最新的KDnuggets调查统计了数据科学家们实际工作中最常使用的算法,在大多数学术和产业界,都有惊人发现哦!
根据Gregory Piatetsky, KDnuggets,最新的调查问题是:在最近的12个月中,你在实际数据科学相关应用中用到了那些模型/算法?
于是就有了以下基于844份答卷的结果。
◆ ◆ ◆
排名前十的算法和它们在投票者中所占比例

图1:数据科学家最常用的10大算法,所有算法见文末表格
每个受访者平均用到了8.1种算法,这相比于 2011 的相似调查显示的结果有了巨大的增长。
相比2011年对数据分析算法的调查,我们注意到最常用的方法仍然是回归,聚类,决策树/规则以及可视化。比例增幅最大的是(增幅=%2016/%2011 -1):
Boosting算法,提升了40%。由2011年的23.5%提升倒2016年的40%
文本挖掘(Text Mining),提升了30%。从27.7%提升到35.9%
可视化(Visualization),提升了27%。从38.3%提升到48.7%
时间序列/序列分析(Time series/Sequence analysis),提升了25%。从29.6%提升到37.0%
异常检测(Anomaly/Deviation detection),提升了19%,从16.4%提升到19.5%
组合方法(Ensemble methods),提升了19%,从28.3%提升到33.6%
支持向量机(SVM),提升了18%,从28.6%提升到33.6%
回归(Regression),提升了16%,从57.9%提升到67.1%
◆ ◆ ◆
2016年新秀中最为流行的是
K-最近邻法(K-nearestneighbors), 46%
主成分分析(PCA), 43%
随机森林(Random Forests), 38%
优化(Optimization), 24%
神经网络-深度学习(Neural networks - Deep Learning), 19%
奇异值分解(Singular ValueDecomposition), 16%
◆ ◆ ◆
降幅最大的是
关联规则(Associationrules),下降了47%,从28.6%降为15.3%
Uplift modeling,下降了36%,从4.8% 降为3.1%(出人意料的低,因为有很多相关文献发表)
因子分析(Factor Analysis),下降了24%,从18.6%降为14.2%
存活分析(SurvivalAnalysis),下降了15%,从9.3%将为7.9%
下面的表格显示了不同的算法类型的使用场所:监督算法,无监督算法,元算法和其它算法。应用类型未知(NA,4.5%)或者其它职业类型(3%)的不包括在内。
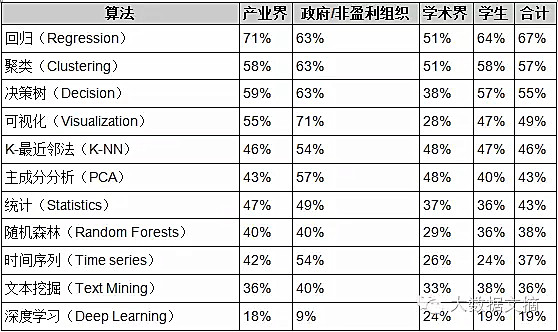
表1:不同职业类型的算法使用
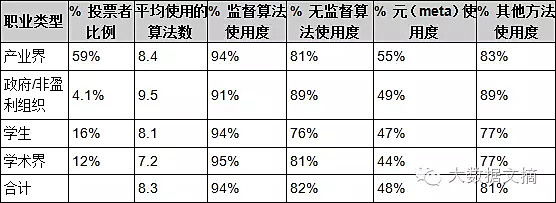
我们注意到,几乎所有的人都在使用监督学习算法。政府和产业界的数据科学家们使用的算法类型比学生和科学界要多。产业数据科学家们更倾向于使用元算法。
◆ ◆ ◆
不同职业类型最常用的10大算法+深度学习情况
接下来,我们分析了不同职业类型最常用的10大算法+深度学习情况
表2: 不同职业类型的10大算法+深度学习
为了更清楚地展示这些差异,我们用一个公式来计算不同职业类型的算法使用率偏倚:
偏倚=某种职业类型的算法使用率/所有职业类型的算法使用率-1
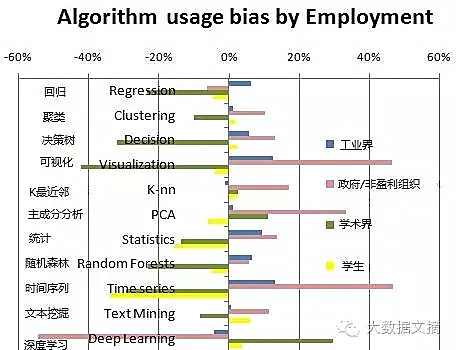
图2:不同场所的算法使用率偏倚
我们注意到,产业数据科学家们更倾向于用回归,可视化,统计,随机森林和时间序列。政府/非盈利组织则更倾向于使用可视化,主成分分析和时间序列。学术界的研究人员们更多的用到主成分分析和深度学习。学生们普遍使用的算法较少,但多用到文本挖掘和深度学习。
接下来,我们看看某一具体地域的参与度,表示整体的KDnuggets用户。
参与调查人员的地区分布:
美国/加拿大, 40%
欧洲, 32%
亚洲, 18%
拉丁美洲, 5.0%
非洲/中东, 3.4%
澳大利亚/新西兰, 2.2%
在2011年的调查中,我们把产业和政府两个行业的被调查者合为一组,把学术研究者和学生合为一组,然后计算行业政府组的算法使用亲切度:
(行业政府组的算法使用率/学术学生组的算法使用率)/(行业政府组的人数/学术学生组的人数)-1
因此,亲切度为0的算法表示它在产业/政府组和学术学生组使用率相同。越高IG亲切度说明该算法越偏向于产业,结果越小则算法越偏向于学术。
最偏向于“产业算法”是:
uplifting modelling, 2.01
异常检测, 1.61
存活分析, 1.39
因子分析, 0.83
时间序列/序列分析, 0.69
关联规则, 0.5
尽管uplift modeling再次成为最偏向于“行业算法”,令人吃惊的却是它使用率极低,只有3.1%,是整个调查中比例最低的。
最偏向于“学术算法”是:
神经网络, -0.35
朴素贝叶斯, -0.35
支持向量机, -0.24
深度学习, -0.19
最大期望, -0.17
下图显示了所有算法及其产业/学术亲切度。
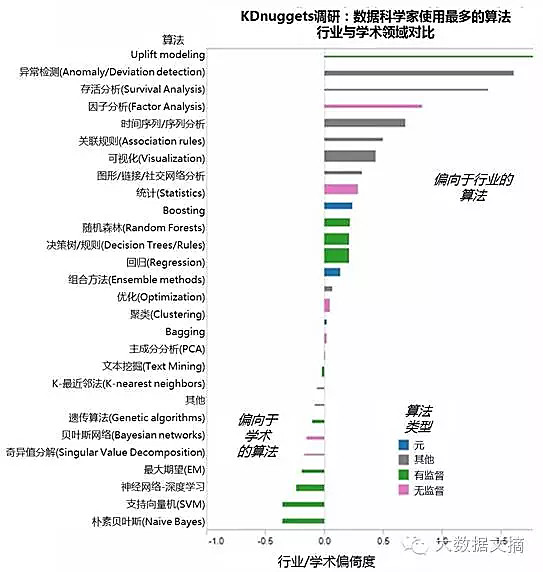
图3:KDnuggets调研:数据科学家使用最多的算法:产业与学术领域对比
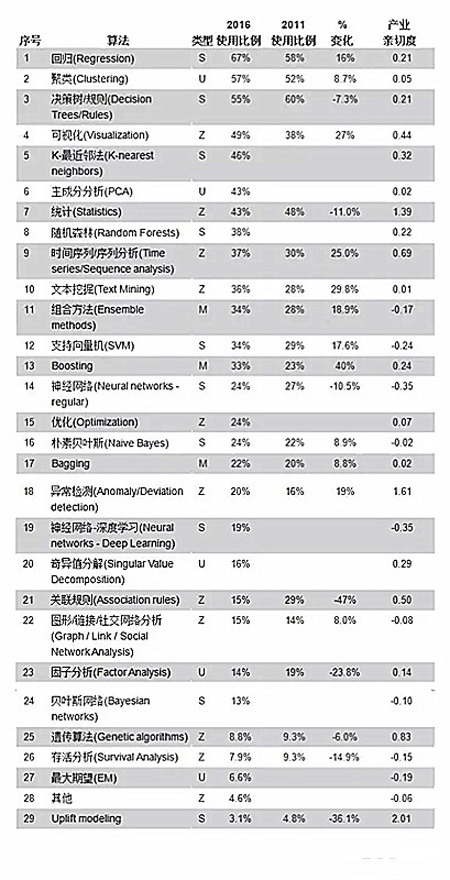
下表是所有算法调研结果的细节,分别是2016年受访人群使用比例,2011年使用比例,变化(2016年比例/2011年比例-1)以及上文提及的产业亲切度。
表3:KDnuggets2016调研:数据科学家使用的算法
下方的表格是所有算法的调研结果细节,不同列依次代表的是:
排名: 根据使用比例的排名
算法:算法名称
类型: S – 有监督, U – 无监督, M – 元(meta), Z – 其他方法,
在2016年调查中使用该算法的人数比例
在2016年调查中使用该算法的人数比例
变化:(%2016 / %2011 -1),
产业亲切度见上文的解释.
表4:KDnuggets 2016 调研:数据科学家使用的算法