那哲学上一般都会讲人生的三个终极问题:
- 我是谁
- 从哪里来
- 到哪里去。
其实要想做数据科学,也要关心三个问题,
1.数据科学或者数据科学家到底是什么含义
2.怎么才能走上这条路
3.怎么才能在这条路上一直走的很好

大家可以看到目录首先从多个方面去为大家介绍数据科学家这一岗位的方方面面,然后比较关心的是数据科学家的自我修养,怎么被需要被认可,怎么储备知识自我提高,最后简单地为迫不及待想要转型的IT架构师或者数据分析师提供一些小建议,进行数据科学家养成。
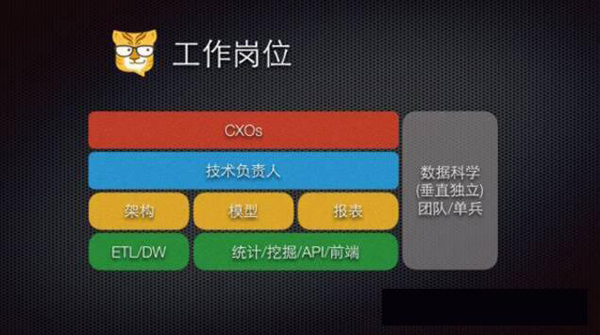
先来简单介绍一下这个岗位。
这个岗位在北美应该算是很流行了,国内一些公司我们更经常听见的是:
- 『数据团队负责人』
- 『大数据架构师 』
- 『算法工程师』
- 『高级数据分析师』
- 『数据挖掘工程师』
这样的岗位。可以看到这些人的职能离数据都很近。
但我对数据科学家的定义集中在『独立,垂直』。独立就是,他们要从产品、业务部门独立出来,垂直的意思是,要对数据的全生命流程负责,能够用对数据的分析、挖掘,为产品、数据流程甚至架构 带来全面改进,能够辅助决策,甚至直接创造价值的这么一个垂直团队,甚至是单兵。
有些人可能会说这是个伪命题,没有数据科学家的时候,公司也一样能做数据,也有数据团队,也有这些岗位啊?数据科学家又是个什么鬼?
我认为数据科学家应该扮演一种催化剂的作用,首先在开辟新领域时,要主动承担数据团队中出现的架构+数据清洗一类的基础性工作,达到自己在一线对数据理解、掌控的目的。然后,因为关心数据全生命周期流程,所以每个环节都可能是推动数据处理流程的优化的点。数据从哪儿来,质量如何?业务数据要做分析,必须经过哪些清洗和重构?使用什么样的工程数学工具进行分析?该以怎样的形式交给业务部门或者决策者?能够进行哪些辅助或者直接的决策?真是有种当爹又当妈的感觉。
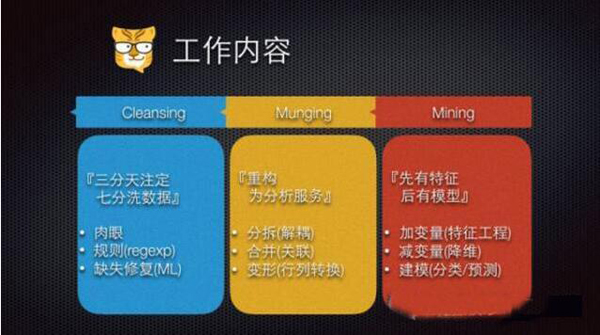
所以我们在这里展开点讲一些数据科学家的工作内容。我们得有垂直独立的思考模式,我们要迁就产品,但是决不能只用产品设计的思路思考数据分析。
一般来说,公司在最开始设计产品逻辑或者业务逻辑的时候,之所以做的粗放,是因为满足数据上收的条件下,搞好业务性能和用户体验就可以了。我设计一个系统,要求0.4秒以内返回结果,或者每秒接受上万次查询(qps),几千笔transactions,把功能点实现就好。如果在刚开始搞产品这一步就想做实时分析说查询和交易的背后有什么内在逻辑?那简直就是本末倒置,产品的生存第一位,数据都是先积累。
积累一定程度了,业务数据拿出来了之后,也根本不是说直接跑个逻辑回归跑个决策树,出个报告,下班回家这么简单的。
第一点就是要数据清洗。俗话说的好:做数据这一行,三分天注定,七分洗数据,也就是说,本来我们分析的数据潜在包含的信息就是有限的,你再不做清洗,什么也做不好。比如说有个字段是质量很差的身份证号码信息,其实身份证号足够恢复出这个人的出生地信息,生日性别,如果足够全的话,还能检查出这张身份证数据是不是假的。你不做清洗、不做信息提取,一定丧失了很多能够做预测的指标。
再比如LinkedIn上有很多公司的数据,如果本来是同一家公司,但是在系统里有10个uid,像高德,高德软件,高德地图等等等等,你不好好做人工标注,维护字典统一这些名称,就很难知道谁和谁有同事关系了。不仅仅是社交网络,跟文本相关的数据质量,不管是爬虫爬的还是买来的格式不好的数据,都需要非常大量的数据清洗,而且不懂业务需求是什么的时候,连清洗的质量把控、清洗的方式都不能做。数据清洗这件事重要到值得动用你的所有武器,从最原始的正则表达式,人肉修正脏数据,一直到最复杂的深度学习模型研究文本分类,再把文本中的词汇、语义、词性给提取出来变成新的feature,加入到特征库。所有这些都是需要清洗的内容。
第二点就是整合,熟悉各种SQL或者Pandas的朋友都很清楚,数据分析需要的数据跟业务数据 不仅质量有很大不同,而且组织形式也不一样。
比如广告行业里面有一个重要的分析叫做点击率预估,就是传说中的CTR预测,广告投放给一个批次的人,展示、点击、注册、付费大量的行为隐藏在同一个日志表里面,格式就是个行为+时间戳,但是你想分析转化漏斗,不可能不做拼接聚合。
这种问题还算简单,因为CTR这种问题你全量可以做,抽样也可以做。如果是做社群发现啊,PageRank,图模型最短路径等等类似的问题就不一样了。
你会发现,首先你得维护一个社交网络图,Twitter最早用HBase存稀疏矩阵,更多的公司用三元组表示图模型然后搞Spark GraphX或者使用Python的networkx。这种数据的重构不允许你基于一个原来图做抽样,你抽样了做,要么结果是错的,要么这不是一个能够开放给所有人的社交网络服务,讲的low一点,跟CTR比这更像是一个典型的『大数据问题』。
最后就说一下分析任务。像分类变量大家往往使用加工哑指标、进行one hot encoding的方式可能从业务系统里的几十个指标组合加工出上亿个特征,这说明一件事,你的业务数据可能1个节点数据存下了,很好啊,但是要做分析,不仅吃内存,而且中间数据可能要用到成百上千台的集群。
这种情况太正常了。这时有些受过正统统计学教育的人可能会认为刚才的做法太没有洁癖了。没关系,为了照顾到大家的洁癖或者预算不足,我们有很多降维工具,比如直接应用于数据列上的PCA/AutoEncoder可以留下数据中的重要信息,ISOMAP可以方便的帮我们做流形降维/ 而某些树模型除了能帮我们建立分类、数值预测模型之外,它的非叶子节点在优化多分叉的时候,也能天然的起到了降维的作用。加变量、减变量往往被称作特征工程 Feature Engineering,套用模型Data Mining实在只是最后最后的一个小步骤。
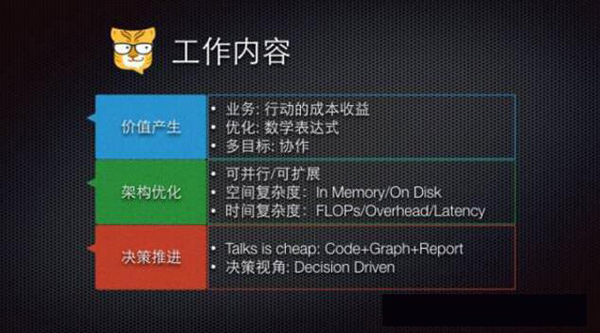
总之,这个岗位不是过来闹着玩的,是为了推动业务优化、是为了推动决策的,是为了产生价值的。产生价值说简单点不就是增加收入,节省成本吗?然后你的利润就来了。每一个业务决策、业务动作后面的成本和收益是多少?如何定义好优化问题?要动用多少人力物力,有什么样的约束条件达到什么效果,这是显性的。公司怎样节省自己的时间,客户的时间,带动产业发展社会进步,这是隐性的,都要考虑。
把优化目标用数学的方式表达出来,才能有好的结果。而且有时候我们会有多个目标。为什么百度全家桶另人讨厌?每一个部门都有自己的产品、自己的KPI,几个团队的leader私下一商量,打包出去推广,KPI是上去了,社会口碑一落千丈,所以不去预先协调多个目标、多个团队的协作,这种短视行为只能带来垃圾。
所以产生价值,这是数据科学家的内功,真家伙,能受用一辈子。
所谓数据科学家的外功,就是接地气,在后端能设计优化架构,在业务端能推动决策落地。
一个简单的分析,变不成一段系统中的SQL代码、一段Python代码,影响不了最终的决策,那就是什么都没有。这是很多人曾经面对或者正在面对的问题。另外,就算这些一切都好,一个算法能火的必要非充分条件是找到了做大规模并行化的思路,没有一个算法是只靠单机表现出色就能上线部署的,比如SVM 06-08年的实现了在线更新,比如11年随机梯度下降实现了无并行锁。 所以很多工程师、数据科学家都在研究算法的可并行性、扩展性。论证完之后他们就会用OpenMP,用Spark,用GPU的方案来实现。
不仅如此,对算法熟悉了,我们更要对数据熟悉,主要就是去了解一个算法牵涉到的数据量以及计算量。前者就是所谓的空间复杂度,我们要花多大内存或者物理存储来存放中间结果和最终结果?存进去能不能高效的读取出来?后者就是所谓的时间复杂度,CPU/GPU的算力能不能靠指令集优化提高?每次计算启动预处理和节点通信代价有多少?受指令集、缓存、内存、总线、网络的延迟多高?这些细节考虑和不考虑,做出来的结果天差地别。
最后的落地性就是以身作则的推进代码、图标、报告,对决策形成建议。学统计的人都会形成概率思维对吧,我观测到一个样本,属于A类的概率80%,属于B类的概率20%,但是决策者就不一样了,两条路只能选一条,压力很大。有一句话叫选择大于努力,而数据科学家做的事就是努力做出正确的选择。这种选择不仅依靠数据类的信息,也有非数据类的信息。因此,把难以数据化的信息给数据化,评估风险,才是正道。大家为什么现在推崇量化投资?如果你沾沾自喜于单独某一次选择的一夜暴富,那以后仍然还会一夜暴穷。量化投资也好,数据科学也好,都是为了更好的做选择。
综上所述,一个数据科学家可以有多种视角,给人感觉很酷。
数据科学家岗位活跃在什么行业?
传统行业,肯定有,而且需求很大。
美国邮政曾经优化了工作日程表,本来周一到周五上班周末两倍工资,变成了排班制度,自由选择合适的5天上班,一下在劳动力上节省了三亿美金,这个方案现在日本很多打工店都在用。
这就涉及到线性规划、整数规划。亚马逊至今还在做仓库选址和路径调度,因为它要安排仓库库存,安排送货嘛。所以地理数据分析,选址和TSP都得做。工程方案就更多了,比如滴滴今年这个算法竞赛,顾客和车辆的供需预测,所有打车、租车、代驾公司,一旦做到规模化了,都特别需要供需预测,这事儿2年前e代驾就在做。
做完供需预测,有的人就想我们设计一个运力调度中心,这个区域人多,你应该去这,另外一个区域车少,你应该去那儿。其实从工程角度讲,给司机看一个热力图解决了,redis存好司机实时位置和对接下来半个小时订单的预测,司机在app看到热力图,自己就往更容易接单的地方跑。做工程往往就特别需要这种巧劲。
互联网行业,是数据科学家的主战场。

09年netflix数据竞赛可能大家都清楚,其实就是为了解决一件事,给合适的用户在网上推荐合适的影片和电视剧,甚至自己主导往外推这些影音内容。为什么《纸牌屋》能火?因为大众喜欢的题材、喜欢的导演、喜欢的Kevin Spacey都凑一块儿了,这都是基于对用户的深入理解才能做的。竞赛结束之后,是个人就会讲协同过滤了,虽然真正实践svd,als的人少之又少,但互联网确实开始重视算法了。很久之前看过一本入门级的《推荐系统实战》我觉得写的比较全面,作者项亮老师至今活跃在算法一线。
如果说你开了一家公司,不是电商、垂直巨头这种流量+推荐的模式,你一样可以参与到广告行业里。这个行业国外商业模式非常成熟,广告主,需要竞价广告位投放;媒体流量主,需要优化广告位,进行用户行为研究,中间还有广告联盟,DMP这些平台,研究投放算法,采用田忌赛马的策略,虽然每个广告不都会投放给最适合看这个广告的那些人,但是总收益最大。对这方面感兴趣的推荐大家先看一本入门书《计算广告学》,作者是刘鹏老师。这里面涉及了广告行业的商业模式的架构和算法实践,算是个全貌性的介绍吧。
我个人有些偏见,认为广告行业做算法做不透,做的半吊子,首先PC端投放转化率千分之五,移动端转化率百分之五,能做到这个数字都要烧高香了,离所谓精准简直差的太远。 比如你耽误大家70秒的时间就为了一个广告的KPI,点击率千分之五,14000秒 4个小时的播放形成了1次点击,谋财害命对不对,也不好好学学国外怎么在广告上互动收集UGC,提高投放效果。
然后我是觉得相比之下,增长运营比流量运营更有价值。最近有个很潮的词叫growth hacking,自己做产品,上收数据,但是呢自己做简单分析太麻烦了,要有专业化的平台帮我们分析这些,拉动增长,降低成本。基本方法论就是漏斗图转化率,精细化一点的话Cohort Vintage Analysis,再精细化一点用户画像,为用户定制化他的核心体验,提高留存和持续付费。
从APP的sdk切入的Talking data,友盟都是比较老牌了,环信给app提供的多媒体社交sdk也是很棒的点,更多的厂家是在云端数据服务,光我接触到的,国内的百分点,Everstring,37degree,growing.io,美国Salesforce是做的比较久了,Ayasdi在最近美国融资榜上面排第二,核心算法、高性能计算、和数据可视化做的都很好,大家可以了解一下。说个题外话,融资榜第一的Sentient科技,是做机器人的。反正就人工智能圈子。
最后一点,一个好的数据科学家其实是适合做偏数据类的产品经理的。项目冷启动上收UGC、爬什么外部数据,是需要靠大局观,靠脑洞的,不是守着自己现有一点数据分析分析就足够了的。产品迭代的过程中,算法搞不定的时候也是有的,有时候拿A/B Testing结果说话更靠谱。

在前沿技术公司里面,很可能进来的人都有一个较高level的算法能力了,这样的一些横跨学界和产界人凑在一起,他们的核心技术就是拓扑、图论、数论、深度学习、强化学习这一套纯数学工具,很高的壁垒在这,他们在一起要么能够解决之前解决不了的问题,要么极大改善传统方法的效果,包括数据安全、OCR,图像识别、语音识别、文本理解、机器翻译、机器人等等。很多人在博士阶段就有一些专利了,然后很自然而然的就开始开公司。特别有名的,包括刚才提到的Ayasdi,Sentient科技,Deep Genomics等等。这种公司的核心团队往往不太可能和一个成长中的数据科学家共同成长,比较多的还是走学术产业化的道路,其实刚刚毕业的硕士,博士如果还喜欢在一线做工程的话,是特别适合加入这些团队的,国内就有几家,科大讯飞,商汤科技,等等就不赘述了。

所以洋洋洒洒总结一下,什么是数据科学家?
前面懂业务,中台证明自己的故事,底层写代码,算法的也写后端的也写。如果你是首席数据科学家,你不给自己公司站台,做技术型售前,你能指望谁能比你讲清楚你们的技术实力和商业模式?你不帮公司上收最数据,你想指望谁来做?
虽然对数据科学家的要求很高,但是也要看到几个点
数据科学家不是数学家。三百年前就有费马大定理,三百年后才证明出来,形成了厚厚一本论文集,捎带搞定了谷山志村猜想,这个猜想的证明打实了blockchain的基础。那你能说,我想设计个比特币,所以直接从证明猜想开始干吗?这么做的人肯定脑子有病。数学家更像哲学家,而数据科学家更像工程师,还是要记住解决问题,要把真实世界抽象成可解决的数学问题并亲自解决。
数据科学家也不像 IT 工程师,更像什么汽车工程师、飞机制造工程师。
IT工程师工作的完成,具有特别清晰的要求和标准,就像发动机制造,满足标准就是100分,不满足0分。但是对于数据科学家来讲,就好像造汽车造飞机:你把工作完成了,也不一定是及格的。如果你做的结论大家都知道,那就没什么价值,如果你的结论是基于错误的数据得到了反直觉的结论,我估计你马上可能就被解雇了。如果你的结论很棒,算法也很棒,但是工程实现不行,那就是大写的尴尬。
因此你要特别善于在大家不关心的点找出新的思路来分析,提高数据的价值,对主动学习的要求非常高。就好像造电动车,电池你得管,结构和抗碰撞能力你得管,外观好不好看好不好卖你得管,发动机当然是关键的一环,你可以不亲自去造发动机你可以买,但是发动机买来了带不带得动整车重量,你就得背锅。
如果公司有数据文化,并愿意维护一个做实事的数据科学家岗位,而不是打嘴炮的团队,是相当值得珍惜的。之所以这么说呢,是因为,有些公司,它压根没有数据科学家。排除掉无法看到数据价值的传统行业,还是有公司没有。所以我们就面对一个新问题……