阅读目录
1. 写在前面的话
1.1. 关于netty example
1.2. 关于github项目
2. HTTP 协议知多少
2.1. GET请求
2.2. POST请求
2.3. HTTP POST Content-Type
3. netty HTTP 编解码
3.1. netty 自带 HTTP 编解码器
3.2. HTTP GET 解析实践
3.3. HTTP POST 解析实践
4. 自定义 HTTP POST 的 message body 解码器
4.1. HttpJsonDecoder
4.2. HttpProtobufDecoder
5. 聊聊开发中遇到的问题【推荐】
5.1. 关于内存泄漏
5.1.1. netty 应用计数对象
5.1.2. 如何规避内存泄漏
5.2. 关于 HTTP 长连接
5.2.1. TCP KeepAlive 和 HTTP KeepAlive
5.2.2. 长连接方式中如何判断数据发送完成
1. 说在前面的话
前段时间,工作上需要做一个针对视频质量的统计分析系统,各端(PC端、移动端和 WEB端)将视频质量数据放在一个 HTTP 请求中上报到服务器,服务器对数据进行解析、分拣后从不同的维度做实时和离线分析。(ps:这种活儿本该由统计部门去做的,但由于各种原因落在了我头上,具体原因略过不讲……)
先用个“概念图”来描绘下整个系统的架构:
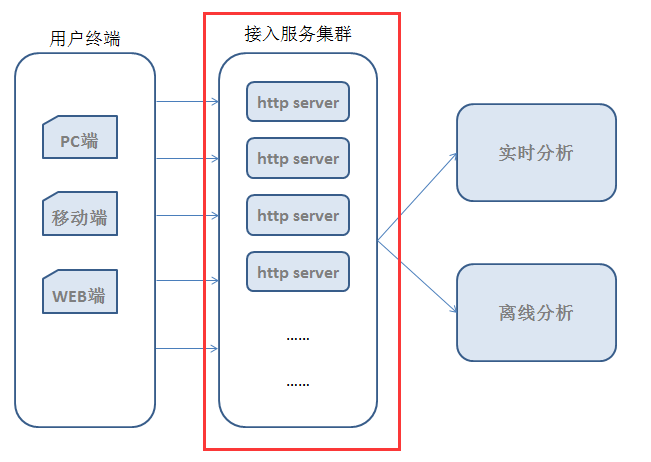
嗯,这个是真正的“概念图”,因为我已经把大部分细节都屏蔽了,别笑,因为本文的重点只是整个架构中的一小部分,就是上图中红框内的 http server。
也许你会问,这不就是个 HTTP 服务器吗,而且是只处理一个请求的 HTTP 服务器,搞个java web 项目在 Tomcat 中一启动不就完事儿了,有啥好讲的呀?。莫慌,且听老夫慢慢道来为啥要用 netty HTTP 协议栈来实现这个接收转发服务。
- 首先,接入服务需要支持10W+ tps,而 netty 的多线程模型和异步非阻塞的特性让人很自然就会将它和高并发联系起来。
- 其次,接入服务虽然使用 HTTP 协议,但显然这并不是个 WEB 应用,无需运行在相对较重的 Tomcat 这种 WEB 容器上。
- 接着,在提供同等服务的情况下对比 netty HTTP 协议栈和 Tomcat HTTP 服务,发现使用 netty 时在机器资源占用(如CPU使用率、内存占用及上下文切换等)方面要优于 Tomcat。
- 最后,netty 一直在说对 HTTP 协议提供了非常好的支持,因此想乘机检验一下是否属实。
基于以上几点原因,老夫就决定使用 netty HTTP 协议栈开干啦~
本文并非纯理论或纯技术类文章,而是结合理论进而实践(虽然没有特别深入的实践),浅析 netty 的 HTTP 协议栈,并着重聊聊实践中遇到的问题及解决方案。越往后越精彩哦!
1.1. 关于netty example
netty 官方提供了关于 HTTP 的例子,大伙儿可以在 netty 项目中查看。
https://github.com/netty/netty/tree/4.1/example/src/main/java/io/netty/example/http
https://github.com/netty/netty/tree/4.1/example/src/main/java/io/netty/example/http2
1.2. 关于github项目
本人在网上使用 “netty + HTTP” 的关键字搜索了下,发现大部分都是原搬照抄 netty 项目中的 example,很少有“原创性”的实践,也几乎没有看到实现一个相对完整的 HTTP 服务器的项目(比如如何解析GET/POST请求、自定义 HTTP decoder、对 HTTP 长短连接的思考等等……),因此就自己整理了一个相对完整一点的项目,项目地址https://github.com/cyfonly/netty-http,该项目实现了基于 netty5 的 HTTP 服务端,暂时实现以下功能:
- HTTP GET 请求解析与响应
- HTTP POST 请求解析与响应,提供 application/json、application/x-www-form-urlencoded、multipart/form-data 三种常见 Content-Type 的 message body 解析示例
- HTTP decoder实现,提供 POST 请求 message body 解码器的 HttpJsonDecoder 及 HttpProtobufDecoder 实现示例
- 作为服务端接收浏览器文件上传及保存
将来可能会继续实现的功能有:
- 命名空间
- uri路由
- chunked 传输编码
如果你也打算使用 netty 来实现 HTTP 服务器,相信这个项目和本文对你是有较大帮助的!
好了,闲话不多说,下面正式进入正题。
2. HTTP 协议知多少
要通过 netty 实现 HTTP 服务端(或者客户端),首先你得了解 HTTP 协议【1】。
HTTP 协议是请求/响应式的协议,客户端需要发送一个请求,服务器才会返回响应内容。例如在浏览器上输入一个网址按下 Enter,或者提交一个 Form 表单,浏览器就会发送一个请求到服务器,而打开的网页的内容,就是服务器返回的响应。
下面讲下 HTTP 请求和响应包含的内容。
HTTP 请求有很多种 method,最常用的就是 GET 和 POST,每种 method 的请求之间会有细微的区别。下面分别分析一下 GET 和 POST 请求。
2.1. GET请求
下面是浏览器对 http://localhost:8081/test?name=XXG&age=23 的 GET 请求时发送给服务器的数据:

可以看出请求包含 request line 和 header 两部分。其中 request line 中包含 method(例如 GET、POST)、request uri 和 protocol version 三部分,三个部分之间以空格分开。request line 和每个 header 各占一行,以换行符 CRLF(即 \r\n)分割。
2.2. POST请求
下面是浏览器对 http://localhost:8081/test 的 POST 请求时发送给服务器的数据,同样带上参数 name=XXG&age=23:

可以看出,上面的请求包含三个部分:request line、header、message,比之前的 GET 请求多了一个 message body,其中 header 和 message body 之间用一个空行分割。POST 请求的参数不在 URL 中,而是在 message body 中,header 中多了一项 Content-Length 用于表示 message body 的字节数,这样服务器才能知道请求是否发送结束。这也就是 GET 请求和 POST 请求的主要区别。
HTTP 响应和 HTTP 请求非常相似,HTTP 响应包含三个部分:status line、header、massage body。其中 status line 包含 protocol version、状态码(status code)、reason phrase 三部分。状态码用于描述 HTTP 响应的状态,例如 200 表示成功,404 表示资源未找到,500 表示服务器出错。
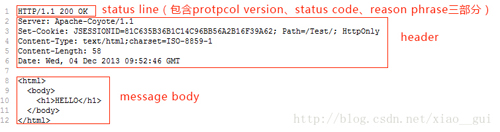
在上面的 HTTP 响应中,Header 中的 Content-Length 同样用于表示 message body 的字节数。Content-Type 表示 message body 的类型,通常浏览网页其类型是HTML,当然还会有其他类型,比如图片、视频等。
2.3. HTTP POST Content-Type
HTTP/1.1 协议规定的 HTTP 请求方法有 OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE、CONNECT 这几种。其中 POST 一般用来向服务端提交数据,本文讨论主要的几种 POST 提交数据方式。
我们知道,HTTP 协议是以 ASCII 码传输,建立在 TCP/IP 协议之上的应用层规范。规范把 HTTP 请求分为三个部分:状态行、请求头、消息主体。类似于下面这样:
- <method> <request-URL> <version>
- <headers>
- <entity-body>
协议规定 POST 提交的数据必须放在消息主体(entity-body)中,但协议并没有规定数据必须使用什么编码方式。实际上,开发者完全可以自己决定消息主体的格式,只要最后发送的 HTTP 请求满足上面的格式就可以。
但是,数据发送出去,还要服务端解析成功才有意义。一般服务端语言如 php、python 等,以及它们的 framework,都内置了自动解析常见数据格式的功能。服务端通常是根据请求头(headers)中的 Content-Type 字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析。所以说到 POST 提交数据方案,包含了 Content-Type 和消息主体编码方式 Charset 两部分。下面就正式开始介绍它们。
2.3.1. application/x-www-form-urlencoded
这应该是最常见的 POST 提交数据的方式了。浏览器的原生 Form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。请求类似于下面这样(无关的请求头在本文中都省略掉了):
- POST http://www.example.com HTTP/1.1
- Content-Type: application/x-www-form-urlencoded;charset=utf-8
- title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
首先,Content-Type 被指定为 application/x-www-form-urlencoded;其次,提交的数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。大部分服务端语言都对这种方式有很好的支持。
很多时候,我们用 Ajax 提交数据时,也是使用这种方式。例如 JQuery 的 Ajax,Content-Type 默认值都是 application/x-www-form-urlencoded;charset=utf-8 。
2.3.2. multipart/form-data
这又是一个常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 Form 的 enctyped 等于这个值。直接来看一个请求示例:
- POST http://www.example.com HTTP/1.1
- Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA
- ------WebKitFormBoundaryrGKCBY7qhFd3TrwA
- Content-Disposition: form-data; name="text"
- title
- ------WebKitFormBoundaryrGKCBY7qhFd3TrwA
- Content-Disposition: form-data; name="file"; filename="chrome.png"
- Content-Type: image/png
- PNG ... content of chrome.png ...
- ------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 mutipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 –boundary 开始,紧接着内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以 –boundary– 标示结束。
这种方式一般用来上传文件,各大服务端语言对它也有着良好的支持。
上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段原生 Form 表单也只支持这两种方式。但是随着越来越多的 Web 站点,尤其是 WebApp,全部使用 Ajax 进行数据交互之后,我们完全可以定义新的数据提交方式,给开发带来更多便利。
2.3.3. application/json
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
JSON 格式支持比键值对复杂得多的结构化数据,这一点也很有用,当需要提交的数据层次非常深,就可以考虑把数据 JSON 序列化之后来提交的。
- var data = {'title':'test', 'sub' : [1,2,3]};
- $http.post(url, data).success(function(result) {
- ...
- });
最终发送的请求是:
- POST http://www.example.com HTTP/1.1
- Content-Type: application/json;charset=utf-8
- {"title":"test","sub":[1,2,3]}
这种方案,可以方便的提交复杂的结构化数据,特别适合 RESTful 的接口。各大抓包工具如 Chrome 自带的开发者工具、Fiddler,都会以树形结构展示 JSON 数据,非常友好。
其他几种 Content-Type 就不一一详细介绍了,感兴趣的童鞋请自行了解。下面进入 netty 支持 HTTP 协议的源码分析阶段。
3. netty HTTP 编解码
要通过 netty 处理 HTTP 请求,需要先进行编解码。
3.1. netty 自带 HTTP 编解码器
netty5 提供了对 HTTP 协议的几种编解码器:
3.1.1. HttpRequestDecoder
- Decodes ByteBuf into HttpRequest and HttpContent.
即把 ByteBuf 解码到 HttpRequest 和 HttpContent。
3.1.2. HttpResponseEncoder
- Encodes an HttpResponse or an HttpContent into a ByteBuf.
即把 HttpResponse 或 HttpContent 编码到 ByteBuf。
3.1.3. HttpServerCodec
- A combination of HttpRequestDecoder and HttpResponseEncoder which enables easier server side HTTP implementation.
即 HttpRequestDecoder 和 HttpResponseEncoder 的结合。
因此,基于 netty 实现 HTTP 服务端时,需要在 ChannelPipeline 中加上以上编解码器:
- ch.pipeline().addLast("codec",new HttpServerCodec())
或者
- ch.pipeline().addLast("decoder",new HttpRequestDecoder())
- .addLast("encoder",new HttpResponseEncoder())
然而,以上编解码器只能够支持部分 HTTP 请求解析,比如 HTTP GET请求所传递的参数是包含在 uri 中的,因此通过 HttpRequest 既能解析出请求参数。但是,对于 HTTP POST 请求,参数信息是放在 message body 中的(对应于 netty 来说就是 HttpMessage),所以以上编解码器并不能完全解析 HTTP POST请求。
这种情况该怎么办呢?别慌,netty 提供了一个 handler 来处理。
3.1.4. HttpObjectAggregator
- A ChannelHandler that aggregates an HttpMessage and its following HttpContent into a single FullHttpRequest or FullHttpResponse
- (depending on if it used to handle requests or responses) with no following HttpContent.
- It is useful when you don't want to take care of HTTP messages whose transfer encoding is 'chunked'.
即通过它可以把 HttpMessage 和 HttpContent 聚合成一个 FullHttpRequest 或者 FullHttpResponse (取决于是处理请求还是响应),而且它还可以帮助你在解码时忽略是否为“块”传输方式。
因此,在解析 HTTP POST 请求时,请务必在 ChannelPipeline 中加上 HttpObjectAggregator。(具体细节请自行查阅代码)
当然,netty 还提供了其他 HTTP 编解码器,有些涉及到高级应用(较复杂的应用),在此就不一一解释了,以上只是介绍netty HTTP 协议栈最基本的编解码器(切合文章主题——浅析)。
3.2. HTTP GET 解析实践
上面提到过,HTTP GET 请求的参数是包含在 uri 中的,可通过以下方式解析出 uri:
- HttpRequest request = (HttpRequest) msg;
- String uri = request.uri();
特别注意的是,用浏览器发起 HTTP 请求时,常常会被 uri = "/favicon.ico" 所干扰,因此最好对其特殊处理:
- if(uri.equals(FAVICON_ICO)){
- return;
- }
接下来就是解析 uri 了。这里需要用到 QueryStringDecoder:
- Splits an HTTP query string into a path string and key-value parameter pairs.
- This decoder is for one time use only. Create a new instance for each URI:
- QueryStringDecoder decoder = new QueryStringDecoder("/hello?recipient=world&x=1;y=2");
- assert decoder.getPath().equals("/hello");
- assert decoder.getParameters().get("recipient").get(0).equals("world");
- assert decoder.getParameters().get("x").get(0).equals("1");
- assert decoder.getParameters().get("y").get(0).equals("2");
- This decoder can also decode the content of an HTTP POST request whose
- content type is application/x-www-form-urlencoded:
- QueryStringDecoder decoder = new QueryStringDecoder("recipient=world&x=1;y=2", false);
- ...
从上面的描述可以看出,QueryStringDecoder 的作用就是把 HTTP uri 分割成 path 和 key-value 参数对,也可以用来解码 Content-Type = "application/x-www-form-urlencoded" 的 HTTP POST。特别注意的是,该 decoder 仅能使用一次。
解析代码如下:
- String uri = request.uri();
- HttpMethod method = request.method();
- if(method.equals(HttpMethod.GET)){
- QueryStringDecoder queryDecoder = new QueryStringDecoder(uri, Charsets.toCharset(CharEncoding.UTF_8));
- Map<String, List<String>> uriAttributes = queryDecoder.parameters();
- //此处仅打印请求参数(你可以根据业务需求自定义处理)
- for (Map.Entry<String, List<String>> attr : uriAttributes.entrySet()) {
- for (String attrVal : attr.getValue()) {
- System.out.println(attr.getKey() + "=" + attrVal);
- }
- }
- }
3.3. HTTP POST 解析实践
如3.1.4小结所说的那样,解析 HTTP POST 请求的 message body,一定要使用 HttpObjectAggregator。但是,是否一定要把 msg 转换成 FullHttpRequest 呢?答案是否定的,且往下看。
首先解释下 FullHttpRequest 是什么:
- Combinate the HttpRequest and FullHttpMessage, so the request is a complete HTTP request.
即 FullHttpRequest 包含了 HttpRequest 和 FullHttpMessage,是一个 HTTP 请求的完全体。
而把 msg 转换成 FullHttpRequest 的方法很简单:
- FullHttpRequest fullRequest = (FullHttpRequest) msg;
接下来就是分几种 Content-Type 进行解析了。
3.3.1. 解析 application/json
处理 JSON 格式是非常方便的,我们只需要将 msg 转换成 FullHttpRequest,然后将其 content 反序列化成 JSONObject 对象即可,如下:
- FullHttpRequest fullRequest = (FullHttpRequest) msg;
- String jsonStr = fullRequest.content().toString(Charsets.toCharset(CharEncoding.UTF_8));
- JSONObject obj = JSON.parseObject(jsonStr);
- for(Entry<String, Object> item : obj.entrySet()){
- System.out.println(item.getKey()+"="+item.getValue().toString());
- }
3.3.2. 解析 application/x-www-form-urlencoded
解析此类型有两种方法,一种是使用 QueryStringDecoder,另外一种就是使用 HttpPostRequestDecoder。
方法一:3.2节中讲 QueryStringDecoder 时提到:QueryStringDecoder 可以用来解码 Content-Type = "application/x-www-form-urlencoded" 的 HTTP POST。因此我们可以用它来解析 message body,剩下的处理就跟 HTTP GET没什么两样了:
- FullHttpRequest fullRequest = (FullHttpRequest) msg;
- String jsonStr = fullRequest.content().toString(Charsets.toCharset(CharEncoding.UTF_8));
- QueryStringDecoder queryDecoder = new QueryStringDecoder(jsonStr, false);
- Map<String, List<String>> uriAttributes = queryDecoder.parameters();
- for (Map.Entry<String, List<String>> attr : uriAttributes.entrySet()) {
- for (String attrVal : attr.getValue()) {
- System.out.println(attr.getKey()+"="+attrVal);
- }
- }
方法二:使用 HttpPostRequestDecoder 解析时,无需先将 msg 转换成 FullHttpRequest。
我们先来了解下 HttpPostRequestDecoder :
- public HttpPostRequestDecoder(HttpDataFactory factory, HttpRequest request, Charset charset) {
- if (factory == null) {
- throw new NullPointerException("factory");
- }
- if (request == null) {
- throw new NullPointerException("request");
- }
- if (charset == null) {
- throw new NullPointerException("charset");
- }
- // Fill default values
- if (isMultipart(request)) {
- decoder = new HttpPostMultipartRequestDecoder(factory, request, charset);
- } else {
- decoder = new HttpPostStandardRequestDecoder(factory, request, charset);
- }
- }
由它的定义可知,它的内部实现其实有两种方式,一种是针对 multipart 类型的解析,一种是普通类型的解析。这两种方式的具体实现中,我把它们相同的代码提取出来,如下:
- if (request instanceof HttpContent) {
- // Offer automatically if the given request is als type of HttpContent
- offer((HttpContent) request);
- } else {
- undecodedChunk = buffer();
- parseBody();
- }
由于我们使用过 HttpObjectAggregator, request 都是 HttpContent 类型,因此会 Offer automatically,我们就不必自己手动去 offer 了,也不用处理 Chunk,所以使用 HttpObjectAggregator 确实是带来了很多简便的。
好了,接下来就是使用 HttpPostRequestDecoder 来解析了,直接上代码:
- HttpRequest request = (HttpRequest) msg;
- HttpPostRequestDecoder decoder = new HttpPostRequestDecoder(factory, request, Charsets.toCharset(CharEncoding.UTF_8));
- List<InterfaceHttpData> datas = decoder.getBodyHttpDatas();
- for (InterfaceHttpData data : datas) {
- if(data.getHttpDataType() == HttpDataType.Attribute) {
- Attribute attribute = (Attribute) data;
- System.out.println(attribute.getName() + "=" + attribute.getValue());
- }
- }
是不是很简单?没错。但是这里有点我要说明下, InterfaceHttpData 是一个interface,没有 API 可以直接拿到它的 value。那怎么办呢?莫方,在它的类内部定义了个枚举类型,如下:
- enum HttpDataType {
- Attribute, FileUpload, InternalAttribute
- }
这种情况下它是 Attribute 类型,因此你转换一下就能拿到值了。好奇的你可能会问,除 Attribute 外,其他两个是什么时候用呢?没错,接下来马上就讲 FileUpload,至于 InternalAttribute 嘛,老夫就不多说啦,有兴趣可以自己去研究了哈~
3.3.3. 解析 multipart/form-data (文件上传)
上面说到了 FileUpload,那在这里就来说说如何使用 netty HTTP 协议栈实现文件上传和保存功能。
这里依然使用 HttpPostRequestDecoder,废话就不多少了,直接上代码:
- DiskFileUpload.baseDirectory = "/data/fileupload/";
- HttpRequest request = (HttpRequest) msg;
- HttpPostRequestDecoder decoder = new HttpPostRequestDecoder(factory, request, Charsets.toCharset(CharEncoding.UTF_8));
- List<InterfaceHttpData> datas = decoder.getBodyHttpDatas();
- for (InterfaceHttpData data : datas) {
- if(data.getHttpDataType() == HttpDataType.FileUpload) {
- FileUpload fileUpload = (FileUpload) data;
- String fileName = fileUpload.getFilename();
- if(fileUpload.isCompleted()) {
- //保存到磁盘
- StringBuffer fileNameBuf = new StringBuffer();
- fileNameBuf.append(DiskFileUpload.baseDirectory).append(fileName);
- fileUpload.renameTo(new File(fileNameBuf.toString()));
- }
- }}
至于效果,你可以直接在本地起个服务搞个简单的页面,向服务器传个文件就行了。如果你很懒,直接用下面的HTML代码改改将就着用吧:
- <form action="http://localhost:8080" method="post" enctype ="multipart/form-data">
- <input id="File1" runat="server" name="UpLoadFile" type="file" />
- <input type="submit" name="Button" value="上传" id="Button" />
- </form>
至于其他类型的 Method、其他类型的 Content-Type,我也不打算细无巨细一一给大伙儿详细讲解了,看看上面罗列的,其实都很简单是不是?
上面说的都是 netty 自己实现的东西,下面就来讲讲如何实现一个简单的 HTTP decoder。
4. 自定义 HTTP POST 的 message body 解码器
关于解码器,我也不打算实现很复杂很牛逼的,只是写了两个粗糙的 decoder,一个是带参数的一个是不带参数的。既然是浅析,那就下面就简单的聊聊。
如果你要实现一个顶层解码器,就要继承 MessageToMessageDecoder 并重写其 decode 方法。MessageToMessageDecoder 继承了 ChannelHandlerAdapter,也就是说解码器其实就是一个 handler,只不过是专门用来做解码的事情。下面我们来看看它重写的 channelRead 方法:
- @Override
- public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
- RecyclableArrayList out = RecyclableArrayList.newInstance();
- try {
- if (acceptInboundMessage(msg)) {
- @SuppressWarnings("unchecked")
- I cast = (I) msg;
- try {
- decode(ctx, cast, out);
- } finally {
- ReferenceCountUtil.release(cast);
- }
- } else {
- out.add(msg);
- }
- } catch (DecoderException e) {
- throw e;
- } catch (Exception e) {
- throw new DecoderException(e);
- } finally {
- int size = out.size();
- for (int i = 0; i < size; i ++) {
- ctx.fireChannelRead(out.get(i));
- }
- out.recycle();
- }
- }
其中 decode 方法是你实现 decoder 时需要重写的,经过解码之后,会调用 ctx.fireChannelRead() 将 out 传递给给下一个 handler 执行相关逻辑。
4.1. HttpJsonDecoder
从名字可以看出,这是个针对 message body 为 JsonString 的解码器。处理过程很简单,只需要把 HTTP 请求的 content (即 ByteBuf)的可读字节转换成 JSONObject 对象,如下:
- @Override
- protected void decode(ChannelHandlerContext ctx, HttpRequest msg, List<Object> out) throws Exception {
- FullHttpRequest fullRequest = (FullHttpRequest) msg;
- ByteBuf content = fullRequest.content();
- int length = content.readableBytes();
- byte[] bytes = new byte[length];
- for(int i=0; i<length; i++){
- bytes[i] = content.getByte(i);
- }
- try{
- JSONObject obj = JSON.parseObject(new String(bytes));
- out.add(obj);
- }catch(ClassCastException e){
- throw new CodecException("HTTP message body is not a JSONObject");
- }
- }
使用方法也很简单,在 Server 的 HttpServerCodec() 和 HttpObjectAggregator() 后面加上:
- .addLast("jsonDecoder", new HttpJsonDecoder())
然后在业务 handler channelRead方法中使用即可:
- if(msg instanceof JSONObject){
- JSONObject obj = (JSONObject) msg;
- ......
- }
4.2. HttpProtobufDecoder
这是一个带参数的 decoder,用来解析使用 protobuf 序列化后的 message body。使用的时候需要传递 MessageLite 进来,直接上代码:
- private final MessageLite prototype;
- public HttpProtobufDecoder(MessageLite prototype){
- if (prototype == null) {
- throw new NullPointerException("prototype");
- }
- this.prototype = prototype.getDefaultInstanceForType();
- }
- @Override
- protected void decode(ChannelHandlerContext ctx, HttpRequest msg, List<Object> out) {
- FullHttpRequest fullRequest = (FullHttpRequest) msg;
- ByteBuf content = fullRequest.content();
- int length = content.readableBytes();
- byte[] bytes = new byte[length];
- for(int i=0; i<length; i++){
- bytes[i] = content.getByte(i);
- }
- try {
- out.add(prototype.getParserForType().parseFrom(bytes, 0, length));
- } catch (InvalidProtocolBufferException e) {
- throw new CodecException("HTTP message body is not " + prototype + "type");
- }
- }
使用方法跟 HttpJsonDecoder无异。此处以 protobuf 对象 UserProtobuf.User 为例,在 Server 的 HttpServerCodec() 和 HttpObjectAggregator() 后面加上:
- addLast("protobufDecoder", new HttpProtobufDecoder(UserProbuf.User.getDefaultInstance()))
然后在业务 handler channelRead方法中使用即可:
- if(msg instanceof UserProbuf.User){
- UserProbuf.User user = (UserProbuf.User) msg;
- ......
- }
5. 聊聊开发中遇到的问题【推荐】
如果你没有亲自使用过 netty 却说自己熟悉甚至精通 netty,我劝你千万别这么做,因为你的脸会被打肿的。netty 作为一个异步非阻塞的 IO 框架,它到底多牛逼在这就不多扯了,而作为一个首次使用 netty HTTP 协议栈的我来说,踩坑是必不可少的过程。当然了,踩了坑就要填上,我还很乐意在这把我踩过的几个坑给大家分享下,前车之鉴。
5.1. 关于内存泄漏
首先说下经历的情况。在文章开篇提到的接收服务,经过多轮的单元测试几乎没发现什么问题,于是对于接下来的压力测试我是自信满满。然而,当我第一次跑压测时就抛出一个异常,如下:
- [ERROR] 2016-07-24 15:25:46 [io.netty.util.internal.logging.Slf4JLogger:176] - LEAK: ByteBuf.release() was not called before it's garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced leak reporting, specify the JVM option '-Dio.netty.leakDetectionLevel=advanced' or call ResourceLeakDetector.setLevel() See http://netty.io/wiki/reference-counted-objects.html for more information.
着实让我开心了一把,终于出现异常了!异常信息表达的是 “ByteBuf 在被 JVM GC 之前没有调用 ByteBuf.release() ,启用高级泄漏报告,找出发生泄漏的地方”,于是马上google了一把,原来是从 netty4 开始,对象的生命周期由它们的引用计数(reference counts)管理,而不是由垃圾收集器(garbage collector)管理了。
要解决这个问题,先从源头了解开始。
5.1.1. netty 引用计数对象【2】
对于 netty Inbound message,当 event loop 读入了数据并创建了 ByteBuf,并用这个 ByteBuf 触发了一个 channelRead() 事件时,那么管道(pipeline)中相应的ChannelHandler 就负责释放这个 buffer 。因此,处理接数据的 handler 应该在它的 channelRead() 中调用 buffer 的 release(),如下:
- public void channelRead(ChannelHandlerContext ctx, Object msg) {
- ByteBuf buf = (ByteBuf) msg;
- try {
- ...
- } finally {
- buf.release();
- }
- }
而有时候,ByteBuf 会被一个 buffer holder 持有,它们都扩展了一个公共接口 ByteBufHolder。正因如此, ByteBuf 并不是 netty 中唯一一种引用计数对象。由 decoder 生成的消息对象很可能也是引用计数对象,比如 HTTP 协议栈中的 HttpContent,因为它也扩展了 ByteBufHolder。
- public void channelRead(ChannelHandlerContext ctx, Object msg) {
- if (msg instanceof HttpRequest) {
- HttpRequest req = (HttpRequest) msg;
- ...
- }
- if (msg instanceof HttpContent) {
- HttpContent content = (HttpContent) msg;
- try {
- ...
- } finally {
- content.release();
- }
- }
- }
如果你抱有疑问,或者你想简化这些释放消息的工作,你可以使用 ReferenceCountUtil.release():
- public void channelRead(ChannelHandlerContext ctx, Object msg) {
- try {
- ...
- } finally {
- ReferenceCountUtil.release(msg);
- }
- }
或者可以考虑继承 SimpleChannelHandler,它在所有接收消息的地方都调用了 ReferenceCountUtil.release(msg)。
对于 netty Outbound message,你的程序所创建的消息对象都由 netty 负责释放,释放的时机是在这些消息被发送到网络之后。但是,在发送消息的过程中,如果有 handler 截获(intercept)了你的发送请求并创建了一些中间对象,则这些 handler 要确保正确释放这些中间对象。比如 encoder,此处不赘述。
通过以上信息,自然就很容易找到 OOM 问题的原因所在了。由于在处理 HTTP 请求过程中没有释放 ByteBuf,因此在代码 finally 块中加上 ReferenceCountUtil.release(msg) 就解决啦!
5.1.2. 如何规避内存泄漏【3】
netty 提供了内存泄漏的监测机制,默认就会从分配的 ByteBuf 里抽样出大约 1% 的来进行跟踪。如果泄漏,就会打印5.1.1节中的异常信息,并提示你通过指定 JVM 选项
- -Dio.netty.leakDetectionLevel=advanced
来查看泄漏报告。泄漏年监测有4个等级:
- 禁用(DISABLED) - 完全禁止泄露检测,省点消耗。
- 简单(SIMPLE) - 默认等级,告诉我们取样的 1% 的 ByteBuf 是否发生了泄露,但总共一次只打印一次,看不到就没有了。
- 高级(ADVANCED) - 告诉我们取样的 1% 的 ByteBuf 发生泄露的地方。每种类型的泄漏(创建的地方与访问路径一致)只打印一次。
- 偏执(PARANOID) - 跟高级选项类似,但此选项检测所有 ByteBuf,而不仅仅是取样的那 1%。在高压力测试时,对性能有明显影响。
一般情况下我们采用 SIMPLE 级别即可。
5.2. 关于 HTTP 长连接
按照惯例,先说下开发中踩到的坑。
对于接收服务,我采用的是 nginx + netty http,其中 nginx 配置如下(阉割隐藏版):
- upstream xxx.com{
- keepalive 32;
- server xxxx.xx.xx.xx:8080;
- }
- server{
- listen 80;
- server_name xxx.com;
- location / {
- proxy_next_upstream http_502 http_504 error timeout invalid_header;
- proxy_pass xxx.com;
- proxy_http_version 1.1;
- proxy_set_header Connection "";
- #proxy_set_header Host $host;
- #proxy_set_header X-Forwarded-For $remote_addr;
- #proxy_set_header REMOTE_ADDR $remote_addr;
- #proxy_set_header X-Real-IP $remote_addr;
- proxy_read_timeout 60s;
- client_max_body_size 1m;
- }
- error_page 500 502 503 504 /50x.html;
- location = /50x.html{
- root html;
- }
- }
然后编写了一个简单的 HttpClient 发送消息,如下(截取):
- OutputStream outStream = conn.getOutputStream();
- outStream.write(data);
- outStream.flush();
- outStream.close();
- if (conn.getResponseCode() == 200) {
- <span style="color: #ff0000;">BufferedReader in = new BufferedReader(new InputStreamReader((InputStream) conn.getInputStream(), "UTF-8"));</span>
- String msg = in.readLine();
- System.out.println("msg = " + msg);
- in.close();
- }
- conn.disconnect();
接着,正常发送 HTTP 请求到服务器,然而,老夫整整等了60多秒才接到响应信息!而且每次都这样!!
我首先怀疑是不是 ngxin 出问题了,有一个配置项立马引起了我的怀疑,没错,就是上面红色的那行 proxy_read_timeout 60s; 。为了验证,我首先把 60s 改成了 10s,效果很明显,发送的请求 10 秒过一点就收到响应了!更加彻底证明是 nginx 的锅,我去掉了 nginx,让客户端直接发送请求给服务端。然而,蛋疼的事情出现了,客户端竟然一直阻塞在 BufferedReader in = new BufferedReader(new InputStreamReader((InputStream) conn.getInputStream(), "UTF-8")); 处。这说明根本就不是 nginx 的问题啊!
我冷静下来,review 了一下代码同时 search 了相关资料,发现了一个小小的区别,在我的返回代码中,对 ChannelFuture 少了对 CLOSE 事件的监听器:
- ctx.writeAndFlush(response).addListener(ChannelFutureListener.CLOSE);
于是,我加上 Listener 再试一下,马上就得到响应了!
就在这一刻明白了这是 HTTP 长连接的问题。首先从上面的 nginx 配置中可以看到,我显式指定了 nginx 和 HTTP 服务器是用的 HTTP1.1 版本,HTTP1.1 版本默认是长连接方式(也就是 Connection=Keep-Alive),而我在 netty HTTP 服务器中并没有对长、短连接方式做区别处理,并且在 HttpResponse 响应中并没有显式加上 Content-Length 头部信息,恰巧 netty Http 协议栈并没有在框架上做这件工作,导致服务端虽然把响应消息发出去了,但是客户端并不知道你是否发送完成了(即没办法判断数据是否已经发送完)。
于是,把响应的处理完善一下即可:
- /**
- * 响应报文处理
- * @param channel 当前上下文Channel
- * @param status 响应码
- * @param msg 响应消息
- * @param forceClose 是否强制关闭
- */
- private void writeResponse(Channel channel, HttpResponseStatus status, String msg, boolean forceClose){
- ByteBuf byteBuf = Unpooled.wrappedBuffer(msg.getBytes());
- response = new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, status, byteBuf);
- boolean close = isClose();
- if(!close && !forceClose){
- response.headers().add(org.apache.http.HttpHeaders.CONTENT_LENGTH, String.valueOf(byteBuf.readableBytes()));
- }
- ChannelFuture future = channel.write(response);
- if(close || forceClose){
- future.addListener(ChannelFutureListener.CLOSE);
- }
- }
- private boolean isClose(){
- if(request.headers().contains(org.apache.http.HttpHeaders.CONNECTION, CONNECTION_CLOSE, true) ||
- (request.protocolVersion().equals(HttpVersion.HTTP_1_0) &&
- !request.headers().contains(org.apache.http.HttpHeaders.CONNECTION, CONNECTION_KEEP_ALIVE, true)))
- return true;
- return false;
- }
好了,问题是解决了,那么你对 HTTP 长连接真的了解吗?不了解,好,那就来不补课。
5.2.1. TCP KeepAlive 和 HTTP KeepAlive【4】
netty 中有个地方比较让初学者迷惑,就是 childOption(ChannelOption.SO_KEEPALIVE, true)和 HttpRequest.Headers.get("Connection").equals("Keep-Alive") (非标准写法,仅作示例)的异同。有些人可能会问,我在 ServerBootstrap 中指定了 childOption(ChannelOption.SO_KEEPALIVE, true),是不是就意味着客户端和服务器是长连接了?
答案当然不是。
首先,TCP 的 KeepAlive 是 TCP 连接的探测机制,用来检测当前 TCP 连接是否活着。它支持三个系统内核参数
- tcp_keepalive_time
- tcp_keepalive_intvl
- tcp_keepalive_probes
当网络两端建立了 TCP 连接之后,闲置 idle(双方没有任何数据流发送往来)了 tcp_keepalive_time 后,服务器内核就会尝试向客户端发送侦测包,来判断 TCP 连接状况(有可能客户端崩溃、强制关闭了应用、主机不可达等等)。如果没有收到对方的回答( ACK 包),则会在 tcp_keepalive_intvl 后再次尝试发送侦测包,直到收到对对方的 ACK,如果一直没有收到对方的 ACK,一共会尝试 tcp_keepalive_probes 次,每次的间隔时间在这里分别是 15s、30s、45s、60s、75s。如果尝试 tcp_keepalive_probes,依然没有收到对方的 ACK 包,则会丢弃该 TCP 连接。TCP 连接默认闲置时间是2小时。
而对于 HTTP 的 KeepAlive,则是让 TCP 连接活长一点,在一次 TCP 连接中可以持续发送多份数据而不会断开连接。通过使用 keep-alive 机制,可以减少 TCP 连接建立次数,也意味着可以减少 TIME_WAIT 状态连接,以此提高性能和提高 TTTP 服务器的吞吐率(更少的 TCP 连接意味着更少的系统内核调用,socket 的 accept() 和 close() 调用)。
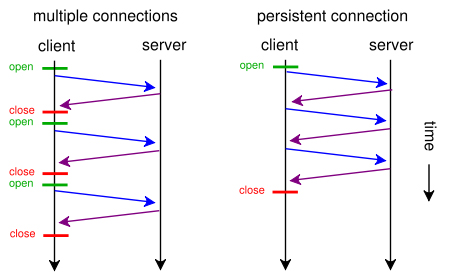
对于建立 HTTP 长连接的好处,总结如下【5】:
By opening and closing fewer TCP connections, CPU time is saved in routers and hosts (clients, servers, proxies, gateways, tunnels, or caches), and memory used for TCP protocol control blocks can be saved in hosts.
HTTP requests and responses can be pipelined on a connection. Pipelining allows a client to make multiple requests without waiting for each response, allowing a single TCP connection to be used much more efficiently, with much lower elapsed time.
Network congestion is reduced by reducing the number of packets caused by TCP opens, and by allowing TCP sufficient time to determine the congestion state of the network.
Latency on subsequent requests is reduced since there is no time spent in TCP's connection opening handshake.
HTTP can evolve more gracefully, since errors can be reported without the penalty of closing the TCP connection. Clients using future versions of HTTP might optimistically try a new feature, but if communicating with an older server, retry with old semantics after an error is reported.
5.2.2. 长连接方式中如何判断数据发送完成【6】
回到本节最开始提出的问题,KeepAlive 模式下,HTTP 服务器在发送完数据后并不会主动断开连接,那客户端如何判断数据发送完成了?
对于短连接方式,服务端在发送完数据后会断开连接,客户端过服务器关闭连接能确定消息的传输长度。(请求端不能通过关闭连接来指明请求消息体的结束,因为这样让服务器没有机会继续给予响应)。
但对于长连接方式,服务端只有在 Keep-alive timeout 或者达到 max 请求次数时才会断开连接。这种情况下有两种判断方法。
使用消息头部 Content-Length
Conent-Length 表示实体内容长度,客户端(或服务器)可以根据这个值来判断数据是否接收完成。但是如果消息中没有 Conent-Length,那该如何来判断呢?又在什么情况下会没有 Conent-Length 呢?
使用消息首部字段 Transfer-Encoding
当请求或响应的内容是动态的,客户端或服务器无法预先知道要传输的数据大小时,就要使用 Transfer-Encoding(即 chunked 编码传输)。chunked 编码将数据分成一块一块的发送。chunked 编码将使用若干个chunk 串连而成,由一个标明长度为 0 的 chunk 标示结束。每个 chunk 分为头部和正文两部分,头部内容指定正文的字符总数(十六进制的数字)和数量单位(一般不写),正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为 0 的 chunk 中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。
如果一个请求包含一个消息主体并且没有给出 Content-Length,那么服务器如果不能判断消息长度的话应该以400响应(Bad Request),或者以411响应(Length Required)如果它坚持想要收到一个有效的 Content-length。所有的能接收实体的 HTTP/1.1 应用程序必须能接受 chunked 的传输编码,因此当消息的长度不能被提前确定时,可以利用这种机制来处理消息。消息不能同时都包括 Content-Length 头域和 非identity (Transfer-Encoding)传输编码。如果消息包括了一个 非identity 的传输编码,Content-Length头域必须被忽略。当 Content-Length 头域出现在一个具有消息主体(message-body)的消息里,它的域值必须精确匹配消息主体里字节数量。
好了,本章较长,虽然不是很深奥难懂的知识,也不是很牛逼的技术实现,但是耐心看完之后相信你终究是有所收获的。在此本文就要完结了,后续会对 netty HTTP 协议栈做更深入的研究,至于这个 github 上的项目,后面也会继续完善 TODO LIST。大家可以通过多种方式与我交流,并欢迎大家提出宝贵意见。