HashMap在Java开发中有着非常重要的角色地位,每一个Java程序员都应该了解HashMap。详细地阐述HashMap中的几个概念,并深入探讨HashMap的内部结构和实现细节,讨论HashMap的性能问题。
我们先来看这样的一道面试题:
在 HashMap 中存放的一系列键值对,其中键为某个我们自定义的类型。放入 HashMap 后,我们在外部把某一个 key 的属性进行更改,然后我们再用这个 key 从 HashMap 里取出元素,这时候 HashMap 会返回什么?
文中已给出示例代码与答案,但关于HashMap的原理没有做出解释。
1. 特性
我们可以用任何类作为HashMap的key,但是对于这些类应该有什么限制条件呢?且看下面的代码:
- public class Person {
- private String name;
- public Person(String name) {
- this.name = name;
- }
- }
- Map<Person, String> testMap = new HashMap<>();
- testMap.put(new Person("hello"), "world");
- testMap.get(new Person("hello")); // ---> null
本是想取出具有相等字段值Person类的value,结果却是null。对HashMap稍有了解的人看出来——Person类并没有override hashcode方法,导致其继承的是Object的hashcode(返回是其内存地址)。这也是为什么常用不变类如String(或Integer等)做为HashMap的key的原因。那么,HashMap是如何利用hashcode给key做快速索引的呢?
2. 原理
首先,我们来看《Thinking in Java》中一个简单HashMap的实现方案:
- //: containers/SimpleHashMap.java
- // A demonstration hashed Map.
- import java.util.*;
- import net.mindview.util.*;
- public class SimpleHashMap<K,V> extends AbstractMap<K,V> {
- // Choose a prime number for the hash table size, to achieve a uniform distribution:
- static final int SIZE = 997;
- // You can't have a physical array of generics, but you can upcast to one:
- @SuppressWarnings("unchecked")
- LinkedList<MapEntry<K,V>>[] buckets =
- new LinkedList[SIZE];
- public V put(K key, V value) {
- V oldValue = null;
- int index = Math.abs(key.hashCode()) % SIZE;
- if(buckets[index] == null)
- buckets[index] = new LinkedList<MapEntry<K,V>>();
- LinkedList<MapEntry<K,V>> bucket = buckets[index];
- MapEntry<K,V> pair = new MapEntry<K,V>(key, value);
- boolean found = false;
- ListIterator<MapEntry<K,V>> it = bucket.listIterator();
- while(it.hasNext()) {
- MapEntry<K,V> iPair = it.next();
- if(iPair.getKey().equals(key)) {
- oldValue = iPair.getValue();
- it.set(pair); // Replace old with new
- found = true;
- break;
- }
- }
- if(!found)
- buckets[index].add(pair);
- return oldValue;
- }
- public V get(Object key) {
- int index = Math.abs(key.hashCode()) % SIZE;
- if(buckets[index] == null) return null;
- for(MapEntry<K,V> iPair : buckets[index])
- if(iPair.getKey().equals(key))
- return iPair.getValue();
- return null;
- }
- public Set<Map.Entry<K,V>> entrySet() {
- Set<Map.Entry<K,V>> set= new HashSet<Map.Entry<K,V>>();
- for(LinkedList<MapEntry<K,V>> bucket : buckets) {
- if(bucket == null) continue;
- for(MapEntry<K,V> mpair : bucket)
- set.add(mpair);
- }
- return set;
- }
- public static void main(String[] args) {
- SimpleHashMap<String,String> m =
- new SimpleHashMap<String,String>();
- m.putAll(Countries.capitals(25));
- System.out.println(m);
- System.out.println(m.get("ERITREA"));
- System.out.println(m.entrySet());
- }
- }
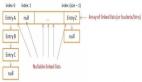
SimpleHashMap构造一个hash表来存储key,hash函数是取模运算Math.abs(key.hashCode()) % SIZE,采用链表法解决hash冲突;buckets的每一个槽位对应存放具有相同(hash后)index值的Map.Entry,如下图所示:
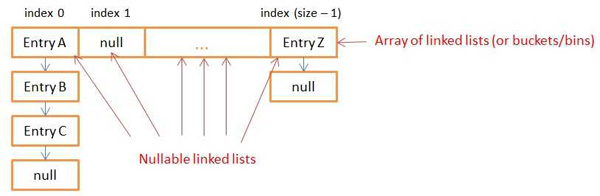
JDK的HashMap的实现原理与之相类似,其采用链地址的hash表table存储Map.Entry:
- /**
- * The table, resized as necessary. Length MUST Always be a power of two.
- */
- transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
- static class Entry<K,V> implements Map.Entry<K,V> {
- final K key;
- V value;
- Entry<K,V> next;
- int hash;
- …
- }
Map.Entry的index是对key的hashcode进行hash后所得。当要get key对应的value时,则对key计算其index,然后在table中取出Map.Entry即可得到,具体参看代码:
- public V get(Object key) {
- if (key == null)
- return getForNullKey();
- Entry<K,V> entry = getEntry(key);
- return null == entry ? null : entry.getValue();
- }
- final Entry<K,V> getEntry(Object key) {
- if (size == 0) {
- return null;
- }
- int hash = (key == null) ? 0 : hash(key);
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- ee = e.next) {
- Object k;
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- return e;
- }
- return null;
- }
可见,hashcode直接影响HashMap的hash函数的效率——好的hashcode会极大减少hash冲突,提高查询性能。同时,这也解释开篇提出的两个问题:如果自定义的类做HashMap的key,则hashcode的计算应涵盖构造函数的所有字段,否则有可能得到null。