相信你也遇到过这样的情况:怀着犹如探秘般万分期待的心情,点开一篇文章,结果却发现又一次中了“标题党”的诱饵,成功上钩。这种现象,在国际有一个形象的名字 “Clickbait”。
“Clickbait”则被定义为引诱人进入某网站的标题诱饵。Facebook、谷歌自2014年末就开始了对“标题诱饵”的识别,并且在最近宣布减少该类新闻出现在新闻摘要中。因此,准确的识别出作者所写的文章是不是标题诱饵就显得尤为重要。
标题诱饵一般有哪些特征
先让我们来看看一些点击量较高的、典型的标题党:
· 关于新iPhone,10件苹果公司不会告诉你的的事
· 接下来发生的一切将会让你大跌眼镜
· 90年代的演员是什么样子的
· 特朗普说了奥巴马和克林顿什么
· 成为一个好的数据科学家必备的9个技能
· 拥有iphone如何提高你的性生活
从这些标题中我们似乎可以寻找到某些模式。趣味性和模糊性是这些标题的主要特点,看到这些标题,我们就不自觉的想点开看看这些文章到底要说什么。当然,通常情况下,文章的内容会让你很失望。
一些小的网站依靠标题陷阱获得流量,就连一些较为受欢迎的新闻网,如Buzzfeed也被冠以标题陷阱集散地的称号, 正如“今日头条”在App store的遭遇一样,随着谷歌和Facebook对这类文章采取的一系列措施惩罚,这种现象还会持续多久?
识别标题诱饵
不同于其他应用机器学习的文章,这篇文章将不包括机器学习的基础,我们直接进入主体的分析部分。
1 创建数据集
为了识别clickbaits,我们必须先从一些新闻网站抓取一些标题,并创建两个相对的数据集:一个为clickbait标题数据集,包含十万条数据;另一个为non-clickbait标题数据集,包含五千条数据,以此形成一个监督学习问题,即用non-clickbaits数据集对clickbaits进行类别判断。
2 数据集特征分析及模型训练
在创建好数据集之后,我们将对不同的数据集进行特征分析,并用机器学习算法进行识别模型的训练。
词频-逆向文本频率(TF-IDF)
TF-IDF是一种用户信息检索与数据挖掘的常用加权技术,用以评估一个字词在一个文件集或一个语料库中的重要程度。在这个方法中,我分别对字符和单词进行分析,并且运用 n-gram模型的(1,1),(1,2),(1,3)。接着,我们用scikit-learn这一用于机器学习的python模块来实现以上算法。
字符分析器如下:

词语分析器如下:

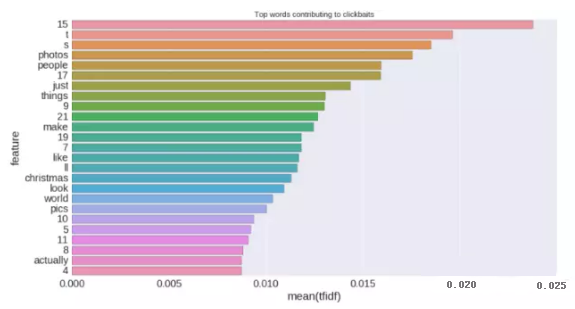
TF-IDF向量分析器非常强大,能清楚的告诉我们哪些字符、单词在clickbaits中的出现的频率***,如下图所示:
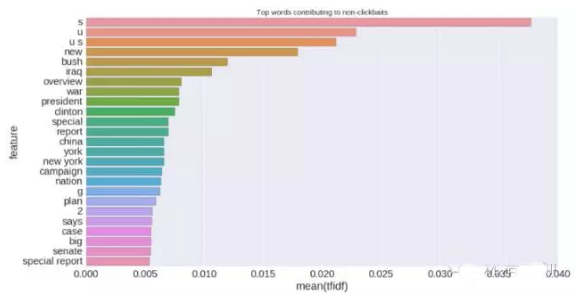
同样,在non-clickbaits中出现频率***的字符、单词为:
接下来,我使用了两种不同的机器学习算法, 逻辑回归和梯度增加,并用以下指标评估模型算法:
· ROC曲线下的面积
· 准确度
· 召回率
· F1-分数
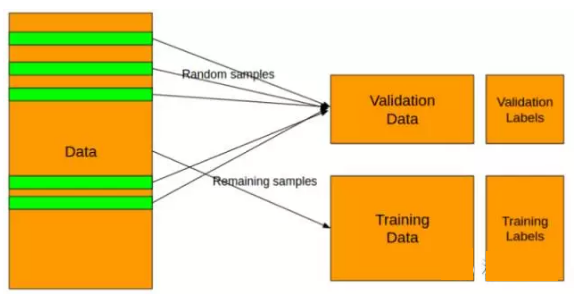
为了避免过度拟合,我使用5折分层抽样。下图展示了如何实现随机抽样。在分层抽样的情况下,预测集合训练集具有相同的正、负标签比例。
经过一些简单的模型参数调整,上述两种机器学习模型的各指标得分如下:
逻辑回归
:ROC曲线下的面积= 0.987319021551
精确度= 0.950326797386
召回率= 0.939276485788F1
得分= 0.944769330734ROC曲线:
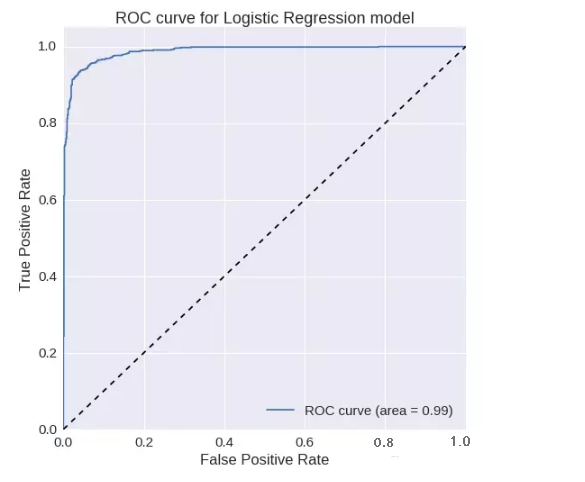
梯度增加:
ROC曲线下的面积= 0.969700677962
精确度= 0.95756718529
召回率= 0.874677002584F1
得分= 0.914247130317ROC
曲线:
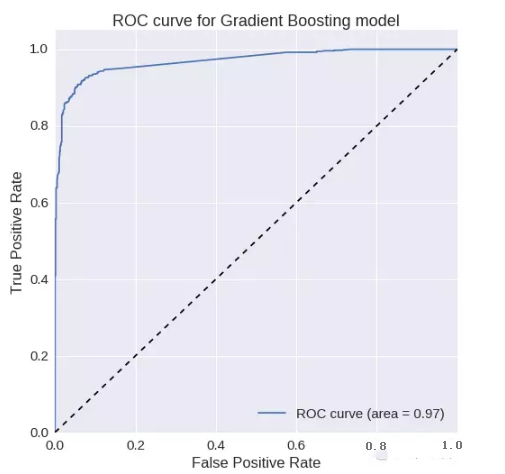
Word2Vec
Word2Vec模型在自然语言处理中很受欢迎,总是为我们提供伟大的见解。Word2Vec从本质上来说就是一个矩阵分解的模型,简单地说,矩阵刻画了每个词和其上下文的词的集合的相关情况。
在本文中,我们用Word2Vec来表示相似或意义非常接近的单词,如下图所示:
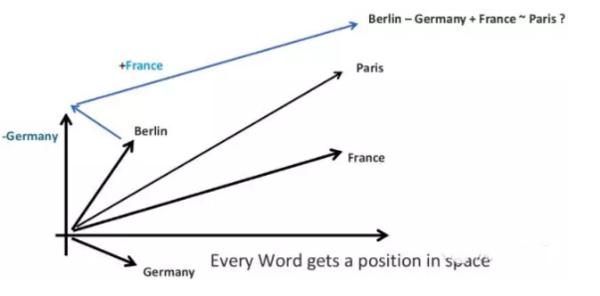
同样,我们也可以使用word2vec代表句子:
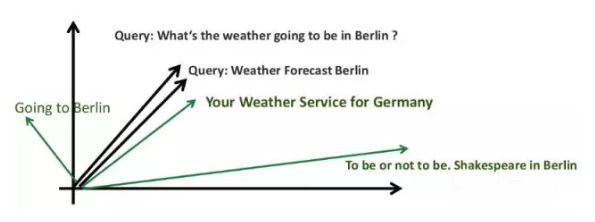
我们将每个单词(每个句子/标题)作为一个200维的向量。可视化word2vec的***办法是将这些向量运用t-SNE方法分解在两维的坐标系中,如下图:
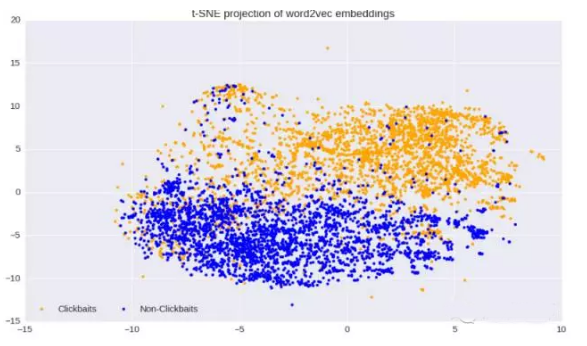
从上图我们看到,我们只用word2vec就明显的区分出了clickbaits和non-clickbaits的特征,这意味着,在这一算法上使用一个机器学习模型将会极大的改善我们的分类。
我们使用与上文相同的两个机器学习模型处理数据集,模型的各指标得分如下:
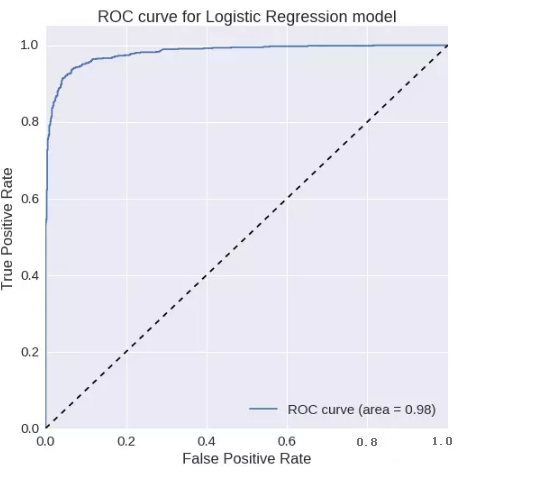
逻辑回归:
ROC曲线下的面积= 0.981149604411
精确度= 0.936280884265
召回率= 0.93023255814F1
得分= 0.933246921581ROC
曲线:
梯度增加:
ROC曲线下的面积= 0.981312768055
精确度= 0.939947780679
召回率= 0.93023255814F1
得分= 0.935064935065ROC
曲线:
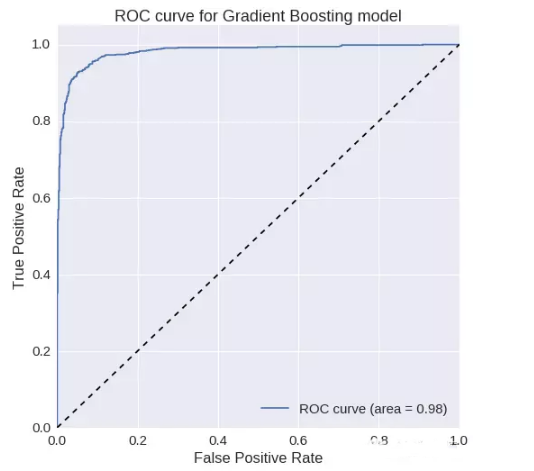
我们可以看到在梯度增加模型中,各项指标得分明显提高。
为了进一步提高评估,我们结合TF-IDF和Word2Vec两种算法进行特征识别,并根据这些特征进行自动识别clickbaits的机器模型训练,可以看到模型分数显著提高。
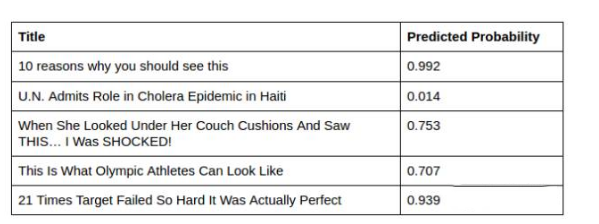
一个严肃的结论停止使用标题陷阱。
对新闻工作者来说,这些标题可能会给你带来额外的阅读量,但随着几大互联网巨头的联合行动,这类现象不会持续很长时间。
文章来源36大数据,www.36dsj.com ,微信号dashuju36 ,36大数据是一个专注大数据创业、大数据技术与分析、大数据商业与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据分析工具和资料下载,解决大数据产业链上的创业、技术、分析、商业、应用等问题,为大数据产业链上的公司和数据行业从业人员提供支持与服务。