












0x00 前言
随着漏洞缓解技术的不断发展,常用的一些漏洞利用手段如ROP变得越来越困难,来自ENDGAME的Cody Pierce发表了一篇[博客],称ROP的末日已经来临,新的漏洞缓解技术将有效应对未知的漏洞威胁,并宣布他们实现了一种全新利用硬件辅助的控制流完整性的防御机制——HA-CFI。
不过这种论调向来是要打自己脸的,因为总有新的漏洞利用方式出炉,永远不能低估黑客的想象力。比如Flash推出的一系列漏洞缓解机制中仍然存在漏洞,这就很尴尬了(CVE-2016-4249,详情可参考古河在HitCon上的演讲)。
知己知彼,百战不殆。只有充分了解新的漏洞缓解机制,才能有更好的思路去绕过,才能对未来发展新的防御机制更有启发。
0x01 控制流完整性
控制流完整性(Control Flow Integrity, CFI)是由加州大学和微软公司于2005年提出的一种防御控制流劫持攻击的安全机制。通过监视程序运行过程中的控制流转移过程,使其始终处于原有控制流图所限定的合法范围内。
具体的做法是分析程序的控制流图,重点关注间接转移指令,如间接跳转、间接调用和函数返回等指令,获取相应的白名单。在程序运行过程中对间接转移指令的目标进行检查核对,而攻击者对控制流的劫持会导致目标不在白名单中,此时CFI可迅速进行阻断,保证系统安全。
一般来说,控制流完整性可分为细粒度和粗粒度两种实现方式。细粒度CFI严格检查每一个间接转移指令的转移目标,但会严重影响程序的执行效率;粗粒度CFI将一组或相近类型的目标归到一起进行检查,可在一定程度上降低开销,但会使安全性降低。
0x02 基于硬件的CFI
早期一些CFI思路是基于二进制插桩的,最简单粗暴的方式是在每条控制流转移指令前插入检验代码,判断目标地址的合法性。但这种方式的开销实在太大,难以在实际中部署。因此研究人员提出的一些改进方法均在效率上进行了妥协,放宽了检查条件。实质上都是粗粒度的CFI,实际效果会打折扣,可被攻击者利用绕过。
既然CFI受制于效率,那么是否可以引入硬件机制来提高效率呢?毕竟相比二进制插桩的方式,硬件的开销几乎是可以忽略的,但前提是我们必须找到可行的实施方案。这就需要对处理器平台上的一些技术细节有所了解。
Intel为了让用户能够更好的对应用程序的性能进行优化,提供了一系列辅助调试的硬件支持,这里着重介绍LBR(Last Branch Record)、BTS(Branch Trace Store)和PMU(Performance Monitoring Unit),早期的一些研究都是在这些基础上开展的。
LBR
LBR是Intel提供的一组用于记录和追踪程序最近的若干次跳转信息的循环寄存器组,这些寄存器的数量与Intel处理器的微架构相关,在早几年的Haswell架构中有16个这样的寄存器,也就是说可以记录程序最近的16条跳转指令的信息(包括从哪跳转过来的,将要跳转到哪去),而在最新的Skylake架构中有32个。LBR寄存器的强大之处在于其定制性很强,能够过滤掉一些不重要的跳转指令,而保留需要重点关注的跳转指令。
BTS
BTS是另一个用于记录程序分支信息的功能单元,但与LBR不同的是,BTS不会将程序的跳转指令信息存储到寄存器中,而是将其存储至CAR(cache-as-RAM)中或是系统的DRAM中,这里就没有条数的限制了,只要空间足够,BTS可以存储大量跳转指令的信息。
但另一方面,BTS的时间开销要比LBR高出许多。
PMU
PMU是Intel引入的用于记录处理器事件的功能单元。PMU事件有好几百个,非常详尽,包含了处理器在运行过程中可能遇到的所有情形,例如指令计数、浮点运算指令计数、L2缓存未命中的时钟周期等。当然其中也有一个在HA-CFI中非常有用的事件,分支预测失败事件。
0x03 HA-CFI基本思路
如果大家对计算机体系结构稍有了解就会知道,现代处理器都是采用流水线的方式执行指令,而分支预测是保证其高效的一个非常重要的技术。
当包含流水线技术的处理器处理分支指令时会遇到一个问题,根据判定条件的真/假的不同,有可能会产生转跳,而这会打断流水线中指令的处理,因为处理器无法确定该指令的下一条指令。流水线越长,处理器等待的时间便越长,因为它必须等待分支指令处理完毕,才能确定下一条进入流水线的指令。分支预测就是预测一条可能的分支,让处理器沿着这条分支流水执行下去而不用等待。若预测成功,那么皆大欢喜,处理器继续执行下去即可;若预测失败,处理器则需要回退到分支位置,重新沿着正确的分支方向执行。
分支预测有许多种策略,如静态预测和动态预测等,当然学术界还有很多其他非常高端的方法。但无论采用何种方式进行分支预测,攻击者劫持指令流后,其目标地址显然不是处理器能够预测到的,必然会产生一个分支预测失败的PMU事件,这相当于一个预警信息,接下来要做的就是从这类PMU事件中甄别出哪些是正常的分支预测失败,哪些是由于攻击者劫持指令流造成的分支预测失败。
仅仅预警是不够的,HA-CFI还希望能够准确定位指令流被劫持的位置,并及时进行阻断。此时PMU就帮不上什么忙了,因为PMU只负责报告处理器事件,而不记录产生该事件的具体指令。当某一时刻PMU报告一个分支预测失败的事件时,此时的指令指针可能早已越过了跳转指令,很难回溯定位发生分支预测失败的指令位置。
因此,为了精确定位造成分支预测失败的指令,还需要借助LBR的帮助。当分支预测失败的PMU事件触发中断服务程序(ISR, Interrupt Service Routines)时,ISR将从LBR中取出最新的若干条间接跳转指令,其中必然包含造成分支预测失败的间接跳转指令。而且LBR中还记录了更为详细的信息,可方便ISR核对该间接跳转指令的目标地址是否在白名单中。若跳转指令的目标不在白名单之中,说明指令流可能遭到劫持,可及时阻断。示意图如下所示:

HA-CFI示意图
此外,为了进一步保证HA-CFI的效率,可以根据当前进程的重要性选择性的开启或关闭PMU,如当前进程为IE或Firefox浏览器时,开启PMU;若当前进程为Calc.exe这样不太容易遭受攻击的进程,则关闭PMU,如图所示:
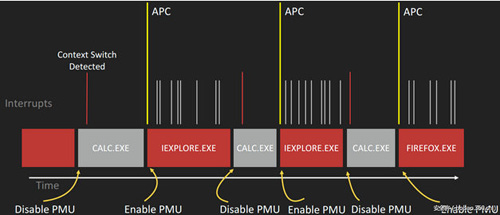
选择性开启PMU
0x04 效果与展望
Cody Pierce等人选取了多个经典的CVE漏洞,与EMET进行了比较:

实验结果1

实验结果2
可以肯定的是,随着对抗的不断升级,未来漏洞利用的门槛将越来越高,与防御机制斗法也将也成为常态。
除了刚才提到的微软的EMET,Intel在今年6月发布了一份关于CET的技术前瞻:[Control-flow Enforcement Technology Preview],准备从硬件层面入手防止ROP和JOP攻击。通过引入一个shadow stack(类似的[想法]几年前也有人提出),专门用于存储返回地址,每当发生函数调用时,除了向当前线程栈内压入返回地址,还要向shadow stack中压入返回地址。返回时需要检查线程栈中的返回地址是否与shadow stack中一致,若不一致,说明线程栈可能遭到攻击者破坏,程序中止。此外,shadow stack处于层层严密防护之中,普通代码是无法修改shadow stack的,除非攻击者能控制内核,当然这并非不可能,只是攻击门槛变得很高了。
CET目前仍是一个前瞻性的技术,距离真正实现还需要时间。即使实现了,也不意味着高枕无忧,HA-CFI也是如此,总有能绕过的方法,总有其未考虑到的情况,甚至可能它本身也存在着缺陷。













