前言
爬虫和反爬虫日益成为每家公司的标配系统。爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多;有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定性保障、竞争优势保持的目的。
然而,一方面防守这事ROI不好体现,另一方面反爬虫这种系统,相对简单的爬虫来说难度和复杂度都要高很多,往往需要一整套大数据解决方案才能把事情做好,因此只有少量的公司可以玩转起来。当出现问题的时候,很多公司往往束手无策。
本文将描述一种尽量简单的反爬虫方案,可以在十几分钟内解决部分简单的爬虫问题,缓解恶意攻击或者是系统超负荷运行的状况;至于复杂的爬虫以及更精准的防御,需要另外讨论。
整套方案会尽量简单易懂,不会涉及到专门的程序开发,同时尽量利用现有的组件,避免额外组件的引入。内容上主要分为三大部分:
- 访问数据获取。采集用户的访问数据,用来做爬虫分析的数据源
- 爬虫封禁。当找到爬虫后,想办法去阻断它后续的访问
- 爬虫分析。示例通过简单策略来分析出爬虫
简单的数据获取
数据获取是做好反爬虫系统的关键,常见的几种模式
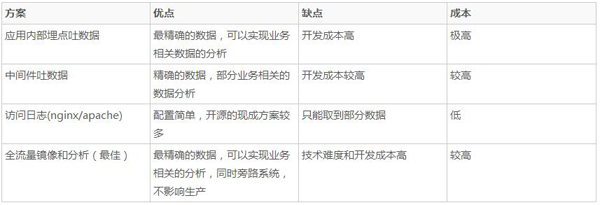
本篇,采用nginx的日志方式,这种只需要通过对常见的nginx最简单的配置就能从远程获取相应的访问日志
官方nginx配置:
- log_format warden '" "$remote_addr" "$remote_port" "$server_addr" "$server_port" "$request_length" "$content_length" "$body_bytes_sent" "$request_uri" "$host" "$http_user_agent" "$status" "$http_cookie" "$request_method" "$http_referer" "$http_x_forwarded_for" "$request_time" "$sent_http_set_cookie" "$content_type" "$upstream_http_content_type" "$request_body"\n';
- access_log syslog:server=127.0.0.1:9514 warden ;
tengine配置(编译时带上–with-syslog)
- log_format warden '" "$remote_addr" "$remote_port" "$server_addr" "$server_port" "$request_length" "$content_length" "$body_bytes_sent" "$request_uri" "$host" "$http_user_agent" "$status" "$http_cookie" "$request_method" "$http_referer" "$http_x_forwarded_for" "$request_time" "$sent_http_set_cookie" "$content_type" "$upstream_http_content_type" "$request_body"\n';
- access_log syslog:user::127.0.0.1:9514 warden ;
这里面需要注意的是:
由于较老的nginx官方版本不支持syslog,所以tengine在这块功能上做了单独的开发(需要通过编译选项来启用),在不确定的情况下,请修改配置 文件后先使用(nginx -t)来测试一下,如果不通过,需要重新在configure时加上syslog选项,并编译。
尽量获取了跟爬虫相关的数据字段,如果有定制的http header,可以自行加上
采用udp方式来发送syslog,可以将访问日志发送给远端分析服务,同时udp的方式保证nginx本身不会受到影响
访问日志拿不到响应的具体内容(nginx有办法搞定,但有代价),无法支持业务相关的防护
简单的爬虫封禁
反爬虫最后的生效,需要靠合理的封禁模式,这里比较几种模式:

本段将介绍基于iptables的方案,虽然适用范围较小;但是依赖少,可以通过简单配置linux就能达到效果。
第一步
安装ipset。ipset扩充了iptables的基本功能,可以提供更加高效的访问控制
- # centos 6.5上面安装非常简单
- sudoyuminstall -y ipset
第二步
在iptables中建立相应的ipset,来进行访问权限的封禁
- # 新增用于封禁的ipset
- sudo ipset -N --exist warden_blacklist iphash
- # 增加相应的iptables规则
- sudo iptables -A INPUT -m set --set warden_blacklist src -j DROP
- # 保存iptables
- sudo service iptables save
第三步
获取当前封禁的ip黑名单,并导入到iptables里面去
- sudoipset --exist destroy warden_blacklist_tmp;sudoipset -N warden_blacklist_tmp iphash;echo"1.1.1.1,2.2.2.2"|tr,"\n"|xargs-n 1 -I {}sudoipset -A warden_blacklist_tmp {} ;sudoipset swap warden_blacklist_tmp warden_blacklist
这里为了尽可能的提升效率,作了以下事情:
- 建立临时ipset,方便做操作
- 将当前封禁黑名单中的ip提取出来,加入到此ipset(示例中用了最简单的echo来展示,实际可相应调整)
- 将ipset通过原子操作与iptables正在使用的ipset作交换,以最小的代价将最新的黑名单生效
简单的爬虫策略
要能精确的分析爬虫,需要强大的数据分析平台和规则引擎,来分析这个IP/设备/用户分别在短时间区间/长时间范围里的行为特征和轨迹,这里涉及到了非常复杂的数据系统开发,本文将通过简单的shell脚本描述比较简单的规则
例子1
封禁最近100000条中访问量超过5000的ip
- nc -ul 9514 |head-100000 |awk-F'" "''{print $2}'|sort|uniq-c |sort-nr |awk'$1>=5000 {print $2}'
这里面:
1.udp服务监听nginx发过来的syslog消息,并取10000条,找到其中每条访问记录的ip
2.通过sort 和uniq来获取每个ip出现的次数,并进行降序排列
3.再通过awk找到其中超过阈值的ip,这就得到了我们所需要的结果。
例子2
封禁最近100000条中user agent明显是程序的ip
- nc -ul 9514 |head-100000 |awk-F'" "''$10 ~ /java|feedly|universalfeedparser|apachebench|microsoft url control|python-urllib|httpclient/ {print $2}'|uniq
这里面:
1.通过awk的正则来过滤出问题agent,并将相应ip输出
2.关于agent的正则表达式列出了部分,可以根据实际情况去调整和积累
当然,这里只是列举了简单的例子,有很多的不足之处
1.由于只采用了shell,规则比较简单,可以通过扩展awk或者其他语言的方式来实现更复杂的规则
2.统计的窗口是每100000条,这种统计窗口比较粗糙,好的统计方式需要在每条实时数据收到是对过去的一小段时间(例如5分钟)重新做统计计算
3.不够实时,无法实时的应对攻击行为;生产环境中,需要毫秒级的响应来应对高级爬虫
4…….
拼起来
所有模块组合起来,做一个完整的例子。假设:
1.负载均衡192.168.1.1,使用了官方nginx,并配置了syslog发往192.168.1.2
2.192.168.1.2启动nc server,每隔一段时间进行分析,找出问题ip,并吐给192.168.1.1
3.192.168.1.1通过iptables进行阻拦,数据来源于192.168.1.2的分析机器
除了nginx配置和iptables基本配置,前几段的配置略作改动:
- ### nginx conf@192.168.1.1
- log_format warden '" "$remote_addr" "$remote_port" "$server_addr" "$server_port" "$request_length" "$content_length" "$body_bytes_sent" "$request_uri" "$host" "$http_user_agent" "$status" "$http_cookie" "$request_method" "$http_referer" "$http_x_forwarded_for" "$request_time" "$sent_http_set_cookie" "$content_type" "$upstream_http_content_type" "$request_body"\n';
- access_log syslog:server=192.168.1.2:9514 warden ;
- ### 分析@192.168.1.2, 增加了结果会吐,同时每隔60分钟跑一次,把数据返回给192.168.1.1
- while true ; do nc -ul 9514 | head -100000 | awk -F '" "' '{print $2}' | sort | uniq -c | sort -nr | awk '$1>=5000 {print $2}' | tr '\n' ',' | awk '{print $0}' | socat - UDP:192.168.1.1:9515 ; sleep 3600 ; done
- ### 阻断@192.168.1.1
- #基础配置
- sudo ipset -N --exist warden_blacklist iphash
- sudo iptables -A INPUT -m set --set warden_blacklist src -j DROP
- sudo service iptables save
- #动态接收并更新iptables
- while true ; do sudo ipset --exist destroy warden_blacklist_tmp; sudo ipset -N warden_blacklist_tmp iphash; socat UDP-LISTEN:9515 - | tr , "\n" | xargs -n 1 -I {} sudo ipset -A warden_blacklist_tmp {} ;sudo ipset swap warden_blacklist_tmp warden_blacklist ; sudo ipset list ; done
以上只是简单示例,实际中还是建议换成shell脚本
总结
本文列出一种简单的反爬虫方案,由于过于简单,可以当做概念示例或者是救急方案,如果需要进一步深化,需要在以下方面去加强:
1.强化数据源,可以通过流量获得全量数据。目前爬虫等网络攻击逐渐转向业务密切相关的部分,往钱的方向靠近,所以需要更多的业务数据去支撑,而不仅仅是访问日志
2.更灵活的阻断,需要有多种阻断手段和略复杂的阻断逻辑
3.除却ip,还需要考察用户、设备指纹等多种追踪方式,应对移动环境和ipv6环境下,“IP”这一信息的力不从心
4.强化规则引擎和模型,需要考察更多用户行为的特征,仅仅从频率等手段只等应对傻爬虫,同时会造成误杀率更高
5.建立数据存储、溯源、统计体系,方便分析人员去分析数据并建立新的模型和规则。反爬虫是一件持续性行为,需要良好的平台来支撑。
6.可以根据实际需要去做好反爬虫系统的集成。比如nginx数据–>反爬系统–>nginx阻断;F5数据–>反爬系统–>F5阻断