在对不平衡的分类数据集进行建模时,机器学习算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带有误导性。那么,这种结果是为何发生的呢?到底是什么因素影响了这些算法的表现?
在不平衡的数据中,任一算法都没法从样本量少的类中获取足够的信息来进行精确预测。因此,机器学习算法常常被要求应用在平衡数据集上。那我们该如何处理不平衡数据集?本文会介绍一些相关方法,它们并不复杂只是技巧性比较强。
本文会介绍处理非平衡分类数据集的一些要点,并主要集中于非平衡二分类问题的处理。一如既往,我会尽量精简地叙述,在文末我会演示如何用R中的ROSE包来解决实际问题。
什么是不平衡分类
不平衡分类是一种有监督学习,但它处理的对象中有一个类所占的比例远远大于其余类。比起多分类,这一问题在二分类中更为常见。(注:下文中占比较大的类称为大类,占比较小的类称为小类)
不平衡一词指代数据中响应变量(被解释变量)的分布不均衡,如果一个数据集的响应变量在不同类上的分布差别较大我们就认为它不平衡。
举个例子,假设我们有一个观测数为100000的数据集,它包含了哈佛大学申请人的信息。众所周知,哈佛大学以极低的录取比例而闻名,那么这个数据集的响应变量(即:该申请人是否被录取,是为1,否为0)就很不平衡,大致98%的观测响应变量为0,只有2%的幸运儿被录取。
在现实生活中,这类例子更是不胜枚举,我在下面列举了一些实例,请注意他们的不平衡度是不一样的。
- 一个自动产品质量检测机每天会检测工厂生产的产品,你会发现次品率是远远低于合格率的。
- 某地区进行了居民癌症普查,结果患有癌症的居民人数也是远远少于健康人群。
- 在信用卡欺诈数据中,违规交易数比合规交易少不少。
- 一个遵循6δ原则的生产车间每生产100万个产品才会产出10个次品。
生活中的例子还有太多,现在你可以发现获取这些非平衡数据的可能性有多大,所以掌握这些数据集的处理方法也是每个数据分析师的必修课。
为什么大部分机器学习算法在不平衡数据集上表现不佳?
我觉得这是一个很有意思的问题,你不妨自己先动手试试,然后你就会了解把不平衡数据再结构化的重要性,至于如何再结构化,我会在操作部分中讲解。
下面是机器学习算法在不平衡数据上精度下降的原因:
- 响应变量的分布不均匀使得算法精度下降,对于小类的预测精度会很低。
- 算法本身是精度驱动的,即该模型的目标是最小化总体误差,而小类对于总体误差的贡献很低。
- 算法本身假设数据集的类分布均衡,同时它们也可能假定不同类别的误差带来相同的损失(下文会详细叙述)。
针对不平衡数据的处理方法
这类处理方法其实就是大名鼎鼎的“采样法”,总的说来,应用这些方法都是为了把不平衡数据修正为平衡数据。修正方法就是调整原始数据集的样本量,使得不同类的数据比例一致。
而在诸多学者研究得出基于平衡数据的模型整体更优的结论后,这一类方法越来越受到分析师们的青睐。
下列是一些具体的处理方法名称:
- 欠采样法(Undersampling)
- 过采样法(Oversampling)
- 人工数据合成法(Synthetic Data Generation)
- 代价敏感学习法(Cose Sensitive Learning)
让我们逐一了解它们。
1.欠采样法
该方法主要是对大类进行处理。它会减少大类的观测数来使得数据集平衡。这一办法在数据集整体很大时较为适宜,它还可以通过降低训练样本量来减少计算时间和存储开销。
欠采样法共有两类:随机(Random)的和有信息的(Informative)。
随机欠采样法会随机删除大类的观测直至数据集平衡。有信息的欠采样法则会依照一个事先制定的准则来删去观测。
有信息的欠采样中,利用简易集成算法(EasyEnsemble)和平衡级联算法(BalanceCascade)往往能得到比较好的结果。这两种算法也都很直白易懂。
简易集成法:首先,它将从大类中有放回地抽取一些独立样本生成多个子集。然后,将这些子集和小类的观测合并,再基于合并后的数据集训练多个分类器,以其中多数分类器的分类结果为预测结果。如你所见,整个流程和无监督学习非常相似。
平衡级联法:它是一种有监督的学习法,首先将生成多个分类器,再基于一定规则系统地筛选哪些大类样本应当被保留。
但欠采样法有一个显而易见的缺陷,由于要删去不少观测,使用该方法会使得大类损失不少重要信息。
2.过采样法
这一方法针对小类进行处理。它会以重复小类的观测的方式来平衡数据。该方法也被称作升采样(Upsampling)。和欠采样类似,它也能分为随机过采样和有信息的过采样两类。
随机过采样会将小类观测随机重复。有信息过采样也是遵循一定的准则来人工合成小类观测。
使用该方法的一大优势是没有任何信息损失。缺点则是由于增加了小类的重复样本,很有可能导致过拟合(译者注:计算时间和存储开销也增大不少)。我们通过该方法可以在训练集上得到非常高的拟合精度,但在测试集上预测的表现则可能变得愈发糟糕。
3.人工数据合成法
简单说来,人工数据合成法是利用生成人工数据而不是重复原始观测来解决不平衡性。它也是一种过采样技术。
在这一领域,SMOTE法(Synthetic Minority Oversampling Technique)是有效而常用的方法。该算法基于特征空间(而不是数据空间)生成与小类观测相似的新数据(译者注:总体是基于欧氏距离来度量相似性,在特征空间生成一些人工样本,更通俗地说是在样本点和它近邻点的连线上随机投点作为生成的人工样本,下文叙述了这一过程但有些晦涩)。我们也可以说,它生成了小类观测的随机集合来降低分类器的误差。
为了生成人工数据,我们需要利用自助法(Bootstrapping)和K近邻法(K-neraest neighbors)。详细步骤如下:
- 计算样本点间的距离并确定其近邻。
- 生成一个0到1上的均匀随机数,并将其乘以距离。
- 把第二步生成的值加到样本点的特征向量上。
- 这一过程等价于在在两个样本的连线上随机选择了一个点。
R中有一个包专门用来实现SMOTE过程,我们将在实践部分做演示。
4.代价敏感学习(CSL)
这是另一种常用且有意思的方法。简而言之,该方法会衡量误分类观测的代价来解决不平衡问题。
这方法不会生成平衡的数据集,而是通过生成代价矩阵来解决不平衡问题。代价矩阵是描述特定场景下误分类观测带来的损失的工具。近来已有研究表明,代价敏感学习法很多时候比采样法更优,因此这种方法也值得一学。
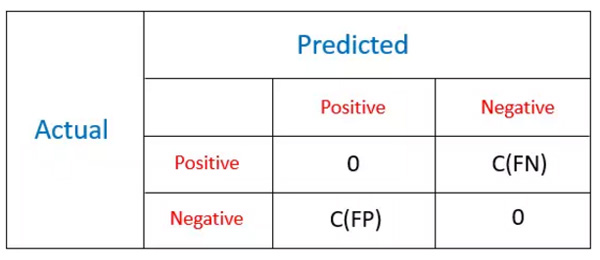
让我们通过一个例子来了解该方法:给定一个有关行人的数据集,我们想要了解行人是否会携带炸弹。数据集包含了所有的必要信息,且携带炸弹的人会被标记为正类,不带炸弹的就是负类。现在问题来了,我们需要把行人都分好类。让我们先来设定下这一问题的代价矩阵。
如果我们将行人正确分类了,我们不会蒙受任何损失。但如果我们把一个恐怖分子归为负类(False Negative),我们要付出的代价会比把和平分子归为正类(False Positive)的代价大的多。
代价矩阵和混淆矩阵类似,如下所示,我们更关心的是伪正类(FP)和伪负类(FN)。只要观测被正确分类,我们不会有任何代价损失。
该方法的目标就是找到一个使得总代价最小的分类器:
Total Cost = C(FN)xFN + C(FP)xFP
其中,
FN是被误分类的正类样本数
FP是被误分类的负类样本数
C(FN)和C(FP)分别代表FN和FP带来的损失。本例中C(FN) > C(FP)
除此之外,我们还有其他的比较前沿的方法来处理不平衡样本。比如基于聚类的采样法(Cluster based sampling),自适应人工采样法(adaptive synthetic sampling),边界线SMOTE(border line SMOTE),SMOTEboost,DataBoost-IM,核方法等。这些方法的基本思想和前文介绍的四类方法大同小异。还有一些更直观的方法可以帮助你提升预测效果:如利用聚类技术,把大类分为K个次类,每个此类的样本不重叠。再基于每个次类和小类的合并样本来训练分类器。最后把各个分类结果平均作为预测值。除此之外,也可以聚焦于获取更多数据来提高小类的占比。
应当使用哪类评价测度来评判精度?
选择合适的评价测度是不平衡数据分析的关键步骤。大部分分类算法仅仅通过正确分类率来衡量精度。但在不平衡数据中,使用这种方法有很大的欺骗性,因为小类对于整体精度的影响太小。
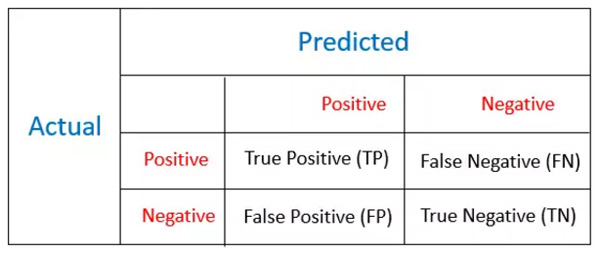
混淆矩阵和代价矩阵的差异就在于代价矩阵提供了跟多的误分类损失信息,其对角元素皆为0。而混淆举证只提供了TP,TN,FP,FN四类样本的比例,它常用的统计量则为正确率和错误率:
Accuracy: (TP + TN)/(TP+TN+FP+FN)
Error Rate = 1 – Accuracy = (FP+FN)/(TP+TN+FP+FN)
如前文所提,混淆矩阵可能会提供误导性结果,并且它对数据变动非常敏感。更进一步,我们可以从混淆矩阵衍生出很多统计量,其中如下测度就提供了关于不平衡数据精度的更好度量:
准确率(Preciosion):正类样本分类准确性的度量,即被标记为正类的观测中被正确分类的比例。
Precision = TP / (TP + FP)
召回率(Recall):所有实际正类样本被正确分类的比率。也被称作敏感度(Sensitivity)
Recall = TP / (TP + FN)
F测度(F measure):结合准确率和召回率作为分类有效性的测度。具体公式如下(ß常取1):
F measure = ((1 + β)² × Recall × Precision) / ( β² × Recall + Precision )
尽管这些测度比正确率和错误率更好,但总的说来对于衡量分类器而言还不够有效。比如,准确率无法刻画负类样本的正确率。召回率只针对实际正类样本的分类结果。这也就是说,我们需要寻找更好的测度来评价分类器。
谢天谢地!我们可以通过ROC(Receiver Operationg Characterstics)曲线来衡量分类预测精度。这也是目前广泛使用的评估方法。ROC曲线是通过绘制TP率(Sensitivity)和FP率(Specificity)的关系得到的。
Specificity = TN / (TN + FP)
ROC图上的任意一点都代表了单个分类器在一个给定分布上的表现。ROC曲线之所以有用是因为它提供了分类数据收益(TP)和损失(FP)的可视化信息。ROC曲线下方区域的面积(AUC)越大,整体分类精度就越高。
但有时ROC曲线也会失效,它的不足包括:
- 对于偏态分布的数据,可能会高估精度
- 没有提供分类表现的置信区间
- 无法提供不同分类器表现差异的显著性水平
作为一种替代方法,我们也可以选择别的可视化方式比如PR曲线和代价曲线。特别地,代价曲线被认为有以图形方式描述分类器误分类代价的能力。但在90%的场合中,ROC曲线已经足够好。
在R中进行不平衡数据分类
我们已经学习了不平衡分类的一些重要理论技术。是时候来应用它们了!在R中,诸如ROSE包和EMwR包都可以帮助我们快速实现采样过程。我们将以一个二分类案例做演示。
ROSE(Random Over Sampling Examples)包可以帮助我们基于采样和平滑自助法(smoothed bootstrap)来生成人工样本。这个包也提供了一些定义良好的函数来快速完成分类任务。
让我们开始吧

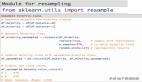
ROSE包中内置了一个叫做hacide的不平衡数据集,它包括hacide.train和hacide.test两个部分,让我们把它读入R环境: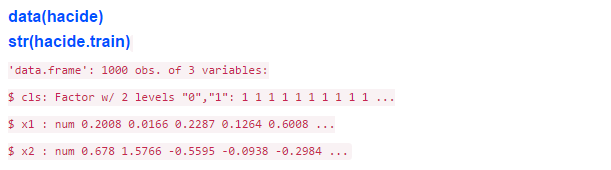
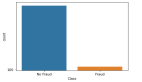
如你所见,数据集有3个变量的1000个观测。cls是响应变量,x1和x2是解释变量。让我们检查下cls的不平衡程度:

可以看到,数据集中只有2%的正样本,其余98%都属于负类。数据的不平衡性极其严重。那么,这对我们的分类精度会带来多大影响?我们先建立一个简单的决策树模型:
然我们看看这个模型的预测精度,ROSE包提供了名为accuracy.meas()的函数,它能用来计算准确率,召回率和F测度等统计量。
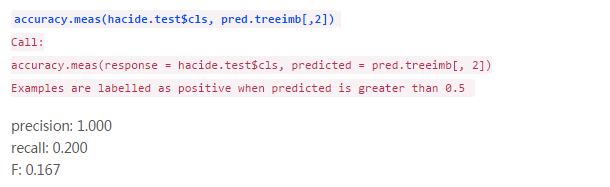
这些测度值看上去很有意思。如果我们设定阈值为0.5,准确率等于1说明没有被误分为正类的样本。召回率等于0.2意味着有很多样本被误分为负类。0.167的F值也说明模型整体精度很低。
我们再来看看模型的ROC曲线,它会给我们提供这个模型分类能力的直观评价。使用roc.curve()函数可以绘制该曲线:

AUC值等于0.6是个很槽糕的结果。因此我们很有必要在建模前将数据集修正平衡。在本案例中,决策树算法对于小类样本无能为力。
我们将使用采样技术来提升预测精度。这个包提供了ovun.sample()的函数来实现过采样和欠采样。
我们先试试过采样
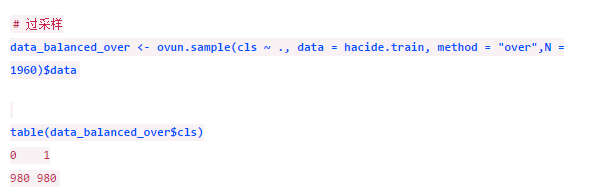
上述代码实现了过采样方法。N代表最终平衡数据集包含的样本点,本例中我们有980个原始负类样本,所以我们要通过过采样法把正类样本也补充到980个,数据集共有1960个观测。
与之类似,我们也能用欠采样方法,请牢记欠采样是无放回的。
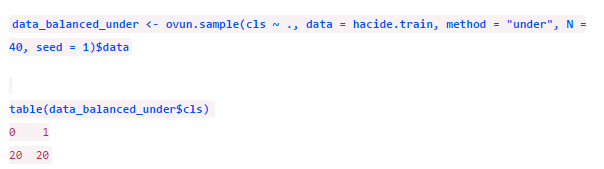
欠采样后数据是平衡了,但由于只剩下了40个样本,我们损失了太多信息。我们还可以同时采取这两类方法,只需要把参数改为method = “both”。这时,对小类样本会进行有放回的过采样而对大类样本则进行无放回的欠采样。
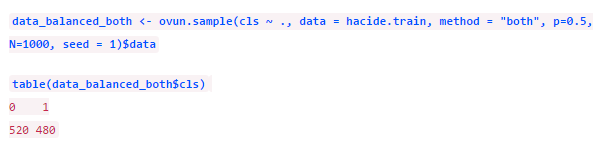
函数的参数p代表新生成数据集中正类的比例。
但前文已经提过两类采样法都有自身的缺陷,欠采样会损失信息,过采样容易导致过拟合,因而ROSE包也提供了ROSE()函数来合成人工数据,它能提供关于原始数据的更好估计。

这里生成的数据量和原始数据集相等(1000个观测)。现在,我们已经用4种方法平衡了数据,我们分别建模评评估精度。

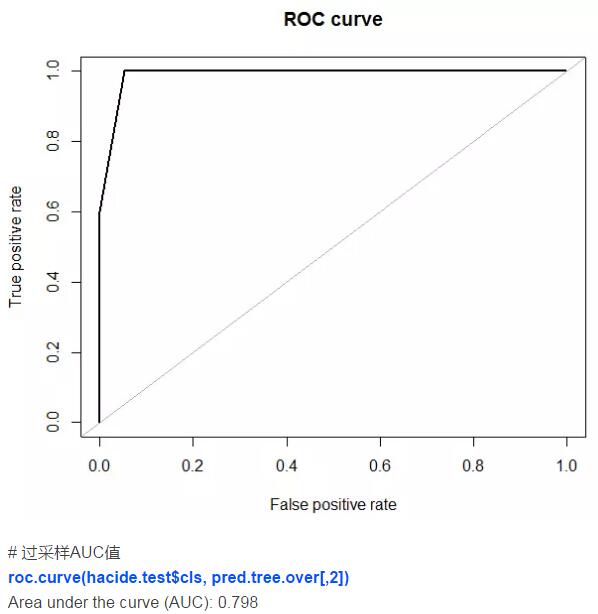
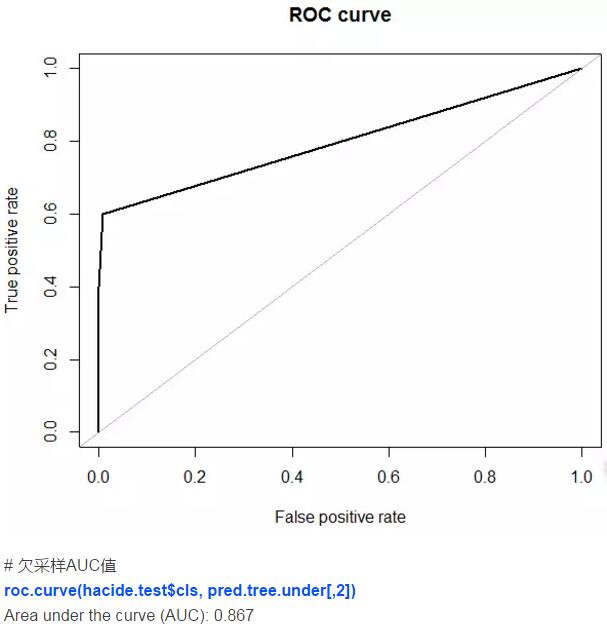
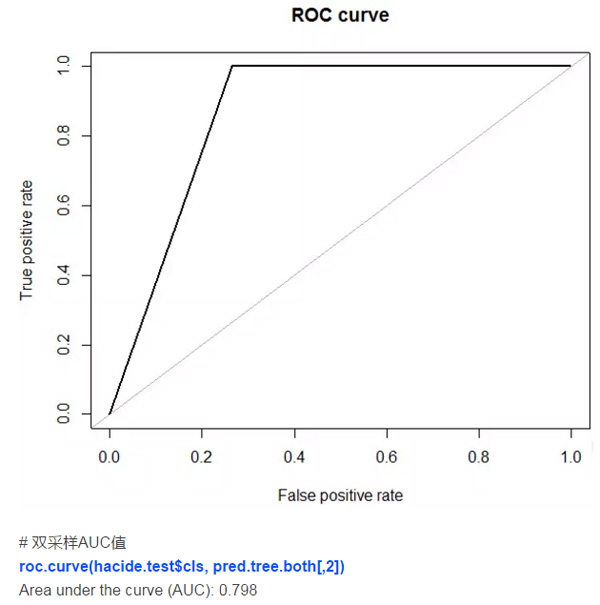
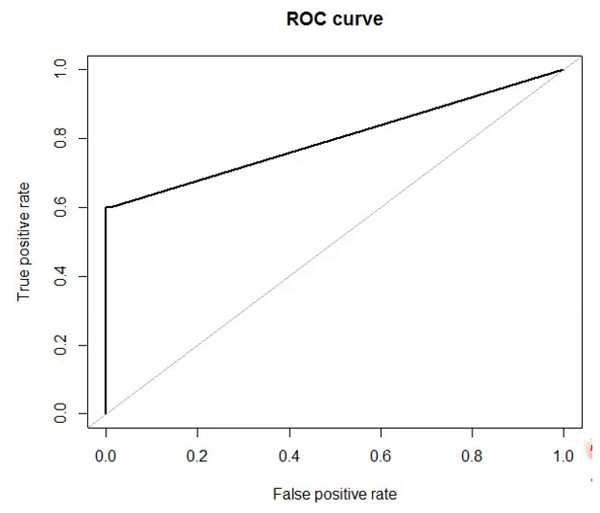
因此,我们发现利用人工数据合成法可以带来最高的预测精度,它的表现比采样法要好。这一技术和更稳健的模型结合(随机森林,提升法)可以得到更高的精度。
这个包为我们提供了一些基于holdout和bagging的模型评估方法,这有助于我们判断预测结果是否有太大的方差。

可以发现预测精度维持在0.98附近,这意味着预测结果波动不大。类似的,你可以用自助法来评估,只要把method.asses改为”BOOT”。extr.pred参数是一个输出预测结果为正类的列的函数。
结语
当我们面对不平衡数据集时,我们常常发现利用采样法修正的效果不错。但在本例中,人工数据合成比传统的采样法更好。为了得到更好的结果,你可以使用一些更前沿的方法,诸如基于boosting 的人工数据合成。