“ 数据排序”是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、 数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。下面进入这个示例。
1 实例描述
对输入文件中数据进行排序。 输入文件中的每行内容均为一个数字, 即一个数据。要求在输出中每行有两个间隔的数字,其中, 第一个代表原始数据在原始数据集中的位次, 第二个代表原始数据。
样例输入:
(1) file1:

(2) file2:

(3) file3:

样例输出:

2 设计思路
这个实例仅仅要求对输入数据进行排序,熟悉 MapReduce 过程的读者会很快想到在MapReduce 过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。
但是在使用之前首先需要了解它的默认排序规则。它是按照 key 值进行排序的,如果key 为封装 int 的 IntWritable 类型,那么 MapReduce 按照数字大小对 key 排序,如果 key为封装为 String 的 Text 类型,那么 MapReduce 按照字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装 int 的 IntWritable 型数据结构了。也就是在map 中将读入的数据转化成 IntWritable 型,然后作为 key 值输出( value 任意)。 reduce 拿到之后,将输入的 key 作为 value 输出,并根据 value-list 中元素的个数决定输出的次数。输出的 key(即代码中的 linenum)是一个全局变量,它统计当前 key 的位次。
需要注意的是这个程序中没有配置 Combiner,也就是在 MapReduce 过程中不使用 Combiner。这主要是因为使用 map 和 reduce 就已经能够完成任务了。
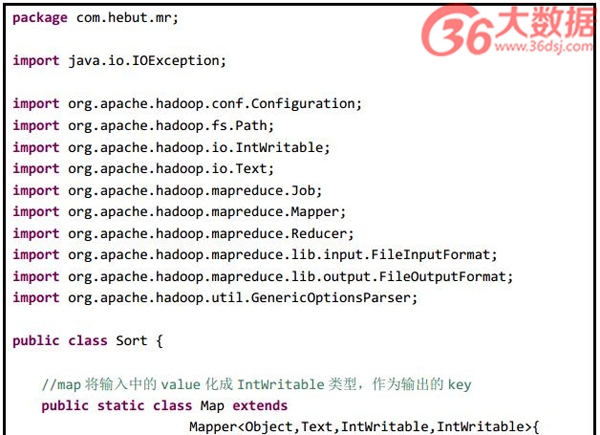
3 程序代码
程序代码如下所示:



4 代码结果
(1)准备测试数据
通过 Eclipse 下面的“ DFS Locations”在“ /user/hadoop”目录下创建输入文件“ sort_in”文件夹( 备注:“ sort_out”不需要创建。)如图 2.4-1 所示,已经成功创建。
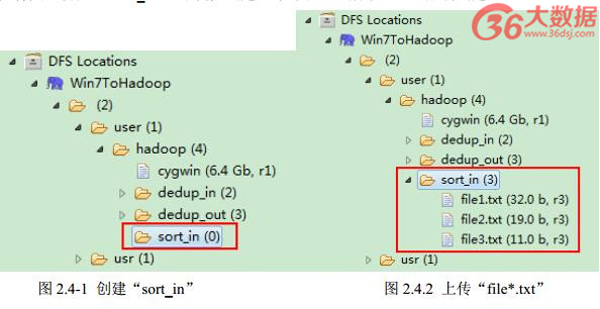
然后在本地建立三个 txt 文件,通过 Eclipse 上传到“ /user/hadoop/sort_in”文件夹中,三个 txt 文件的内容如“实例描述”那三个文件一样。如图 2.4-2 所示,成功上传之后。从 SecureCRT 远处查看“ Master.Hadoop”的也能证实我们上传的三个文件。

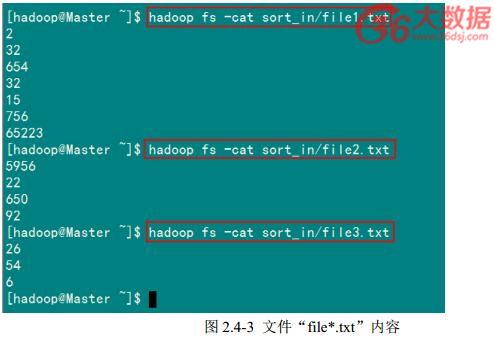
查看两个文件的内容如图 2.4-3 所示:
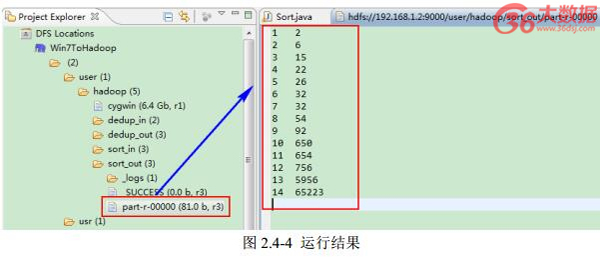
(2)查看运行结果
这时我们右击 Eclipse 的“ DFS Locations”中“ /user/hadoop”文件夹进行刷新,这时会发现多出一个“ sort_out”文件夹,且里面有 3 个文件,然后打开双其“ part-r-00000”文件,会在 Eclipse 中间把内容显示出来。如图 2.4-4 所示。