作者简介:
梁定安,现就职于腾讯社交网络运营部,负责社交平台、增值业务的运维负责人;开放运维联盟委员;腾讯云布道师;腾讯课堂运维讲师。
SNG社交网络运营部管理着近10万台的Linux服务器,以此支撑着腾讯社交业务海量业务与用户,如日活2.47亿的QQ、月活5.96亿的QQ空间(数据来源:腾讯2016Q2财报)等众多***在线的胖子业务。
面对业务体量的不断增胖的社交类UGC业务,如何能既保证业务的发展,又能有效的控制运营成本的增长?是运维团队迫在眉睫要解决的运营成本难题。经过不断的探索和深挖,我们庆幸
在过去的2年中,找到了一条有效的设备成本管理的路子——精细化容量管理的设备成本优化之路,并连续2年,每年为公司节约过亿的运营成本。
众所周知,提升设备的使用率是运维界常用的管控运营成本的有效办法,那么如何能够针对不同的设备使用场景、不同的设备类型制定出适宜的度量与管理办法呢?请看腾讯运维在实践中总结出的6个方法:
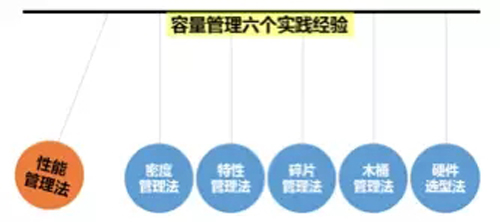
方法1:性能管理法
在衡量服务器的使用合理性中,CPU使用率当仁不让的成为头号被关注对象。随着多核超线程技术CPU的普及,CPU负载不均的问题逐渐在海量运维场景下,成为了设备运营成本的吞噬者。

为了发现并优化多核CPU负载不均的现象,我们提出了CPU极差的度量指标,
CPU(极差)=CPU(max)-CPU(min),若CPU(极差)>30%,则该设备存在CPU使用率不合理的问题,需优化整改。(备注:优化方法可参考多队列网卡优化与CPU亲和,本文不展开)。
同理,在分布式集群的模块容量管理中,运维规范要求实现模块的一致性管理,包括容量一致性,为此我们同样提出模块的容量极差的度量指标,模块CPU使用率极差= CPU***的IP的CPU使用率 - CPU***的设备的CPU使用率,若同模块下不同设备的CPU使用率极差>30%,则该模块容量使用不合理,需要优化整改。(备注:一般此类情况源于配置、权重、调度等不一致管理问题,不问不展开。)
方法2:密度管理法
对于内存使用的合理性,很难直接用内存使用率来度量,为此,在内存型设备使用中,我们提出了密度管理的管控办法——访问密度。访问密度计算公式:,模块下的设备内存访问密度应该一致,否则纳入负载不均的一致性整改范畴。通过对全量内存型模块访问密度的统计分析,我们可以得出一条平均负载水平线,结合容量管理的实际需要,提高平均水平线或优化低于水平线的模块,都能实现优化设备成本管理的目的。同时,密度管理法也适用于SSD盘的使用场景。(备注:访问密度会受业务请求包大小的影响,但是在海量的运维场景下,个别情况可以忽略。)
方法3:特性管理法
特性管理法,同功能模块的QPS管理类似,就是用来衡量在特定业务场景下,业务逻辑的处理性能是否***,要结合不同产品下的同类应用场景的QPS同比来得出分析结论。这种管理办法因业务逻辑而异,本文主要举例说明下。
例如,在移动互联网的业务运维场景中,有些场景是非常规容量管理手段能度量的,针对一些个性但是规模庞大的模块,我们提出了特性管理法。举个例子,QQ、QQ空间、信鸽等业务都有长连接功能模块,该场景的容量CPU少而使用内存多,因此可以使用每G内存维持的长连接数量来横向比较QQ、QQ空间、信鸽等业务,督促性能低的业务程序整改优化。
又例如,在直播场景中,有对主播视频实时在线转码的需求,不同的开发可能使用的转码技术方案不一,也可以利用同样的特性管理法来衡量在线转码的性能是否有优化空间。
方法4:碎片管理法
腾讯社交网络业务历史悠久,从“大哥”QQ到“新秀”企鹅FM,业务类型覆盖IM、UGC、多媒体、阅读、动漫、游戏、直播等主流的娱乐化社交玩法,其中有当红的产品,也有长尾的产品;有几十亿次每秒功能模块,也有几十次每秒的功能模块。碎片化管理法,就是针对请求量不高的小集群准备的。因为分布式高可用的运维要求,通常生产环境的部署最小单元都为2台设备,在物理机时代,访问量小的模块浪费成本严重,但随着虚拟化技术的广泛应用,该场景遇到的问题迎刃而解。利用虚拟化技术将硬件资源碎片化,让小模块可以很好的兼顾设备成本和高可用。
与虚拟化解决碎片资源利用率的方案类似,我们还有PaaS平台“蜂巢”,基于腾讯社交的标准开发框架SPP,解决小业务小模块的容量管理难题。(后续专题聊蜂巢。)
方法5:木桶管理法
腾讯平台级的业务,如QQ、QQ空间、QQ音乐等,基本上都普及了三地三活的SET(专区)容灾架构能力,这是真正意义上的异地多活。(正巧在923上海运维大会的海量运维专场,会有个主题与异地容灾的海量运维实践分享,如果大家感兴趣的话,诚邀大家参加。)对于平台级业务的运维,我们会根据运维规范管理的要求,将实现一定业务场景的多个模块划分为SET(减少运维对象),在不同的社交场景下,我们就得出了各种不同类型的SET,通过自动化运维能力扩大到SET的自动化运维能力,运维能很轻松的实现SET异地化部署,如此实现该业务场景异地多活的容灾容错。
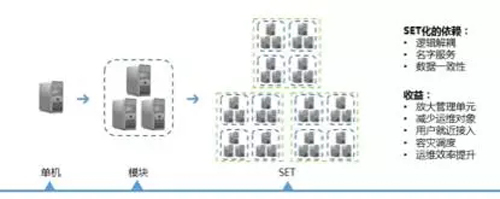
再说SET的容量管理,平台级SET就意味着用户量和请求量不会暴增,那么对于SET的可运维性而言,我们必须要对SET的请求量和用户量等指标进行量化度量。为此,运维赋予SET一个可量化的指标,在我们的场景下,如在线用户数、核心请求量等视SET的用途而定,基于压测可以得到单SET的最合理的容量值,该值符合木桶原理,也就是我们的木桶管理法,SET由多个模块组成(SET=木桶,模块=木板),支撑一定的用户量,SET的容量管理就像木桶原理一样,木桶的水位高低取决于最短板,因此SET的***容量取决于SET中性能***的模块容量。
腾讯的平台级业务同时在线用户数是相对稳定的,也就意味着全国要实现多地多活,需要准备多少冗余容量是可预期可规划的,换而言之,要部署的SET的数量是能被提前量化的。同时,结合业务的自动化部署、调度方案、柔性策略和有损服务能力,我们就可以利用很合理的成本就能实现异地多活。
举例说明,假设我们共有1000w的同时在线用户,且用户量相对稳定,我们就可以规划3个支撑500w在线的SET,利用业务架构的调度能力分别让3个SET的容量平均化,在灾难场景时,1个SET不可用,另外两个SET可以完全容灾,在此规划下,极端场景2个SET不可用是要开有损服务的。通过量化SET管理,业务运维则可以灵活的根据成本管理的需求调整SET的容量水位,以达到***性价比的高可用架构。
方法6:硬件选型法
关注硬件瓶颈,升级硬件降低单机运营成本。比如,过去做UGC内存存储时(QQ相册、视频),使用了大量2T硬盘,当4T、8T硬盘成本量产使用,及时的升级硬盘容量,可以有效的提升单机存储量,以规模效应实现花小价格换来了大成本。又如,在图片社交或视频社交的业务场景下,因玩法的多样性需求,会延伸出很多计算量繁重的逻辑,像人脸识别、鉴黄等功能,这时候选用GPU设备代替CPU设备,也是让性能飞的一种有效做法。(该方法尤为适用于UGC类的存储量只增不减的业务,如微云、网盘、图片存储、视频存储等。)
后记:
包括但不限于上述6种容量管理的方法,使得我们能在用户数据只增不减社交UGC业务中,能稳步的可持续前行。设备成本管理还涉及很多细节的技术手段和业务代码优化,本文只是从运维的视角阐述对容量管理的思考,希望能够抛砖引玉,对各位同行有帮助。带宽成本管理的优化带来的成本节省价值会更大,因为其中涉及的技术点和方法论更多,此文不深入探讨。