我们平时在浏览电商、视频等网站时,网页一般会有一个“猜你喜欢”,也就是”智能推荐系统“,虽然一般来说推荐的不是很准确,但是程Sir还是研究了一下这个玩意是怎么弄出来的……今天说一说最简单的一个实现方法,叫做基于用户的协同过滤。
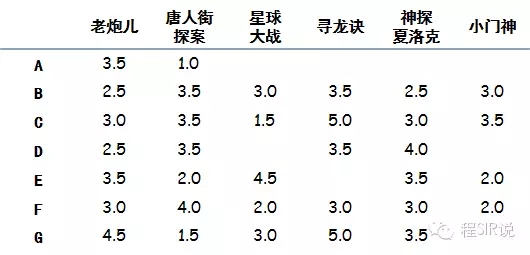
假设有几个人分别看了如下电影并且给电影有如下评分(5分***,没看过的不评分),我们目的是要向A用户推荐一部电影:
协同过滤的整体思路只有两步,非常简单:寻找相似用户,推荐电影
寻找相似用户
所谓相似,其实是对于电影品味的相似,也就是说需要将A与其他几位用户做比较,判断是不是品味相似。有很多种方法可以用来判断相似性,(与我之前写的K-Means文章中判断两点是否类似的方法是一致的)这篇文章用“欧几里德距离”来做相似性判定。
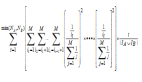
我们把每一部电影看成N维空间中的一个维度,这样每个用户对于电影的评分相当于维度的坐标,那么每一个用户的所有评分,相当于就把用户固定在这个N维空间的一个点上,然后利用欧几里德距离计算N维空间两点的距离:每一个电影的评分求差值,然后求每个差值的平方,然后求平方的和,然后在开平方。距离越短说明品味越接近。本例中A只看过两部电影(《老炮儿》和《唐人街探案》),因此只能通过这两部电影来判断品味了,那么计算A和其他几位的距离:
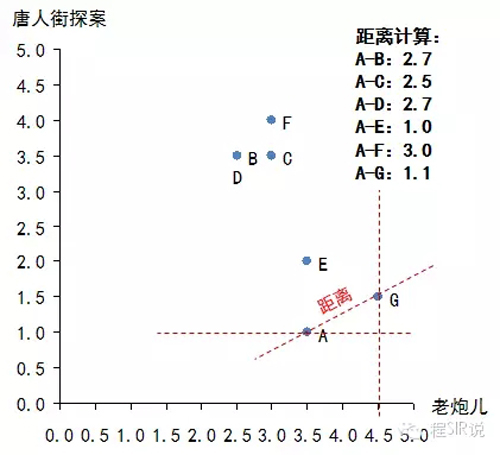
然后我们做一个变换,变换方法为:相似性 = 1/(1+欧几里德距离),这个相似性会落在【0,1】区间内,1表示完全品味一样,0表示完全品味不一样。这时我们就可以找到哪些人的品味和A最为接近了,计算后如下:
相似性:B-0.27,C-0.28,D-0.27,E-0.50,F-0.25,G-0.47
可见,E的口味与A最为接近,其次是G
推荐电影
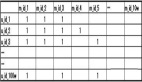
要做电影加权评分推荐。意思是说,品味相近的人对于电影的评价对A选择电影来说更加重要,具体做法可以列一个表,计算加权分:
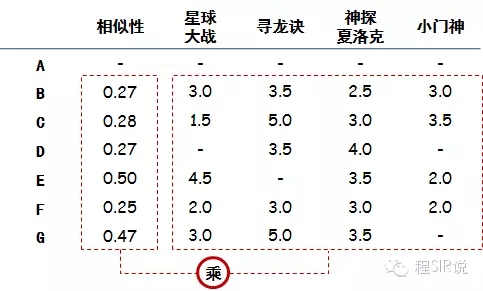
把相似性和对于每个电影的实际评分相乘,就是电影的加权分
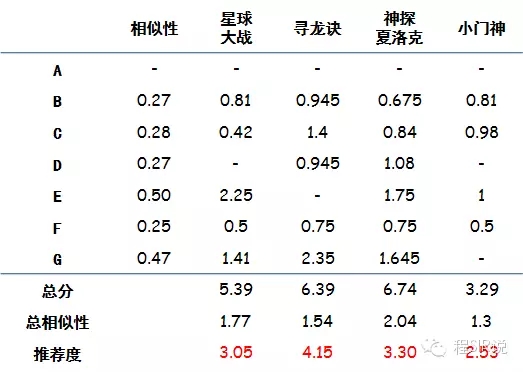
加权后,还要做少量的计算:总分是每个电影加权分的总和,总相似度是对这个电影有评分的人的相似性综合,推荐度是总分/总相似性,目的是排除看电影人数对于总分的影响
结论在最终一行,就是电影的推荐度(因为是根据品味相同的人打分加权算出的分,可以近似认为如果A看了这部电影,预期的评分会是多少)。
有了电影的加权得分,通常做法还要设定一个阈值,如果超过了阈值再给用户推荐,要不怎么推荐都是烂片,如果这里我们设置阈值为4,那么最终推荐给A的电影就是《寻龙诀》。
我们现在的做法是向用户推荐电影。当然还可以从另外角度来思考:如果我们把一开始的评分表的行列调换,其他过程都不变,那么就变成了把电影推荐给合适的受众。因此,要根据不同场景选择不同的思考维度。