【51CTO.com原创稿件】在WOT2016移动互联网技术峰会平台技术专场,TalkingData 研发副总裁马骥先生给我们带来了《地图可视化Client Service架构设计及实践》的精彩演讲,与参会的朋友共同分享了地图在大数据领域当中的应用和如何通过数据可视化进行数据挖掘、探索以及数据决策等精彩内容。
TalkingData成立于2012年,目前已经进行了 C轮融资,并正在启动D轮融资。截止到现在, TalkingData已经积累了30多亿移动开发数据,我们的产品主要围绕三方向:一是面向于开发者服务,二是应用统计分析、三是广告监测。TalkingData公司总部设在北京,在上海有研发中心,深圳有一个办事处。此外,还在国外设置了一些分资机构。
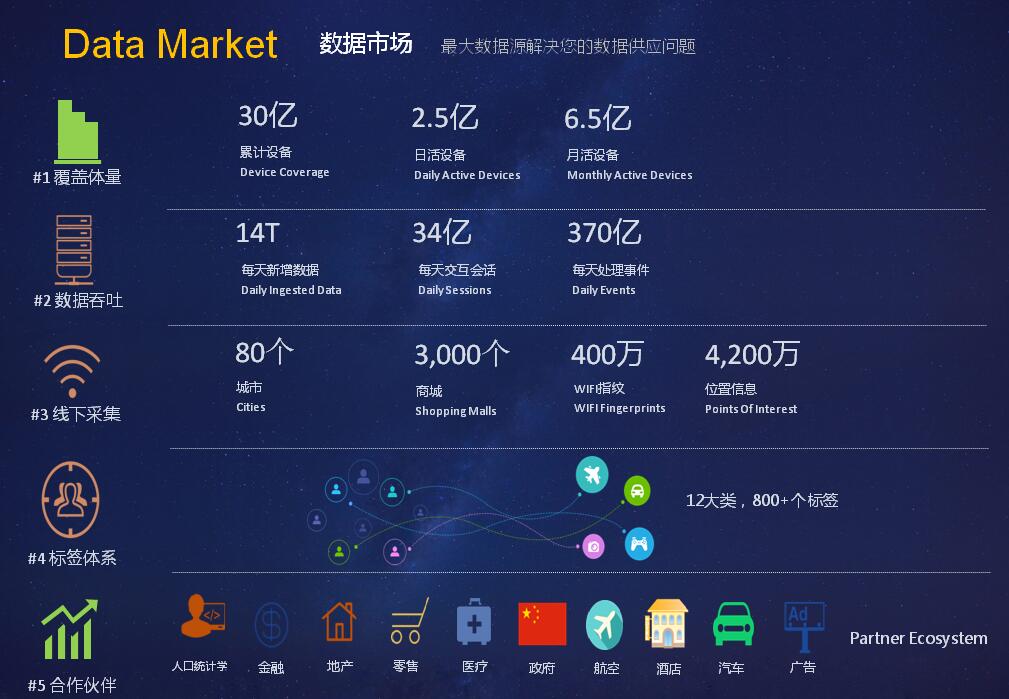
谈到当前的数据市场,马骥先生认为,当前数据体量积累了大约有30亿设备,日活2.5亿,月活6.5亿,每天吞吐能力大约14T,交互会话34亿,处理事件300多亿。WIFI数据覆盖了80个城市,3000多个商场,WIFI指纹有400多万,POI数据是4200万。另外,围绕这些数据有各种标签800多个。他表示,在大数据时代地图的发展出现了一些瓶颈,如何解决地图在大数据领域中的使用是一个非常重要的课题。
针对这一课题,TalkingData公司研发出一套完整的解决方案。首先,是绘制引擎TD Seagull,因为地图数据和PVI数据对于任何一家公司都是很有价值的,需要各种保护、防破解,我们同样采用这样的方案,把加密数据拿过来,前端解密。另外,如何把数据压缩更小,有一套压缩算法解开。
在Client端和Server端,500万数据放到前端明显完不成,肯定是前后配合做。解决办法最重要的是这两块:***, 500万个点的数据,在全国视野内是否给5000个点就能把500万个点表示出来,甚至给500个点是不是也能够把上面的地图表示出来。我们认为,这完全是可以的,当然把500万个点提取出5000个点或者500个点,如何把特征点弄好,就要有数据聚合服务。第二,大量数据在放大之后很大全国的数据是没有用的,在打开地图放大到一定级别后只显示可视区内或者需要绘制的数据,返给前端是不是可以?答案是的,这是最重要的解决办法。例如,用围栏计算,画一个围栏,海淀区有多少数据需要计算。另外,大部分都是即时服务,坐标转换,因此涉及到转换有N多种坐标体系。几何计算如何判断一个点是否在围栏内,好像很简单,其实真的蛮复杂。500万个点如何判断围栏?本身有100个点,这件事情很复杂。这个方案是后端到即时N多服务,把数据提炼出来,吐到前端,前端做解密、压缩,通过地图各种热力图API显示出来,这是我们最初的一套方案。
当然,在这套方案中我们也发现有几个问题:***个问题是后端开销比较大,系统开销很大,计算能力对内存、对CPU计算很大。另外,SLA性能,一个请求是否能在一秒内把数据接口不是返回接口,而是返回到前端来,系统是否能够支撑。这就造成硬件投入比较多,但是有些行业客户需求点很小,需要加一套即时服务,对成本来说有问题,即时服务硬件投入很大 如何解决这个问题?简单的办法是前端能否有更多的事情,这是一个很正常的思维,如何把后端服务放到前端做,或者能否前后端协同做,这样就降低了后端的技术复杂性。
另外一个问题是把后端服务拿了出来,上移到前端客户端浏览器。由于数据聚合浏览器完全可以做,围栏计算、坐标转换,很多都试图想要浏览器承担减轻后端的服务,甚至有些后端服务可以不做了或者少做点。
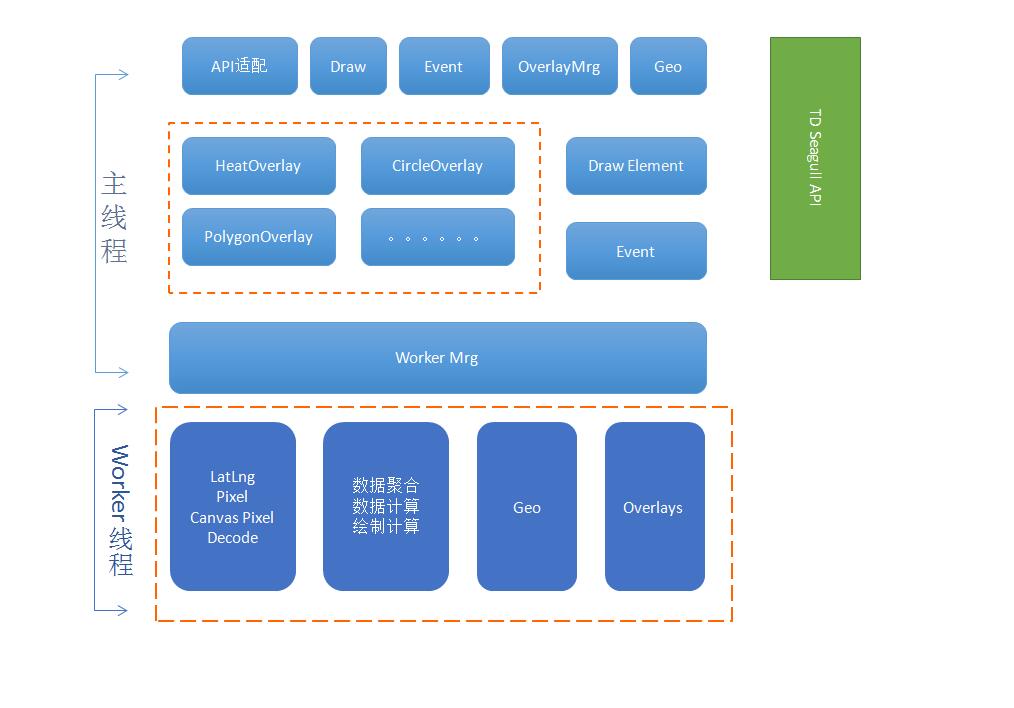
TD Seagull面临的挑战主要来自几个方面:***个方面是前端绘制,现在前端的解决方案还是很多的,不做细说。第二个是Client端的问题,大量数据导致整体地图拖拽非常卡顿,甚至致使浏览器崩溃了。 Client绘制极限值能做多大,如果容器就是一万、几千,没什么可谈的,如果能够更大可能会更好,但是面临的问题也会很多,比如地图拖拽一下或滑动一下,可能都需要有N多计算。计算复杂度和算法逻辑,前端GS做地图很有意思,真的有很多算法逻辑,但是导致的结果是这块带来的问题也会比较多。前面是原因,后面是表象,这个表象对于用户的体验很差,GS的执行原理是单线程的,很容易有大量的计算在,执行效率在,很容易堵塞后面脚本咨询,除了卡顿现象都是因为这种问题导致的。
既然把服务往上移,如何提升计算能力,成为处理架构设计最核心的。前端经过十几年的发展,H5做了很多,大家也经常提到MVC,为什么前端的M层很薄?甚至有的根本没有M层?为什么前后端分离的标准,前端是负责展现逻辑,后端负责业务逻辑?当然,现在有些客户端很多的业务逻辑逐渐往前移。但是,在计算能力方面,前端一直以来是弱的,原因很简单,既然是一个单线程的,意味着只能利用好一个CPU,现在手机都多核了,前端GS执行没有充分利用好CPU资源,可以得出这个结论。H5的发展各种解决方案出来了,做前端的已经很清楚了。
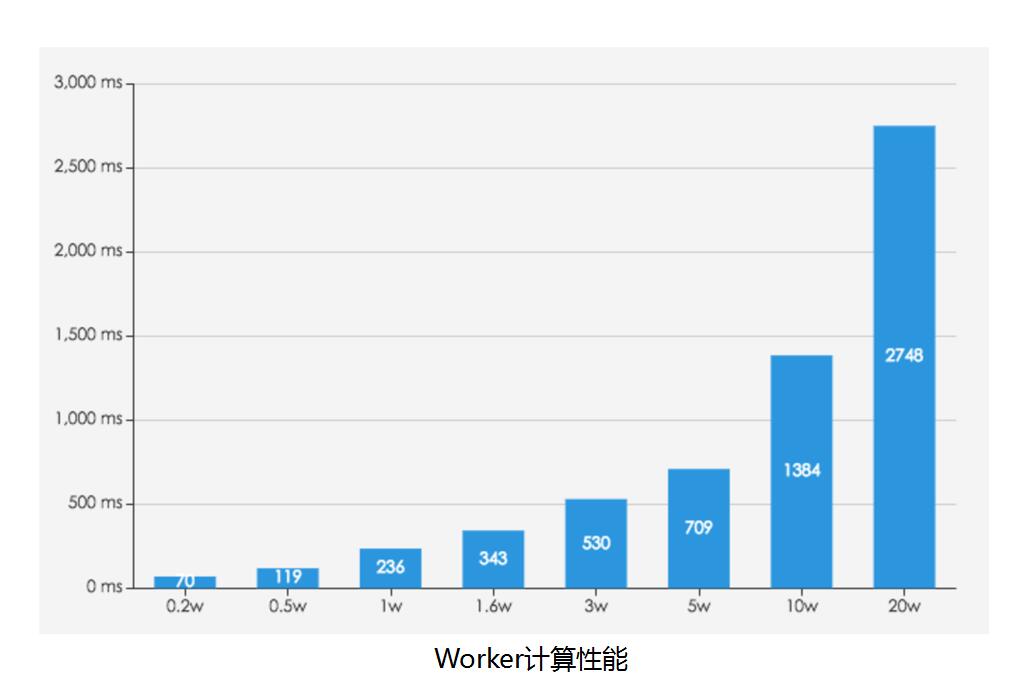
整个方案完成后,目前在整体计算能力方面有了很大的提高。图中横轴代表PUI个数,是2000个,扔到Worker里,返回是70毫秒,如果是5000个点100毫秒。一般情况下,3万个点500毫秒对于浏览器整个过程用户体验非常不错。这个测试在电脑性能相对比较弱,如果好的电脑形成反馈更高。比如到10万个PVI计算达到了1.3秒,20万是2秒多。现在整体已经没有峰值了,只是用户是否可接受,做了Worker之后,另外一个问题20万个点如何从服务器端跑到客户端,这是另外一个事,至少可以看到Worker、多线程计算能力真的大大提升,在业务处理上没有瓶颈了,现在可以放20万个,其实30万也不会有什么问题,只是是否能够执行完而已。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】