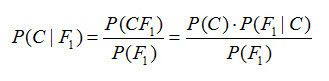
大数据、人工智能、海难搜救、生物医学、邮件过滤,这些看起来彼此不相关的领域之间有什么联系?答案是,它们都会用到同一个数学公式——贝叶斯公式。它虽然看起来很简单、很不起眼,但却有着深刻的内涵。那么贝叶斯公式是如何从默默无闻到现在广泛应用、无所不能的呢?
一、 什么是贝叶斯公式
18世纪英国业余数学家托马斯·贝叶斯(Thomas Bayes,1702~1761)提出过一种看上去似乎显而易见的观点:“用客观的新信息更新我们最初关于某个事物的信念后,我们就会得到一个新的、改进了的信念。” 这个研究成果,因为简单而显得平淡无奇,直到他死后的两年才于1763年由他的朋友理查德·普莱斯帮助发表。它的数学原理很容易理解,简单说就是,如果你看到一个人总是做一些好事,则会推断那个人多半会是一个好人。这就是说,当你不能准确知悉一个事物的本质时,你可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。与其他统计学方法不同,贝叶斯方法建立在主观判断的基础上,你可以先估计一个值,然后根据客观事实不断修正。
1774年,法国数学家皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace,1749-1827)独立地再次发现了贝叶斯公式。拉普拉斯关心的问题是:当存在着大量数据,但数据又可能有各种各样的错误和遗漏的时候,我们如何才能从中找到真实的规律。拉普拉斯研究了男孩和女孩的生育比例。有人观察到,似乎男孩的出生数量比女孩更高。这一假说到底成立不成立呢?拉普拉斯不断地搜集新增的出生记录,并用之推断原有的概率是否准确。每一个新的记录都减少了不确定性的范围。拉普拉斯给出了我们现在所用的贝叶斯公式的表达:
P(A/B)=P(B/A)*P(A)/P(B),
该公式表示在B事件发生的条件下A事件发生的条件概率,等于A事件发生条件下B事件发生的条件概率乘以A事件的概率,再除以B事件发生的概率。公式中,P(A)也叫做先验概率,P(A/B)叫做后验概率。严格地讲,贝叶斯公式至少应被称为“贝叶斯-拉普拉斯公式”。
二、 默默无闻200年
贝叶斯公式现在已经非常流行,甚至在热门美剧《生活大爆炸》中谢耳朵也秀了一下。但它真正得到重视和广泛应用却是最近二三十年的事,其间被埋没了200多年。这是为什么呢?原因在于我们有另外一种数学工具——经典统计学,或者叫频率主义统计学(我们在学校学的主要是这种统计学),它在200多年的时间里一直表现不错。从理论上讲,它可以揭示一切现象产生的原因,既不需要构建模型,也不需要默认条件,只要进行足够多次的测量,隐藏在数据背后的原因就会自动揭开面纱。
在经典统计学看来,科学是关于客观事实的研究,我们只要反复观察一个可重复的现象,直到积累了足够多的数据,就能从中推断出有意义的规律。而贝叶斯方法却要求科学家像算命先生一样,从主观猜测出发,这显然不符合科学精神。就连拉普拉斯后来也放弃了贝叶斯方法这一思路,转向经典统计学。因为他发现,如果数据量足够大,人们完全可以通过直接研究这些样本来推断总体的规律。
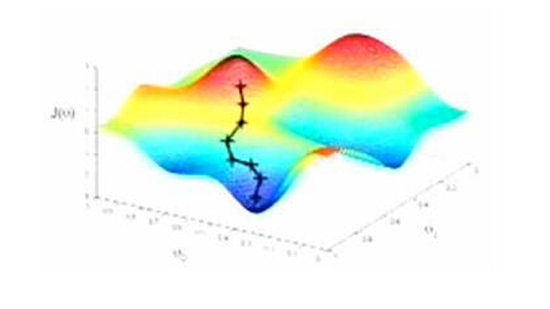
打个比方来帮助我们理解这两种统计学方法的区别。假如我们想知道某个区域里海拔最低的地方,经典统计学的方法是首先进行观测,取得区域内不同地方的海拔数据,然后从中找出最低点。这个数据量必须足够多,以反映区域内地形全貌的特征,这样我们才能相信找到的就是实际上的最低点。而贝叶斯方法是我不管哪里最低,就凭感觉在区域内随便选个地方开始走,每一步都往下走,虽然中间可能有一些曲折,但相信这样走早晚能够到达最低点。可以看出,贝叶斯方法的关键问题是这个最终到达的低点可能不是真正的最低点,而是某个相对低点,它可能对该区域的地形(碗型、马鞍形等)和最初我们主观选择的出发点有依赖性。如果问题域是碗型的,我们到达的就是最低点;但如果是马鞍形或者其他复杂曲面,那么我们到达的可能是多个相对低点(极点)中的一个,而不是真正的最低点。这是贝叶斯方法最受经典统计学方法诟病的原因,也是它在过去的200多年被雪藏的原因所在。
贝叶斯方法原理示意图:
三、 初显威力
长期以来,贝叶斯方法虽然没有得到主流学界的认可,但其实我们经常会不自觉地应用它来进行决策,而且还非常有效。比如炮兵在射击时会使用贝叶斯方法进行瞄准。炮弹与子弹不同,它的飞行轨迹是抛物线,瞄准的难度更大,因此他们会先根据计算和经验把炮管调整到一个可能命中的瞄准角度(先验概率),然后再根据炮弹的实际落点进行调整(后验概率),这样在经过2-3次射击和调整后炮弹就能够命中目标了。
在日常生活中,我们也常使用贝叶斯方法进行决策。比如在一个陌生的地方找餐馆吃饭,因为之前不了解哪家餐馆好,似乎只能随机选择,但实际上并非如此,我们会根据贝叶斯方法,利用以往积累的经验来提供判断的线索。经验告诉我们,通常那些坐满了客人的餐馆的食物要更美味些,而那些客人寥寥的餐馆,食物可能不怎么样而且可能会被宰。这样,我们就往往通过观察餐厅的上座率来选择餐馆就餐。这就是我们根据先验知识进行的主观判断。在吃过以后我们对这个餐馆有了更多实际的了解,以后再选择时就更加容易了。所以说,在我们认识事物不全面的情况下,贝叶斯方法是一种很好的利用经验帮助作出更合理判断的方法。
而两个标志性的事件在让学术界开始重视贝叶斯方法上起到了重要作用。
1.联邦党人文集作者公案
1787年5月,美国各州(当时为13个)代表在费城召开制宪会议;1787年9月,美国的宪法草案被分发到各州进行讨论。一批反对派以“反联邦主义者”为笔名,发表了大量文章对该草案提出批评。宪法起草人之一亚历山大·汉密尔顿着急了,他找到曾任外交国务秘书(即后来的国务卿)的约翰·杰伊,以及纽约市国会议员麦迪逊,一同以普布利乌斯(Publius)的笔名发表文章,向公众解释为什么美国需要一部宪法。他们走笔如飞,通常在一周之内就会发表3-4篇新的评论。1788年,他们所写的85篇文章结集出版,这就是美国历史上著名的《联邦党人文集》。
《联邦党人文集》出版的时候,汉密尔顿坚持匿名发表,于是,这些文章到底出自谁人之手,成了一桩公案。1810年,汉密尔顿接受了一个政敌的决斗挑战,但出于基督徒的宗教信仰,他决意不向对方开枪。在决斗之前数日,汉密尔顿自知时日不多,他列出了一份《联邦党人文集》的作者名单。1818年,麦迪逊又提出了另一份作者名单。这两份名单并不一致。在85篇文章中,有73篇文章的作者身份较为明确,其余12篇存在争议。
1955年,哈佛大学统计学教授Fredrick Mosteller找到芝加哥大学的年轻统计学家David Wallance,建议他跟自己一起做一个小课题,他想用统计学的方法,鉴定出《联邦党人文集》的作者身份。
但这根本就不是一个小课题。汉密尔顿和麦迪逊都是文章高手,他们的文风非常接近。从已经确定作者身份的那部分文本来看,汉密尔顿写了9.4万字,麦迪逊写了11.4万字。汉密尔顿每个句子的平均长度是34.55字,而麦迪逊是34.59字。就写作风格而论,汉密尔顿和麦迪逊简直就是一对双胞胎。汉密尔顿和麦迪逊写这些文章,用了大约一年的时间,而Mosteller和Wallance甄别出作者的身份花了10多年的时间。
如何分辨两人写作风格的细微差别,并据此判断每篇文章的作者就是问题的关键。他们所采用的方法就是以贝叶斯公式为核心的包含两个类别的分类算法。先挑选一些能够反映作者写作风格的词汇,在已经确定了作者的文本中,对这些特征词汇的出现频率进行统计,然后再统计这些词汇在那些不确定作者的文本中的出现频率,从而根据词频的差别推断其作者归属。这其实和我们现在使用的垃圾邮件过滤器的原理是一样的。
他们是在没有计算机帮助的条件下用手工处理“大数据”,这一工程的耗时耗力是可想而知的。将近100个哈佛大学的学生帮助他们处理数据。学生们用最原始的方式,用打字机把《联邦党人文集》的文本打出来,然后把每个单词剪下来,按照字母表的顺序,把这些单词分门别类地汇集在一起。有个学生干得累了,伸了个懒腰,长长地呼了一口气。他这一口气用力太猛,一下子把刚刚归置好的单词条吹得如柳絮纷飞,一屋子学生瞬间石化,估计很多人连灭了他的心都有。而这只是手工大数据时代的日常。
Mosteller和Wallance这是要在干草垛里找绣花针。他们首先剔除掉用不上的词汇。比如,《联邦党人文集》里经常谈到“战争”、“立法权”、“行政权”等,这些词汇是因主题而出现,并不反映不同作者的写作风格。只有像“in”,“an”,“of”,“upon”这些介词、连词等才能显示出作者风格的微妙差异。一位历史学家好心地告诉他们,有一篇1916年的论文提到,汉密尔顿总是用“while”,而麦迪逊则总是用“whilst”。但仅仅有这一个线索是不够的。“while”和“whilst”在这12篇作者身份待定的文章里出现的次数不够多。况且,汉密尔顿和麦迪逊有时候会合写一篇文章,也保不齐他们会互相改文章,要是汉密尔顿把麦迪逊的“whilst”都改成了“while”呢?
当学生们把每个单词的小纸条归类、粘好之后,他们发现,汉密尔顿的文章里平均每一页纸会出现两次“upon”,而麦迪逊几乎一次也不用。汉密尔顿更喜欢用“enough”,麦迪逊则很少用。其它一些有用的词汇包括:“there”、“on”等等。1964年,Mosteller和Wallance发表了他们的研究成果。他们的结论是,这12篇文章的作者很可能都是麦迪逊。他们最拿不准的是第55篇,麦迪逊是作者的概率是240:1。
这个研究引起了极大的轰动,但最受震撼的不是宪法研究者,而是统计学家。Mosteller和Wallance的研究,把贝叶斯公式这个被统计学界禁锢了200年的幽灵从瓶子中释放了出来。
2.天蝎号核潜艇搜救
2014年初马航MH370航班失联,所有人都密切关注搜救的进展情况。那么我们是用什么方法在茫茫大海中寻找失联的飞机或者船只的呢?这要从天蝎号核潜艇说起。
1968年5月,美国海军的天蝎号核潜艇在大西洋亚速海海域突然失踪,潜艇和艇上的99名海军官兵全部杳无音信。按照事后调查报告的说法,罪魁祸首是这艘潜艇上的一枚奇怪的鱼雷,发射出去后竟然敌我不分,扭头射向自己,让潜艇中弹爆炸。
为了寻找天蝎号的位置,美国政府从国内调集了包括多位专家的搜索部队前往现场,其中包括一位名叫John Craven的数学家,他的头衔是“美国海军特别计划部首席科学家”。在搜寻潜艇的问题上,Craven提出的方案使用了上面提到的贝叶斯公式。他召集了数学家、潜艇专家、海事搜救等各个领域的专家。每个专家都有自己擅长的领域,但并非通才,没有专家能准确估计到在出事前后潜艇到底发生了什么。有趣的是,Craven并不是按照惯常的思路要求团队成员互相协商寻求一个共识,而是让各位专家编写了各种可能的“剧本”,让他们按照自己的知识和经验对于情况会向哪一个方向发展进行猜测,并评估每种情境出现的可能性。据说,为了给枯燥的工作增加一些趣味,Craven还准备了威士忌酒作为“投注”正确的奖品。
因为在Craven的方案中,结果很多是这些专家以猜测、投票甚至可以说赌博的形式得到的,不可能保证所有结果的准确性,他的这一做法受到了很多同行的质疑。可是因为搜索潜艇的任务紧迫,没有时间进行精确的实验、建立完整可靠的理论,Craven的办法不失为一个可行的办法。
由于失事时潜艇航行的速度快慢、行驶方向、爆炸冲击力的大小、爆炸时潜艇方向舵的指向都是未知量,即使知道潜艇在哪里爆炸,也很难确定潜艇残骸最后被海水冲到哪里。Craven粗略估计了一下,半径20英里的圆圈内的数千英尺深的海底,都是天蝎号核潜艇可能沉睡的地方,要在这么大的范围,这么深的海底找到潜艇几乎成了不可能完成的任务。
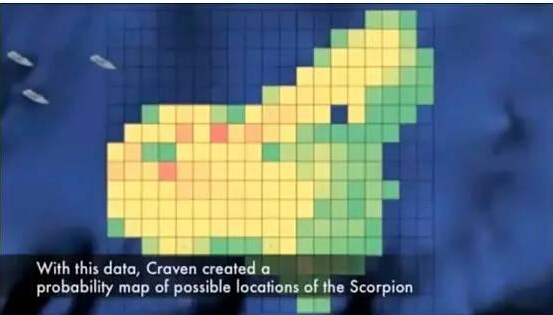
Craven把各位专家的意见综合到一起,得到了一张20英里海域的概率图。整个海域被划分成了很多个小格子,每个小格子有两个概率值p和q,p是潜艇躺在这个格子里的概率,q是如果潜艇在这个格子里,它被搜索到的概率。按照经验,第二个概率值主要跟海域的水深有关,在深海区域搜索失事潜艇的“漏网”可能性会更大。如果一个格子被搜索后,没有发现潜艇的踪迹,那么按照贝叶斯公式,这个格子潜艇存在的概率就会降低:
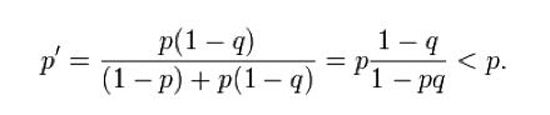
由于所有格子概率的总和是1,这时其他格子潜艇存在的概率值就会上升:
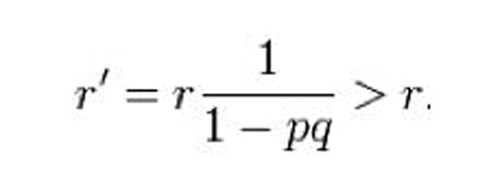
每次寻找时,先挑选整个区域内潜艇存在概率值最高的一个格子进行搜索,如果没有发现,概率分布图会被“洗牌”一次,搜寻船只就会驶向新的“最可疑格子”进行搜索,这样一直下去,直到找到天蝎号为止。
最初开始搜救时,海军人员对Craven和其团队的建议嗤之以鼻,他们凭经验估计潜艇是在爆炸点的东侧海底。但几个月的搜索一无所获,他们才不得不听从了Craven的建议,按照概率图在爆炸点的西侧寻找。经过几次搜索,潜艇果然在爆炸点西南方的海底被找到了。
由于这种基于贝叶斯公式的方法在后来多次搜救实践中被成功应用,现在已经成为海难空难搜救的通行做法。
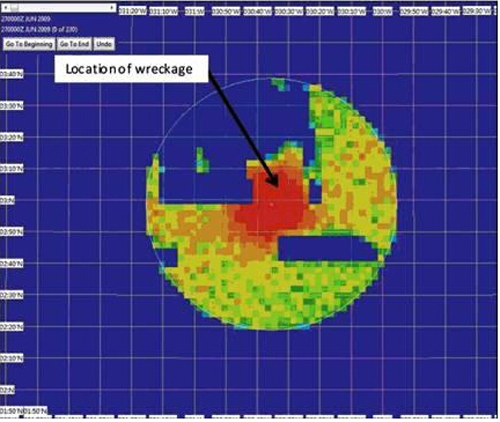
2009年法航空难搜救的后验概率分布图:
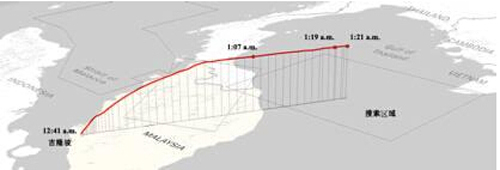
2014马航MH370失联搜索区域:
与计算机的结合使贝叶斯公式巨大的实用价值进一步体现出来,它不但为我们提供了一条全新的问题解决路径,带来工具和理念的革命,而且甚至可能是人类大脑本身的认知和构建方式。
好了,关于贝叶斯公式的内容今天就讲到这里,接下来我们将会讲讲正在发生的“贝叶斯革命”。