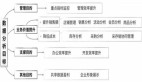
数据挖掘最重要的要素是分析人员的相关业务知识和思维模式。一般来说,数据挖掘主要侧重解决四类问题:分类、聚类、关联、预测。数据挖掘非常清晰的界定了它所能解决的几类问题。这是一个高度的归纳,数据挖掘的应用就是把这几类问题演绎的一个过程。
一、分类问题
分类问题属于预测性的问题,但是它跟普通预测问题的区别在于其预测的结果是类别(如A、B、C三类)而不是一个具体的数值(如55、65、75……)。
举个栗子:你和朋友在路上走着,迎面走来一个人,你对朋友说:我猜这个人是个上海人,那么这个问题就属于分类问题;如果你对朋友说:我猜这个人的年龄在30岁左右,那么这个问题就属于后面要说到的预测问题。
- 商业案例中,分类问题可谓是最多的:
- 给你一个客户的相关信息,预测一下他未来一段时间是否会离网?
- 信用度是好/一般/差?是否会使用你的某个产品?
- 将来会成为你的高/中/低价值的客户?
- 是否会响应你的某个促销活动?
……
有一种很特殊的分类问题,那就是“二分”问题,显而易见,“二分”问题意味着预测的分类结果只有两个类:如是/否;好/坏;高/低……;这类问题也称为0/1问题。之所以说它很特殊,主要是因为解决这类问题时,我们只需关注预测属于其中一类的概率即可,因为两个类的概率可以互相推导。如预测X=1的概率为P(X=1),那么X=0的概率P(X=0)=1-P(X=1),这一点是非常重要的。
可能很多人已经在关心数据挖掘方法是怎么预测P(X=1)这个问题的了,其实并不难。解决这类问题的一个大前提就是通过历史数据的收集,已经明确知道了某些用户的分类结果。
例如已经收集到了10000个用户的分类结果,其中7000个是属于“1”这类;3000个属于“0”这类。伴随着收集到分类结果的同时,还收集了这10000个用户的若干特征(指标、变量)。这样的数据集一般在数据挖掘中被称为训练集,顾名思义,分类预测的规则就是通过这个数据集训练出来的。
训练的思路大概是这样的:对所有已经收集到的特征/变量分别进行分析,寻找与目标0/1变量相关的特征/变量,然后归纳出P(X=1)与筛选出来的相关特征/变量之间的关系(不同方法归纳出来的关系的表达方式是各不相同的,如回归的方法是通过函数关系式,决策树方法是通过规则集)。
如需了解细节,请查阅:决策树、Logistic回归、判别分析、神经网络、Chi-square、Gini、……等相关知识。
二、聚类问题
聚类问题不属于预测性的问题,它主要解决的是把一群对象划分成若干个组的问题。划分的依据是聚类问题的核心。所谓“物以类聚,人以群分”,故得名聚类。
聚类问题容易与分类问题混淆,主要是语言表达的原因,因为我们常说这样的话:“根据客户的消费行为,我们把客户分成三个类,***个类的主要特征是……”,实际上这是一个聚类问题,但是在表达上容易让我们误解为这是个分类问题。
分类问题与聚类问题是有本质区别的:分类问题是预测一个未知类别的用户属于哪个类别(相当于做单选题),而聚类问题是根据选定的指标,对一群用户进行划分(相当于做开放式的论述题),它不属于预测问题。
聚类问题在商业案例中也是一个非常常见的,例如需要选择若干个指标(如价值、成本、使用的产品等)对已有的用户群进行划分:特征相似的用户聚为一类,特征不同的用户分属于不同的类。
聚类的方法层出不穷,基于用户间彼此距离的长短来对用户进行聚类划分的方法依然是当前***的方法。大致的思路是这样的:
1.首先确定选择哪些指标对用户进行聚类;
2.然后在选择的指标上计算用户彼此间的距离,距离的计算公式很多,最常用的就是直线距离(把选择的指标当作维度、用户在每个指标下都有相应的取值,可以看作多维空间中的一个点,用户彼此间的距离就可理解为两者之间的直线距离);
3.***聚类方法把彼此距离比较短的用户聚为一类,类与类之间的距离相对比较长。
如需了解细节,请查阅:聚类分析、系统聚类、K-means聚类、欧氏距离、马氏距离等知识。
三、关联问题
说起关联问题,可能要从“啤酒和尿布”说起了。有人说啤酒和尿布是沃尔玛超市的一个经典案例,也有人说,是为了宣传数据挖掘/数据仓库而编造出来的虚构的“托”。不管如何,“啤酒和尿布”给了我们一个启示:世界上的万事万物都有着千丝万缕的联系,我们要善于发现这种关联。
关联分析要解决的主要问题是:
- 一群用户购买了很多产品之后,哪些产品同时购买的几率比较高?
- 买了A产品的同时买哪个产品的几率比较高?
可能是由于最初关联分析主要是在超市应用比较广泛,所以又叫“购物篮分析”,英文简称为MBA,当然此MBA非彼MBA,意为Market Basket Analysis。
如果在研究的问题中,一个用户购买的所有产品假定是同时一次性购买的,分析的重点就是所有用户购买的产品之间关联性;如果假定一个用户购买的产品的时间是不同的,而且分析时需要突出时间先后上的关联,如先买了什么,然后后买什么?那么这类问题称之为序列问题,它是关联问题的一种特殊情况。从某种意义上来说,序列问题也可以按照关联问题来操作。
关联分析有三个非常重要的概念,那就是“三度”:支持度、可信度、提升度。假设有10000个人购买了产品,其中购买A产品的人是1000个,购买B产品的人是2000个,AB同时购买的人是800个。
- 支持度:指的是关联的产品(假定A产品和B产品关联)同时购买的人数占总人数的比例,即800/10000=8%,有8%的用户同时购买了A和B两个产品;
- 可信度:指的是在购买了一个产品之后购买另外一个产品的可能性,例如购买了A产品之后购买B产品的可信度=800/1000=80%,即80%的用户在购买了A产品之后会购买B产品;
- 提升度:就是在购买A产品这个条件下购买B产品的可能性与没有这个条件下购买B产品的可能性之比,没有任何条件下购买B产品可能性=2000/10000=20%,那么提升度=80%/20%=4。
如需了解细节,请查阅:关联规则、apriror算法中等相关知识。
四、预测问题
此处说的预测问题指的是狭义的预测,并不包含前面阐述的分类问题,因为分类问题也属于预测。一般来说我们谈预测问题主要指预测变量的取值为连续数值型的情况。
例如天气预报预测明天的气温、国家预测下一年度的GDP增长率、电信运营商预测下一年的收入、用户数等?
预测问题的解决更多的是采用统计学的技术,例如回归分析和时间序列分析。回归分析是一种非常古典而且影响深远的统计方法,最早是由达尔文的表弟高尔顿在研究生物统计中提出来的方法,它的主要目的是研究目标变量与影响它的若干相关变量之间的关系,通过拟和类似Y=aX1+bX2+……的关系式来揭示变量之间的关系。通过这个关系式,在给定一组X1、X2……的取值之后就可以预测未知的Y值。
相对来说,用于预测问题的回归分析在商业中的应用要远远少于在医学、心理学、自然科学中的应用。最主要的原因是后者是更偏向于自然科学的理论研究,需要有理论支持的实证分析,而在商业统计分析中,更多的使用描述性统计和报表去揭示过去发生了什么,或者是应用性更强的分类、聚类问题。
如需了解细节,请查阅:一元线性回归分析、多元线性回归分析、最小二乘法等相关知识。