怎么样做的。
而以docker为代表的容器技术的出现也使得Borg的优势不存在了。所以Google姗姗来迟的2015年终于发了篇论文。我想这也是Yahoo这个活雷锋没有抄好,而HadoopV2必须引入Yarn的很重要的原因。
解释这么多,其实是想说明几点,MapReduce作为编程模型,是一个很傻的模型。完全基于MapReduce的很多project都不太成功。
而这个计算模型最重要的是做inverted index build,这就使得Google长久以来宣扬的Join没意义的论调显得很作。另外随着F1的披露,大家知道Google的Ads系统实际上长期运行在MySQL上,这也从侧面反应了Google内部的一些情况和当初论文的高调宣扬之间的矛盾。
Google真正值得大家学习的是它怎么样实现了大规模数据并发的处理。这个东西说穿了,一是依赖于一个很牛的文件系统,二是有着很好的自动监控和重试机制。
而MapReduce这个编程模型又使得这两者的实现都简化了。然而其中很重要的资源管理系统Borg又在当初的论文里被彻底隐藏起来了。我想,随着各种信息的披露,我只能说一句,你妹的。
MapReduce给学术界掀起了一片灌水高潮,学术界自娱自乐的精神实在很值得敬佩。然而这个东西火得快,死的也快。所谓人怕出名猪怕撞。
同系列之: