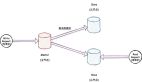
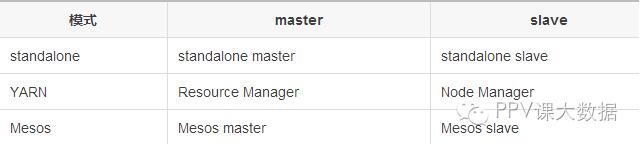
Spark有三种集群部署模式,或者叫做集群管理模式。分别是standalone,YARN和Mesos。这三种模式其实都是master/slave模式。
那么在实际的项目中,我们该如何对比选择呢?下面是我的一些总结,主要参考了:
Which Apache Spark Cluster Managers Are The Right Fit? YARN, Mesos, or Standalone?
三种集群资源管理概述

Spark Standalone
作为Spark的一部分,Standalone是一个简单的集群管理器。它具有master的HA,弹性应对WorkerFailures,对每个应用程序的管理资源的能力,并且可以在现有的Hadoop一起运行和访问HDFS的数据。该发行版包括一些脚本,可以很容易地部署在本地或在AmazonEC2云计算。它可以在Linux,Windows或Mac OSX上运行。
Apache Mesos
Apache Mesos ,分布式系统内核,具有HA的masters和slaves,可以管理每个应用程序的资源,并对Docker容器有很好的支持。它可以运行Spark工作, Hadoop的MapReduce的,或任何其他服务的应用程序。它有Java, Python和C ++ 的API。它可以在Linux或Mac OSX上运行。
Hadoop YARN
Hadoop YARN,作业调度和集群资源管理的分布式计算框架,具有HA为masters和slaves,在非安全模式下支持Docker容器,在安全模式下支持 Linux和Windows container executors,和可插拔的调度器。它可以运行在Linux和Windows上运行。
集群资源调度能力的对比
模式资源调度能力比对SecurityHA
- standalone 只支持FIFO调度器,单用户串行,默认所有节点的所有资源对应用都可用,node节点的限制,cpu内存等限制可以通过SparkConf来控制 shared secret ,SSL for data encryptionStandby Masters with ZooKeeper和本地文件系统的单点恢复
- YARN 支持资源调度器Scheduler,应用管理器ApplicationsManager。CapacityScheduler和 FairScheduler在队列的范围内,资源共享。Kerberos。SSL for data encryption主备切换的HA方式,依赖于zookeeper,但不需要单独的zkfc进程
- Mesos看下方:插件式安全模块,默认Cyrus SASL,SSL for data encryption一主多备,基于zookeeper的leader选举
Mesos的资源调度能力描述
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个 Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,***程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,mesos的master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上可以认为,每个应用程序利用mesos搭建了一个虚拟集群自己使用。
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动 executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
笔者总结
- 从对比上看,mesos似乎是Spark更好的选择,也是被官方推荐的
- 但如果你同时运行hadoop和Spark,从兼容性上考虑,Yarn似乎是更好的选择,毕竟是亲生的。Spark on Yarn运行的也不错。
- 如果你不仅运行了hadoop,spark。还在资源管理上运行了docker,Mesos似乎更加通用。
- standalone小规模计算集群,似乎更适合!