【51CTO.com原创稿件】人类正从IT时代慢慢走向DT时代,未来的竞争和传统行业的竞争不同,通过文字以及创新能力创造价值,通过拥有的数据给社会带来价值,用数据挣钱,这是未来竞争的核心所在。
面对海量数据,如何选择数据决策,哪些数据分析指标是我们所关心的,面对繁多的分析工具应该如何去选择,都会从本文中找到一些答案。
【讲师简介】
王劲,数果科技,联合创始人。曾任酷狗音乐大数据技术负责人,大数据架构师,负责酷狗大数据技术规划、建设、应用,经历酷狗音乐大数据平台从0到1的全程建设过程。
12年IT从业经验,5年大数据技术实践经验,2年分布式应用开发,1年移动互联网广告系统架构设计,多年的团队管理经验,主要研究方向流式计算、大数据存储计算、分布式存储系统、NoSQL、搜索引擎等。2016年1月,在技术社区发表<<经典大数据架构案例:酷狗音乐的大数据平台重构>>。
何为探索性数据分析
传统数据分析,首先要建立数据模型,通过模型的建立,不断抽取一些数据来验证这个模型。如果面向的数据很复杂,但是又想看到一些原始的数据特点、数据分布情况、某些属性的关系,或者哪些因素具有***量的信息,某些不确定关系,如何去研究?通过传统方法很难做到。因为首先把模型建立好,再抽取一些数据,可能是经过加工处理的,不是基于原始数据进行分析挖掘,而是基于一些汇总的数据,所以原始数据看不到了。
分析数据主要有两个阶段:探索和验证。传统做法只用了第二步验证,探索基本上用得很少。在探索阶段,主要是用元素发现数据中隐藏的有价值的信息,通过什么样的方法去做探索性数据分析,主要方法是EDA。在验证阶段,和传统做法一样,主要是验证模型的准确性,相对精确地研究一些具体情况,主要方法是传统的统计学方法。
什么是探索性数据分析?探索性数据分析简称EDA,是一种用于概括和可视化数据集的重要特征的数据分析方法。在约翰·杜克(John Tukey)的推动下,EDA侧重于对数据进行探讨,理解数据的底层结构和变量,对数据集形成直观认识,考虑该数据集是如何产生的,并决定如何使用更多的形式统计方法对它进行进一步的调查。
探索性数据分析的特点
一.在分析思路上让数据说话,不强调对数据的整理
传统方法在做数据挖掘分析的时候,首先是建模,再把数据做成一个规整的数据,再进行数据训练挖掘,而探索性数据分析首先是要基于原始数据发现数据的规律和价值。
二.EDA分析方法灵活,而不是拘泥于传统的统计方法
三.EDA分析工具简单直观,更易于普及
大数据时代的数据分析,从逻辑推理上讲,探索性数据分析属于归纳法(Induction)有别于从理论出发的演绎法(Deduction)。到了大数据时代,海量的无结构、半结构数据从多种渠道源源不断地积累,不受分析模型和研究假设的限制,如何从中找出规律并产生分析模型和研究假设成为新挑战。探索性数据分析在对数据进行概括性描述,发现变量之间的相关性以及引导出新的假设方面均大显身手。因此,探索性数据分析成为大数据分析中不可缺少的一步并且走向前台。高速处理海量数据的新技术加上数据可视化工具的日益成熟更推动了探索性数据分析的快速普及。
探索性大数据分析平台实现架构
首先,一款灵活强大的探索性大数据分析平台,应该具备实时分析秒级响应。支持多维的,维度上一定要支持上千个甚至上万维度的特性,指标的灵活定义。通过多种技术融合,构建统一数据平台,统一数据标准服务。还有一种是可视化运维。
平台设计准则有几下几点:1.不重复发明轮子,核心框架选用主流的、生态支持完善的成熟框架或技术,如Kafka、Storm、Hadoop、Druid等。尽可能简单,避免使用过多或过重的架构,造成系统的性能开销和运维负担。2.多种接口访问方式的支持。如:SQL(JDBC、ODBC)、Restful API。3.标准化,包括数据模型的标准化、数据分析的模板化等。4.高可用性。数据不丢、不重、有且只有一次,是分布式系统设计的关键。多种级别的HA,包括集群级别和进程级别的双重保护机制。5.容灾备份。包括跨数据中心的数据备份,应用的双活机制等。
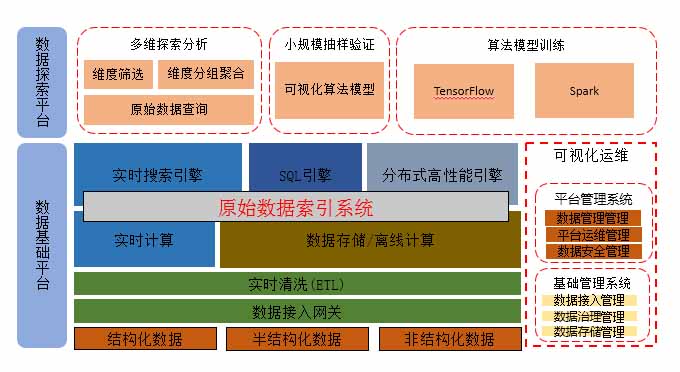
探索性大数据分析平台的架构,下面是数据基础平台,有几种数据源:结构化、非结构化、半结构化,这些数据通过网关统一接入,接入后进行实时清洗,这里的实时清洗只是对数据常规的简单处理,例如有一个IP地址,如果想找到其区域特性,省、市、运营商,假如是输入型或字符型如何去处理。
通过实时信息处理之后,进入存储层、实时计算层。现在大数据物理阶段,大部分停留在数据海量存储,已经很成熟了。需要考虑的是这种数据通过什么样的工作去分析,能够快速查询一些价值,需要选择哪一种方案更适合业务场景,更节省成本。
探索性大数据分析应用场景
王劲以建立垃圾电子邮件过滤器为例,对探索性大数据分析平台架构的实现进行了深入讲解。
背景:
电子邮件是自动积累的,各种商业广告常常充斥邮箱,每天都给用户带来很多不便。我们凭直觉和经验可以判断哪个是垃圾邮件,但人工清理这些垃圾很浪费时间。
分析过程:
***步,从大量邮件中随机抽样出100条(或更多),人工地将它们分成有用邮件和垃圾邮件。
第二步,用探索性数据分析对筛选出的垃圾邮件进行分析统计出哪类词汇出现的机率***。
第三步,以选出的词为基础建立初始邮件过滤模型并开发邮件过滤软件程序,然后用它对一个大样本(1000或更大)进行垃圾邮件的过滤试验。
第四步,对过滤器筛选出的垃圾邮件进行人工验证,用探索性数据分析计算过滤的总成功率和每个词的出现率。
第五步,用成功率和出现率的结果进一步改进过滤模型,并在邮件处理过程中增加过滤器,根据事先定好的临界点(Threshold),增加或减少过滤词汇的功能(机器学习)。这样,该垃圾邮件过滤器将不断地自我改进以提高过滤的成功率。
第六步,应用数据可视化技术,各个阶段的探索性数据分析结果都可以实时地用动态图表展示。
总结:
从这个过程中我们可以看到:
探索性数据分析能帮助我们从看似混乱无章的原始数据中筛选出可用的数据,在数据清理中发挥重要作用。探索性数据分析是建立算法和过滤模型的***步,能通过数据碰撞发现新假设,通过机器学习不断的改进和提高算法的精准度。探索性数据分析的结果,通过数据可视化展示,可以为邮件过滤器的开发随时提供指导和修正信息。
本文由王劲于2016年8月,在WOT2016移动互联网技术峰会数据分析专场《构建探索性大数据分析平台》主题演讲整理而成。WOT2016大数据峰会将于2016年11月25-26日在北京粤财JW万豪酒店召开,届时,数十位大数据领域一线专家、数据技术先行者将齐聚现场,在围绕机器学习、实时计算、系统架构、NoSQL技术实践等前沿技术话题展开深度交流和沟通探讨的同时,分享大数据领域***实践和最热门的行业应用。了解WOT2016大数据技术峰会更多信息,请登陆大会官网:http://wot.51cto.com/2016bigdata/
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】