大数据的概念(Big Data)已经火了5年了,从Google Trends上来看11年以来,关注度一路快速增长,到15年开始逐步持平。实际上大数据已经逐步走过了描绘愿景的阶段,人们期待的是大数据能够真正在各个行业落地,产生巨大的价值。但目前来看创造了明显商业价值的应用还是在互联网,除了搜索以外,杀手级的应用也就两个--精准广告和推荐。TalkingData在大数据领域耕耘了5年,发展非常迅速,在很多传统行业的大数据应用都是居于国内领先地位。但是当我们的业务发展得越来越好,涉及的行业越来越多,客户越来越多,项目越来越大,越来越深入的时候,我们却觉得让大数据产生价值的瓶颈也越来越大。从本质上来讲这个瓶颈就是目前大数据在传统行业的应用其边际成本并不是趋于0的。
回过头来看大数据在互联网里的成功应用,无论是搜索,精准广告还是推荐系统,其投入成本是非常高的。需要巨大的计算机集群,和人力成本非常高的程序员和数据科学家,以及大量的研发投入。但是所有这些业务都是在线业务,当用户规模扩大以后,除了硬件资源上的成本外,其他的成本迅速被摊薄,使得其边际成本趋近于0。业务规模越大,边际成本越低,对技术成本的投入也就越不敏感。这也是为什么越是大的互联网公司,越舍得在搜索,广告和推荐系统这几个大数据应用方面做投入。因为提高0.1%的预测精准度,就能获得上亿的收入。作为应用大数据产生价值***的互联网企业,自然是成为传统企业效仿的榜样。但是传统行业受制于业务规模或者业务形态,无法实现大数据应用的边际成本趋于0。
如果在不具备边际成本趋于0的行业中按照互联网行业成本不敏感的方式来对大数据进行投资,在初期的热情过后一定会发现这是不可接受的。这就是大数据普及化的过程中遇到的***的瓶颈。我们TalkingData一直致力于为更多的企业提供***标准的大数据解决方案和服务,但业务的迅速增长迅速吃掉了我们的研发,咨询和数据科学资源,为了保证交付质量,我们不得不拒绝了很多潜在客户。
互联网创造了大数据,基于大数据创造出来的智能在搜索、精准广告、推荐系统等应用中又创造了巨大的商业价值。但是大数据创造智能的成本是非常高昂的,除了基本的软硬件资源投入,***的成本在于人力资源的成本。收集,清洗,抽取,纠错,整合不同来源的庞大数据几乎完全依赖人的智慧,特征工程,分析,算法开发,建模,调参,优化,部署,测试等等所有这些工作也是完全依依赖于人的智慧。不但需要巨大的人力将应用建立起来,也需要巨大的人力来维护。而且当我们想调整应用的目标时,又需要投入巨大的人力来进行调整。目前的大数据应用方式,就像乌尔邦大炮,耗费人力无数而又笨重不堪,除了用于攻陷君士坦丁堡这样的千年名城外,很难在其他战场上有用武之地。我们现在很多企业,甚至政府都在投入巨资建设自己的乌尔邦大炮,但是很可能这些投资最终只是成为对大数据崇拜的图腾。
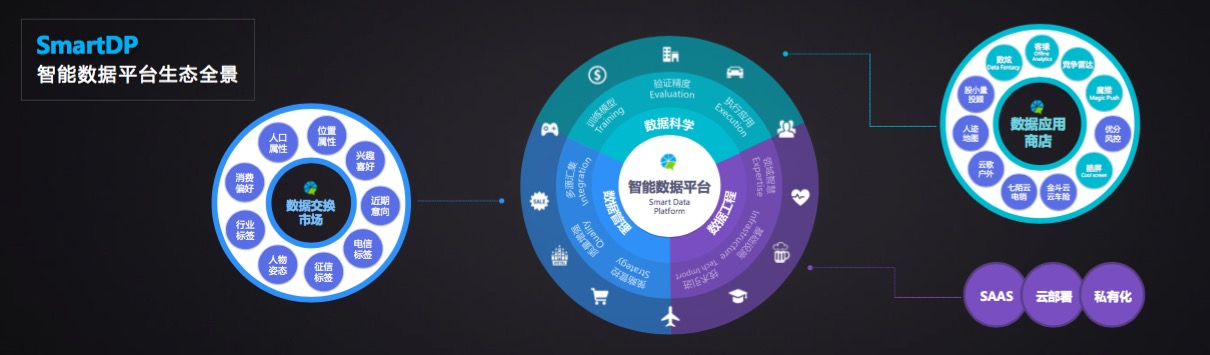
广大的中小型互联网公司和众多的传统企业,在大数据方面,真正需要的是成本相对低廉的山炮,野炮,即使用成本和门槛低很多的大数据平台。这样的平台需要更有效率的融合数据,机器的智能和人的智慧,让人的智慧集中在理解数据这样的平台,定义问题,和把握解决问题的路径和方向上。这样的平台应该尽可能的把数据收集,清洗,抽取,纠错,整合的工作交给机器,同时让分析,建模和优化工作摆脱像老中医看病一样依赖人的经验来选择模型,算法和参数。这样的平台就是TalkingData的智能数据平台-Smart Data Platform。Smart Data Platform将极大降低企业建设,使用,和维护数据平台的成本。Smart Data Platform将使得企业不但可以以很低的边际成本运用大数据来提升核心业务的效率,而且可以以合理的成本应用大数据在众多小业务,小场景下获得更好的收益。
Smart Data Platform的概念涵盖了数据管理,数据工程和数据科学。但是其精髓就在于用人工智能技术来突破传统完全依赖于人的智慧来驾驭数据的方式,将由人来创造人工智能的方式逐步转向由人工智能来创造人工智能。这将是大数据和人工智能发展的革命性变化,就如由人来创造机器转变为用机器来创造机器,从而打开了工业革命的大门一样,大数据和人工智能的发展也将进入一个快速螺旋上升的阶段。
当然,如此宏伟的目标并不能一蹴而就。就目前而言,大数据技术***的两个瓶颈就在于数据加工处理和分析建模。前者通常被认为是繁重的dirty work, 没有多少人真正爱干。后者虽然是让人兴奋的工作,但是其更接近于艺术,对人的能力,直觉,和经验要求很高。前者因为工作量的庞大,后者因为人才的稀缺,成为了目前大数据技术的阿格琉斯之踵。TalkingData在这两个方面都做了一些工作,也对未来的发展方向做了一些展望。
数据的处理加工目前基本完全依赖人的智慧,对数据如何清洗,如何纠错,如何标准化,如何聚合相似数据都要求人来制定规则,对数据关系的梳理更是有赖于人的智慧的输入。在大数据时代到来之前,这些问题都不被人重视,但是从2012年大数据概念逐渐火起来之后,在VLDB, SIGMOD等学术会议上关于数据处理的论文达到204篇。学术界,工业界逐渐认识到这个问题是大数据晴朗的天空上的一朵大乌云, 是必须要解决的问题。 AMPLab的SampleClean项目就是致力于用机器学习来解决数据的抽取,格式化,相似度连接等问题的项目。国外也有一些公司比如Tamr也在研发利用机器学习技术来解决元数据识别,纠错,数据表自动关联和相似数据项聚合的产品。SampleClean和Tamr都使用了Active Learning的技术,在处理过程中对不确定的问题会提出来,让人来回答,然后学习到人的判断规律,不断提高自身的智能程度。数据处理智能化这方面的研究和尝试应该说还处于起步阶段,还没有特别成熟的开源项目或者商业产品。TalkingData基于自己的实践和对该方向跟踪研究,将数据智能处理分为两个阶段,数据关系梳理,和数据项聚合。
数据关系梳理,是把所有数据表或者文件的Meta Data识别出来,然后根据Meta Data之间的关系把所有的数据表或者文件的关联关系梳理出来。目前,这个过程基本都是由人来完成的,是个非常费时费力的工作,效率很难得到有效提高。如果要把这个过程自动化,那么会有三个层次的问题。首先,最简单的,直接对Meta Data识别,这个通过将人的经验固化下来就可以解决这个问题。比如对手机号字段的识别,可以将常见手机号字段命名方式作为规则固化下来,在Meta Data识别时直接用规则判断。当然,事先固定的规则很难处理所有问题,这时可以引入Active Learing的方法,在不确定时可以让人来介入判断,然后再学习人的判断成为新的规则。 其次,在很多情况下Meta Data的命名不具意义,或者因为某些原因丢失了Meta Data,那么直接判断Meta Data本身就没有办法,这种情况下可以通过字段值的特征来判断字段的意义,如手机号,是11位,以13x, 15x, 18x, 17x开头的数字有很大可能是手机号,如果字段值都符合这些特征,那么这个字段就有非常高的可能性是手机号。同样,我们可以通过预置规则+Active Learning的方式来支持这一功能。通过以上两种方法识别除了字段的意义后,则可以很容易的建立起数据之间的关联关系。但是,还有一种最困难的情况,就是通过以上两种方式都无法确定意义的字段之间是否存在关联关系。 这种情况下,我们需要预先建立通用的字段关联识别的机器学习模型,根据两个字段的数据值判断两个字段是否是同一字段。通过以上这些方法,机器能够给出数据表或者文件之间的关系,当然受限于机器的智能能力,不可能完全准确,因此对于任何两个表或者文件之间的关联关系,给出的是相关的可能性,而不是是否关联,***让人来介入修正这些可能的关联关系。这样,梳理数据关系中大量繁重的工作都由机器完成,人只是介入其中为机器提供一些咨询,和***确认结果,将大大提高人的效率。
数据项聚合或者相似度连接(Similarity Join)是另一个比较挑战的任务,因为相同的数据项因为书写习惯,格式的不同,有可能产生一些差别。比如人名,地名,国家名称等。对于变化不大的情况,采用相似度度量方法,再加上局部敏感哈希来加速匹配过程能取得不错的效果。TalkingData在应用包名合并的问题上综合了应用名,包名的字符串相似性,应用描述的文本相似性,和基于深度学习的图片相似度实现了包名的自动合并。但是对于更为复杂的问题,比如全称和简写的问题,同义词,反义词,甚至是不同语言的问题,要比较好的解决这一问题,就需要知识图谱的支撑。
数据分析建模中一个很大的问题就是模型选择和参数选择,这个问题对于数据科学家来说一直都是很头疼的问题。知乎上有一个问题:为什么越来越觉得机器学习调参就像老中医看病? 非常有意思,问题及其回答都体现了模型选择和参数选择是一个严重依赖数据科学家个人经验的工作。目前有一些开发数据科学平台的公司为了解决这个问题,就在其产品中集成了自动选择模型和参数的功能,其基本原理就是尝试所有的模型及其参数空间(有可能根据一些启发式方法来对搜索空间剪枝)。这种方法在小数据集上是可行的,但是对于大规模数据的问题,需要的计算量就是不可接受的。TalkingData在这方面做了一些工作,在即将开源的Fregata大规模机器学习算法库中,我们实现了不需要调参的几个经典算法,这样就使得算法可以作为标准的算子集成到数据处理流程中,而不需要case by case由数据科学家来调校,从而极大的提高在大规模问题上分析建模过程的效率。
以上两个方面是TalkingData Smart Data Platform短期致力于达到的目标,有了智能的数据处理,和智能的数据分析建模,就可以大大提高大数据应用的效率,降低成本。使得大数据在小业务,小场景中也能创造出超过成本的价值,使得广大的中小互联网公司和传统企业都能享受大数据的红利。TalkingData也可以更高效的支持更多的客户,帮助更多的企业在大数据上成功。“用数据的心智去超越”,TalkingData Smart Data Platform赋予机器以智能帮助人更好,更高效创造数据的心智去超越我们的梦想。
文章作者:
张夏天,TalkingData***数据科学家,全面负责移动大数据挖掘工作,包括移动应用推荐系统、移动广告优化、移动应用受众画像、移动设备用户画像、游戏数据挖掘、位置数据挖掘等工作。同时负责大数据机器学习算法的研究和实现工作。