尽管我们对百度今年工作焦点的关注集中在这个中国搜索巨头在深度学习方面的举措上,许多其他的关键的,尽管不那么前沿的应用表现出了大数据带来的挑战。
正如百度的欧阳剑在本周 Hot Chips 大会上谈论的,百度坐拥超过 1 EB 的数据,每天处理大约 100 PB 的数据,每天更新 100 亿的网页,每 24 小时更新处理超过 1 PB 的日志更新,这些数字和 Google 不分上下,正如人们所想象的。百度采用了类似 Google 的方法去大规模地解决潜在的瓶颈。
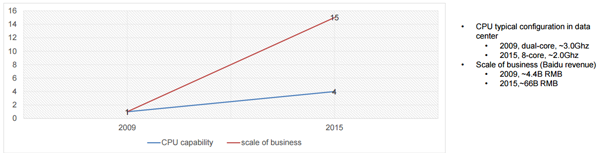
正如刚刚我们谈到的,Google 寻找一切可能的方法去打败摩尔定律,百度也在进行相同的探索,而令人激动的、使人着迷的机器学习工作是迷人的,业务的核心关键任务的加速同样也是,因为必须如此。欧阳提到,公司基于自身的数据提供高端服务的需求和 CPU 可以承载的能力之间的差距将会逐渐增大。
对于百度的百亿亿级问题,在所有数据的接受端是一系列用于数据分析的框架和平台,从该公司的海量知识图谱,多媒体工具,自然语言处理框架,推荐引擎,和点击流分析都是这样。简而言之,大数据的首要问题就是这样的:一系列各种应用和与之匹配的具有压倒性规模的数据。
当谈到加速百度的大数据分析,所面临的几个挑战,欧阳谈到抽象化运算核心去寻找一个普适的方法是困难的。“大数据应用的多样性和变化的计算类型使得这成为一个挑战,把所有这些整合成为一个分布式系统是困难的,因为有多变的平台和编程模型(MapReduce,Spark,streaming,user defined,等等)。将来还会有更多的数据类型和存储格式。”
尽管存在这些障碍,欧阳讲到他们团队找到了(它们之间的)共同线索。如他所指出的那样,那些把他们的许多数据密集型的任务相连系在一起的就是传统的 SQL。“我们的数据分析任务大约有 40% 是用 SQL 写的,而其他的用 SQL 重写也是可用做到的。” 更进一步,他讲道他们可以享受到现有的 SQL 系统的好处,并可以和已有的框架相匹配,比如 Hive,Spark SQL,和 Impala 。下一步要做的事情就是 SQL 查询加速,百度发现 FPGA 是***的硬件。

这些主板,被称为处理单元( 下图中的 PE ),当执行 SQL 时会自动地处理关键的 SQL 功能。这里所说的都是来自演讲,我们不承担责任。确切的说,这里提到的 FPGA 有点神秘,或许是故意如此。如果百度在基准测试中得到了如下图中的提升,那这可是一个有竞争力的信息。后面我们还会继续介绍这里所描述的东西。简单来说,FPGA 运行在数据库中,当其收到 SQL 查询的时候,该团队设计的软件就会与之紧密结合起来。
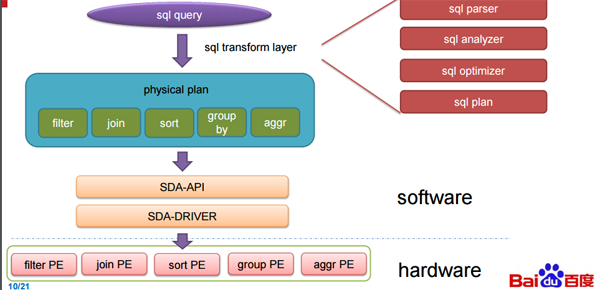
欧阳提到了一件事,他们的加速器受限于 FPGA 的带宽,不然性能表现本可以更高,在下面的评价中,百度安装了 2 块12 核心,主频 2.0 GHz 的 intl E26230 CPU,运行在 128G 内存。SDA 具有 5 个处理单元,(上图中的 300MHz FPGA 主板)每个分别处理不同的核心功能(筛选(filter),排序(sort),聚合(aggregate),联合(join)和分组(group by))
为了实现 SQL 查询加速,百度针对 TPC-DS 的基准测试进行了研究,并且创建了称做处理单元(PE)的特殊引擎,用于在基准测试中加速 5 个关键功能,这包括筛选(filter),排序(sort),聚合(aggregate),联合(join)和分组(group by),(我们并没有把这些单词都像 SQL 那样大写)。SDA 设备使用卸载模型,具有多个不同种类的处理单元的加速卡在 FPGA 中组成逻辑,SQL 功能的类型和每张卡的数量由特定的工作量决定。由于这些查询在百度的系统中执行,用来查询的数据被以列格式推送到加速卡中(这会使得查询非常快速),而且通过一个统一的 SDA API 和驱动程序,SQL 查询工作被分发到正确的处理单元而且 SQL 操作实现了加速。
SDA 架构采用一种数据流模型,加速单元不支持的操作被退回到数据库系统然后在那里本地运行,比其他任何因素,百度开发的 SQL 加速卡的性能被 FPGA 卡的内存带宽所限制。加速卡跨整个集群机器工作,顺便提一下,但是数据和 SQL 操作如何分发到多个机器的准确原理没有被百度披露。
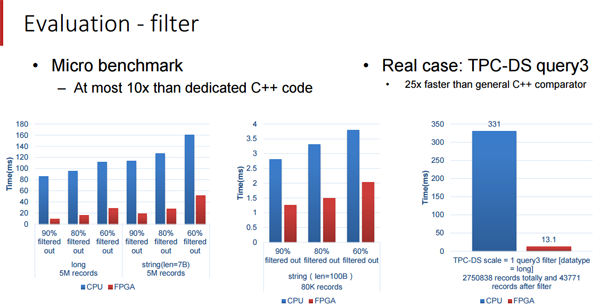
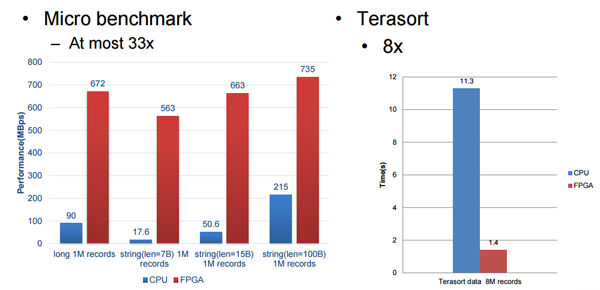
我们受限与百度所愿意披露的细节,但是这些基准测试结果是十分令人鼓舞的,尤其是 Terasort 方面,我们将在 Hot Chips 大会之后跟随百度的脚步去看看我们是否能得到关于这是如何连接到一起的和如何解决内存带宽瓶颈的细节。