【51CTO.com快译】开源Apache Kafka是一项高效的大数据策略中日益重要的核心部分,本文解释了个中原委。
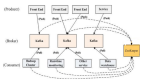
Apache Kafka是源自大数据潮流的最激动人心的开源项目之一。Kafka最初起源于领英(LinkedIn),现在是广泛的开源开发社区中日益主流的一部分。实际上,Kafka已进入到了关键时刻,因为它被用作一种管理企业组织流数据的核心平台,包括:金融服务业的物联网操作、欺诈和安全,零售业的商店库存跟踪以及其他行业的应用场合。
Kafka这个例子表明了领英如何成为护送内部代码进入到充满活力的开源社区方面的一个典范。
内哈·纳克赫德(Neha Narkhede)是Confluent的联合创始人兼***技术官,他之前是领英数据流基础设施的负责人,近日接受了TechRepublic的采访,畅谈了企业采用Kafka的情况以及管理流数据的***方法。
TechRepublic:Apache Kafka是如何进入企业主流环境的?
纳克赫德:据Kafka社区最近开展的一项调查显示,68%的Kafka用户计划在未来6个月至12个月整合更多的数据流处理技术;由于使用Kafka的应用程序数量越来越多,接受调查的企业组织中65%计划在未来12个月招聘拥有Kafka技能的员工。
在最近的Kafka峰会上,我们听到优步、网飞、Dropbox、HomeAway、高盛及更多的公司都在使用Kafka,实时做出业务决策。
比如说,优步完善了其数据流处理系统,以便处理优步市场(Uber Marketplace)中的许多使用场景,而Kafka在构建一条可靠、高效的数据管道方面扮演了重要角色。最广为人知的例子之一就是动态定价策略(surge pricing)。设想一下:获取所有数据来实时进行定价:从用户需求到路面上车辆的数量,做出决定:每一分钟的价格应该是多少。
这个典例表明了实时数据管道的实际运用。
HomeAway是另一个典例。作为度假租赁行业的***,它有100多万个房源(而且在不断增多)。借助Kafka,HomeAway连接不同的数据源,能够支持众多的使用场景,包括服务级别协议(SLA)监控、A/B测试、访客细分、欺诈检测、实时ETL及更多。
Confluent是我离开领英后与他人创办的公司,它专注于借助Confluent平台来扩展Apache Kafka,以满足需要大规模管理数据、而且注重速度的企业的要求。这包括下列工具:Kafka Streams、Kafka Connect以及Control Center,从而提供了一种新的可见性,以便了解大规模的Kafka集群,并确保运营正常。
TechRepublic:在什么情况下,Kafka绝对是最适合的一种框架?哪种使用场合?
纳克赫德:Kafka最常见的使用场合是用于实时数据传输、集成和实时数据流处理。
至于数据传输和集成,用户运用Kafka Connect将数据连接到应用程序,那样所有系统都可以访问***的数据。这包括这些数据:日志数据、数据库变化、传感器及设备的数据、监控数据流、呼叫中心记录和股票行情收录器数据。
至于实时数据流处理,Kafka Streams是Kafka核心的扩展部分,它让应用程序开发人员可以编写持续查询、转换、事件触发的警报和类似功能,并不需要一种专门的数据流处理框架。这些功能常常用于安全监控、实时操作(比如优步)和异步应用(比如零售商的库存检查)。
TechRepublic:运行这些类型的实时数据管道时,数据局部性有多重要?我大致听说的是,如果在DC/OS上运行,Kafka就能在Kafka和Cassandra之间本地读取数据。有鉴于行业正在向Mesosphere DC/OS实现的抽象迈进,你会如何描述在同一集群上运行互补框架的机会?
纳克赫德:在数据中心规模下管理服务带来了许多优化机会,如果你单个管理每项服务极难获得这样的机会。虽然能够把相关服务放在同一个地方是明显的好处,但是在有些情况下这并不合理;相反,你需要的是能够为有状态的应用程序分配专用资源,以便隔离。后者正是你在部署有状态的应用程序(比如Kafka和Cassandra)时需要的,而Mesos已增添了表示满足这类高级部署需求的功能,管理大规模有状态的应用程序需要这种功能。
我们确保在需要的场合下,Mesos部署Confluent平台保持了数据局部性。 我们的组件:Kafka REST Proxy和Schema Registry实际上是无状态的,能够在那些类型的框架中运行,而像Kafka代理这些有状态的服务能够以不同的方式来管理。但是整个Confluent平台需要这两种类型的服务。通过支持完整平台,它能够为客户带来更大的灵活性。
TechRepublic:Mesosphere DC/OS的两级调度程序有何重要性?为何它就有能力吸引合作伙伴/生态系统的支持(比如来自Confluent/DataStax群体)?
纳克赫德:不同的服务在集群资源和部署方面有不同的需求。两级调度程序可以满足有状态的应用程序(比如Kafka)的部署要求,那种场合下需要针对数据局部性进行优化,从而尽可能地节省网络和输入/输出带宽。这为客户提供了一种好的操作体验,又不牺牲Kafka提供的性能。
原文标题:How Apache Kafka takes streaming data mainstream,作者:Matt Asay
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】