1. 概念
1.1 UV 与 PV
对于互联网产品来说,UV 与 PV 是两个非常常见的指标,并且通常都是分析的最基础指标。UV 一般来讲,是指使用产品(或产品某个功能)的独立用户数。PV 则来源于网站时代,一般指网站(或网站某个页面)的页面浏览量,在移动互联网时代,则一般会引申表示使用产品(或产品某个功能)的用户行为或者用户操作数量。
PV 和 UV 一般而言是互相影响,一起变化的,对于 PV 和 UV 的变化与数字的解读,也是一门很深的学问。由于本文主要是介绍在多维分析中 UV 和 PV 的计算规则,所以,对于 PV 和 UV 的具体解读与分析,不做展开论述。
1.2 多维分析
多维分析是在 BI(Business Intelligence)领域广泛使用的一种分析技术和分析方法,能够从不同的角度,灵活动态地进行分析。
多维分析中有“指标”和“维度”两个基本概念,在这里,我们用一个实际的例子来进行描述。
一个典型的网站,它可能需要从地域、终端、App 版本这三个角度,来考察自己的 PV 和 UV 的情况。那么,在这个场景下,维度有三个,分别是地域、终端和 App 版本;指标则是两个,分别是 PV 和 UV。所谓的多维分析,就是可以在维度的任意组合情况下,来看对应的指标的数值:可以看北京的,iOS端的,7.1 版 App 的 PV 和 UV;也可以看湖北的安卓端的 PV 和 UV;也可以看 7.2 版 App 的 PV 和 UV。具体设置查询条件的时候,维度可以是三个,可以是两个,也可以是一个。从这个例子可以看出,多维分析是非常灵活的,具有很强的分析能力,可以充分满足分析人员对于产品的各种细粒度的分析需求。
而为了能够让多维分析发挥出更大的价值,一般情况下,都是希望多维分析的查询结果能够在一分钟能就得到,从而可以让使用者不停地调整查询条件,快速地验证自己的猜想。
2. “可加”与“不可加”
正如上面提到的,多维分析对于查询速度非常敏感,业内也有很多专门的存储和查询方案。
而在具体的实现中,有一种最为常见的实现手段,就是把各个维度的所有取值组合下的指标全部预先计算并且存储好,这种一般可以称作事实表。然后在具体进行多维查询的时候,再根据维度的选择,扫描相对应的数据,并聚合得到最终的查询条件。
此时,会发现一个比较有意思的问题,就是 PV 这类指标,是“可加”的,而 UV 这类指标,则是“不可加”的。例如,我们把昨天三个维度的可能组合下的所有的 PV 和 UV 都计算并且存储好,如下表所示:
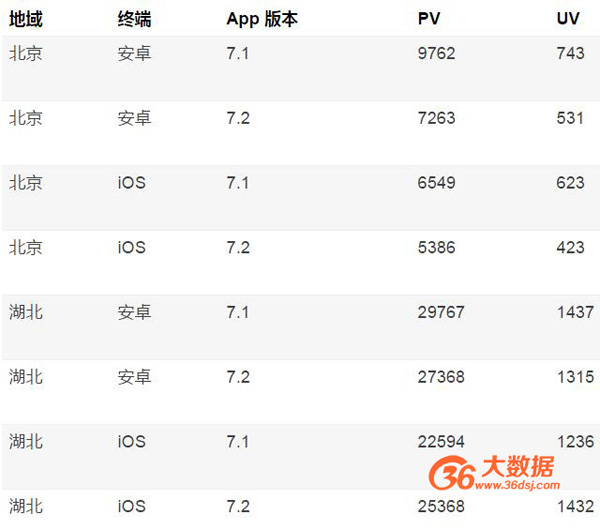
那么,对于 PV 这种指标,是可以通过扫描对应的记录,然后累加得到最终的结果。例如,我们想分析整个湖北的 PV,则可以把湖北相关的四条记录中的 PV,累加起来就是整个湖北的 PV 值。
但是,对于 UV 这类指标,却不能简单的累加,因为,这个指标并不是在每一个维度上都是正交的。例如,同一个用户可能先后使用了不同的 App 版本,甚至于有一定几率使用了不同的终端,所以,UV 并不能简单地累加,通常情况下,真实的 UV 是比加起来的值更小的。
因而,对于 UV 这类不可累加的指标,需要使用其它的计算方案。
3. UV 计算的常见方案
UV 类型的指标,有三种常见的计算方案,我们在这里分别进行介绍。
3.1 估算方案
所谓的估算方案,就是在上面的表格的基础上,不再额外记录更多细节,而是通过估算的方式来给出一个接近真实值的 UV 结果,常见的算法有很多,例如 HyperLogLog 等。
由于毕竟是估算,最终估算的结果有可能与真实值有较大差异,因此只有一些统计平台可能会采用,而如我们 Sensors Analytics 之类的以精细化分析为核心的分析系统并不会采用,因此在这里不做更多描述。
3.2 扩充事实表,以存代算
所谓以存代算,就是在预先计算事实表的时候,将所有需要聚合的结果,都算好。
依然以上面的例子来说明,如果我们想以存代算,预先做完聚合,类似于 Hive 所提供的group by with cube操作。在扩充完毕后,之前那个表的结果就应该是:
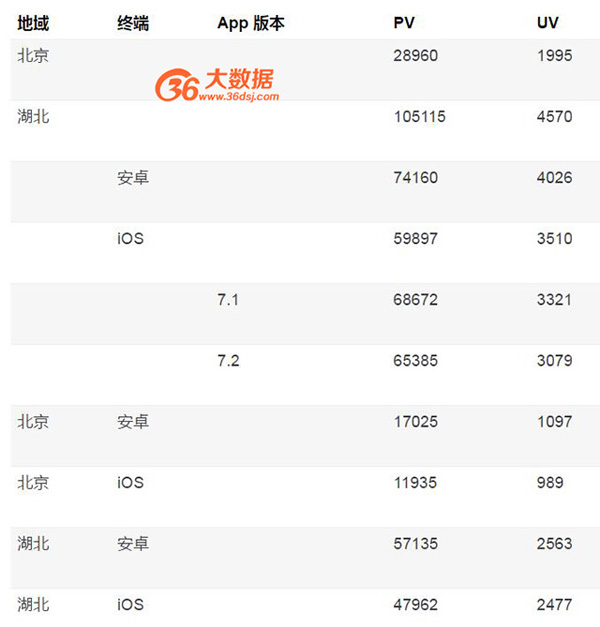
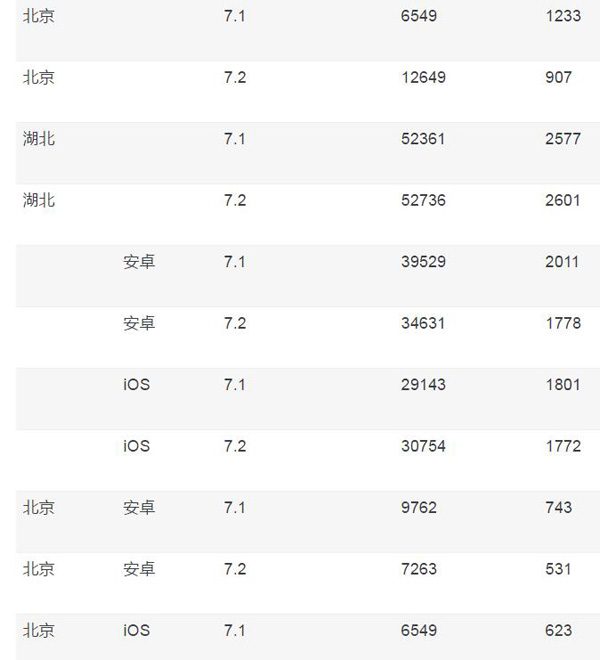
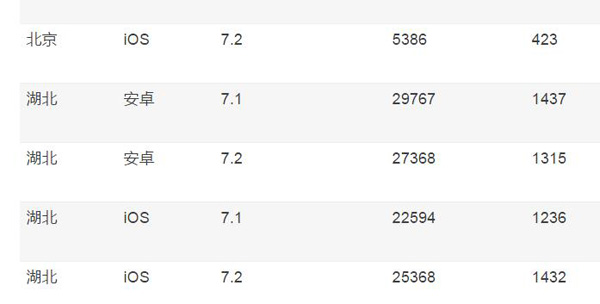
从这个表我们可以看出,假设一共三个维度,每个维度有两个取值,则之前的事实表一共是 2*2*2=8 条记录,而现在,则扩充到了 3*3*3-1=26 条记录,整个规模扩充了很多,会带来更多的存储和预计算的代价。
3.3 从最细粒度数据上扫描
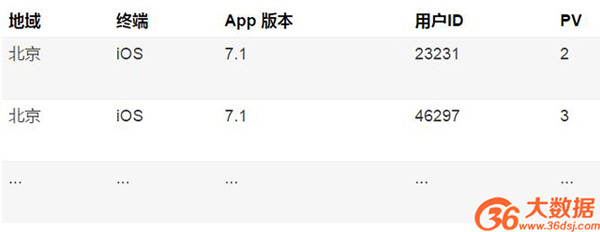
之前提出的扩充事实表的方式,的确可以解决多维分析中指标聚合的问题,除此之外,还有一种方案,则是在事实表上,将用户ID也做为一个维度,来进行保存,此时就不需要保存 UV 了,如下表所示:
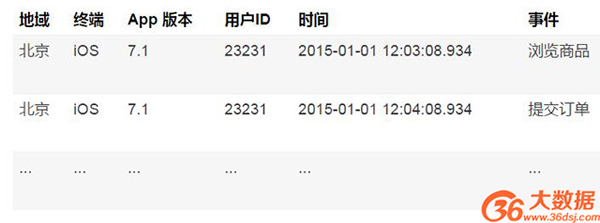
甚至更进一步,我们将 PV 数值也进一步展开,对于用户的每一个行为,都保留一条数据,如下表:
虽然这样一来,需要保存的数据规模有了数量级上的扩充,并且所有的聚合计算都需要在多维分析查询的时候再扫描数据并进行聚合,存储和计算代价都提高了很多,看似是一种很无所谓的举措。
但是,相比较之前的方案,它却有一个***的好处,也即是因为有了最细粒度的用户行为数据,才有可能计算事件级别的漏斗、留存、回访等,才有可能在这些数据的基础之上,进一步做用户画像、个性化推荐等等。而这也正是目前 Sensors Analytics 所采用的数据存储方案,也正因为采用了这种存储方案,我们才能够将自己成为精细化用户行为分析系统,才能够满足使用者的最细粒度数据分析和获取的需求。
在这样一个数据存储方案的基础上,为了提高数据查询的效能,一般的优化思路有采用列存储加压缩的方式减少从磁盘中扫描的数据量,采用分布式的方案提高并发扫描的性能,采用应用层缓存来减少不同查询的公共扫描数据的量等等,这方面的内容我们会在后面的文章里面做进一步的探讨,尽请期待