本文来源于问题 Java字符串连接***实践?
- java连接字符串有多种方式,比如+操作符,StringBuilder.append方法,这些方法各有什么优劣(可以适当说明各种方式的实现细节)?
- 按照高效的原则,那么java中字符串连接的***实践是什么?
- 有关字符串处理,都有哪些其他的***实践?
废话不多说,直接开始, 环境如下:
- JDK版本: 1.8.0_65
- CPU: i7 4790
- 内存: 16G
直接使用+拼接
看下面的代码:
- @Test
- public void test() {
- String str1 = "abc";
- String str2 = "def";
- logger.debug(str1 + str2);
- }
在上面的代码中,我们使用加号来连接四个字符串,这种字符串拼接的方式优点很明显: 代码简单直观,但是对比StringBuilder和StringBuffer在大部分情况下比后者都低,这里说是大部分情况下,我们用javap工具对上面代码生成的字节码进行反编译看看在编译器对这段代码做了什么。
- public void test();
- Code:
- 0: ldc #5 // String abc
- 2: astore_1
- 3: ldc #6 // String def
- 5: astore_2
- 6: aload_0
- 7: getfield #4 // Field logger:Lorg/slf4j/Logger;
- 10: new #7 // class java/lang/StringBuilder
- 13: dup
- 14: invokespecial #8 // Method java/lang/StringBuilder."<init>":()V
- 17: aload_1
- 18: invokevirtual #9 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
- 21: aload_2
- 22: invokevirtual #9 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
- 25: invokevirtual #10 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
- 28: invokeinterface #11, 2 // InterfaceMethod org/slf4j/Logger.debug:(Ljava/lang/String;)V
- 33: return
从反编译的结果来看,实际上对字符串使用+操作符进行拼接,编译器会在编译阶段把代码优化成使用StringBuilder类,并调用append方法进行字符串拼接,***调用toString方法,这样看来是否可以认为在一般情况下其实直接使用+,反正编译器也会帮我优化为使用StringBuilder?
StringBuilder源码分析
答案自然是不可以的,原因就在于StringBuilder这个类它内部做了些什么时。
我们看一看StringBuilder类的构造器
- public StringBuilder() {
- super(16);
- }
- public StringBuilder(int capacity) {
- super(capacity);
- }
- public StringBuilder(String str) {
- super(str.length() + 16);
- append(str);
- }
- public StringBuilder(CharSequence seq) {
- this(seq.length() + 16);
- append(seq);
- }
StringBuilder提供了4个默认的构造器, 除了无参构造函数外,还提供了另外3个重载版本,而内部都调用父类的super(int capacity)构造方法,它的父类是AbstractStringBuilder,构造方法如下:
- AbstractStringBuilder(int capacity) {
- value = new char[capacity];
- }
可以看到实际上StringBuilder内部使用的是char数组来存储数据(String、StringBuffer也是),这里capacity的值指定了数组的大小。结合StringBuilder的无参构造函数,可以知道默认的大小是16个字符。
也就是说如果待拼接的字符串总长度不小于16的字符的话,那么其实直接拼接和我们手动写StringBuilder区别不大,但是我们自己构造StringBuilder类可以指定数组的大小,避免分配过多的内存。
现在我们再看看StringBuilder.append方法内部做了什么事:
- @Override
- public StringBuilder append(String str) {
- super.append(str);
- return this;
- }
直接调用的父类的append方法:
- public AbstractStringBuilder append(String str) {
- if (str == null)
- return appendNull();
- int len = str.length();
- ensureCapacityInternal(count + len);
- str.getChars(0, len, value, count);
- count += len;
- return this;
- }
在这个方法内部调用了ensureCapacityInternal方法,当拼接后的字符串总大小大于内部数组value的大小时,就必须先扩容才能拼接,扩容的代码如下:
- void expandCapacity(int minimumCapacity) {
- int newCapacity = value.length * 2 + 2;
- if (newCapacity - minimumCapacity < 0)
- newCapacity = minimumCapacity;
- if (newCapacity < 0) {
- if (minimumCapacity < 0) // overflow
- throw new OutOfMemoryError();
- newCapacity = Integer.MAX_VALUE;
- }
- value = Arrays.copyOf(value, newCapacity);
- }
StringBuilder在扩容时把容量增大到当前容量的两倍+2,这是很可怕的,如果在构造的时候没有指定容量,那么很有可能在扩容之后占用了浪费大量的内存空间。其次扩容后还调用了Arrays.copyOf方法,这个方法把扩容前的数据复制到扩容后的空间内,这样做的原因是:StringBuilder内部使用char数组存放数据,java的数组是不可扩容的,所以只能重新申请一片内存空间,并把已有的数据复制到新的空间去,这里它最终调用了System.arraycopy方法来复制,这是一个native方法,底层直接操作内存,所以比我们用循环来复制要块的多,即便如此,大量申请内存空间和复制数据带来的影响也不可忽视。
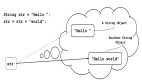
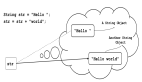
使用+拼接和使用StringBuilder比较
- @Test
- public void test() {
- String str = "";
- for (int i = 0; i < 10000; i++) {
- str += "asjdkla";
- }
- }
上面这段代码经过优化后相当于:
- @Test
- public void test() {
- String str = null;
- for (int i = 0; i < 10000; i++) {
- str = new StringBuilder().append(str).append("asjdkla").toString();
- }
- }
一眼就能看出创建了太多的StringBuilder对象,而且在每次循环过后str越来越大,导致每次申请的内存空间越来越大,并且当str长度大于16时,每次都要扩容两次!而实际上toString方法在创建String对象时,调用了Arrays.copyOfRange方法来复制数据,此时相当于每执行一次,扩容了两次,复制了3次数据,这样的代价是相当高的。
- public void test() {
- StringBuilder sb = new StringBuilder("asjdkla".length() * 10000);
- for (int i = 0; i < 10000; i++) {
- sb.append("asjdkla");
- }
- String str = sb.toString();
- }
这段代码的执行时间在我的机器上都是0ms(小于1ms)和1ms,而上面那段代码则大约在380ms!效率的差距相当明显。
同样是上面的代码,将循环次数调整为1000000时,在我的机器上,有指定capacity时耗时大约20ms,没有指定capacity时耗时大约29ms,这个差距虽然和直接使用+操作符有了很大的提升(且循环次数增大了100倍),但是它依旧会触发多次扩容和复制。
将上面的代码改成使用StringBuffer,在我的机器上,耗时大约为33ms,这是因为StringBuffer在大部分方法上都加上了synchronized关键字来保证线程安全,执行效率有一定程度上的降低。
使用String.concat拼接
现在再看这段代码:
- @Test
- public void test() {
- String str = "";
- for (int i = 0; i < 10000; i++) {
- str.concat("asjdkla");
- }
- }
这段代码使用了String.concat方法,在我的机器上,执行时间大约为130ms,虽然直接相加要好的多,但是比起使用StringBuilder还要太多了,似乎没什么用。其实并不是,在很多时候,我们只需要连接两个字符串,而不是多个字符串的拼接,这个时候使用String.concat方法比StringBuilder要简洁且效率要高。
- public String concat(String str) {
- int otherLen = str.length();
- if (otherLen == 0) {
- return this;
- }
- int len = value.length;
- char buf[] = Arrays.copyOf(value, len + otherLen);
- str.getChars(buf, len);
- return new String(buf, true);
- }
上面这段是String.concat的源码,在这个方法中,调用了一次Arrays.copyOf,并且指定了len + otherLen,相当于分配了一次内存空间,并分别从str1和str2各复制一次数据。而如果使用StringBuilder并指定capacity,相当于分配一次内存空间,并分别从str1和str2各复制一次数据,***因为调用了toString方法,又复制了一次数据。
结论
现在根据上面的分析和测试可以知道:
- Java中字符串拼接不要直接使用+拼接。
- 使用StringBuilder或者StringBuffer时,尽可能准确地估算capacity,并在构造时指定,避免内存浪费和频繁的扩容及复制。
- 在没有线程安全问题时使用StringBuilder, 否则使用StringBuffer。
- 两个字符串拼接直接调用String.concat性能***。
关于String的其他***实践
- 用equals时总是把能确定不为空的变量写在左边,如使用"".equals(str)判断空串,避免空指针异常。
- 第二点是用来排挤***点的.. 使用str != null && str.length() != 0来判断空串,效率比***点高。
- 在需要把其他对象转换为字符串对象时,使用String.valueOf(obj)而不是直接调用obj.toString()方法,因为前者已经对空值进行检测了,不会抛出空指针异常。
- 使用String.format()方法对字符串进行格式化输出。
- 在JDK 7及以上版本,可以在switch结构中使用字符串了,所以对于较多的比较,使用switch代替if-else。
我暂时想的起来的就这么几个了.. 请大家帮忙补充补充...