做技术的朋友可能有过类似这样的感觉——每天都会遇到新的问题,或者学到新的知识。然而一个人的时间和精力毕竟有限,不是所有的岗位都能做到总是亲力亲为,每人最擅长的领域也各不相同。为了使工程师自己踩过的坑、那些实用的心得体会也能给大家带来帮助,把经验记录和分享出来就显得尤为可贵,这就是我们开设《工程师笔记》专栏的目的。

在《从260核异构申威看HPC Top500缩影》一文中,我给大家介绍过在最新的超算榜单上为国争光的“神威太湖之光”。而在同一次大会上,Intel也正式发布了代号为Knights Landing的新一代Xeon Phi Processor x200(注意:不再是coprocessor/协处理器了)。


这个照片应该是Intel的参考平台,尺寸上大致符合2U 4节点的密度,在Xeon Phi Processor两侧有6个DDR4内存插槽。用红圈标出的部分应该就是将Omni-Path网络引出机箱的连接器件。
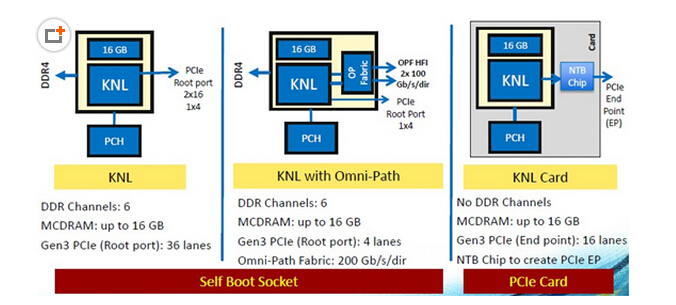
至本文截稿之时,官网上我还没找到关于Xeon Phi x200的详细资料,不过早在去年底翻译自国外的新闻中已经有过不错的介绍。
如上图,“Self Boot Socket”的Knights Landing除了DDR4内存控制器之外,还可以提供36个PCIe Gen3 lane,感觉是移植了Xeon CPU的uncore部分设计。不过,提供2个Omni-Path 100Gb/s网口的型号就少了2个PCIe x16,让我觉得这一代产品的片上OPA互连控制器走的还是PCIe?最右边的PCIe插卡形态,去掉了DDR内存通道,能不能不要那个PCH南桥呢?
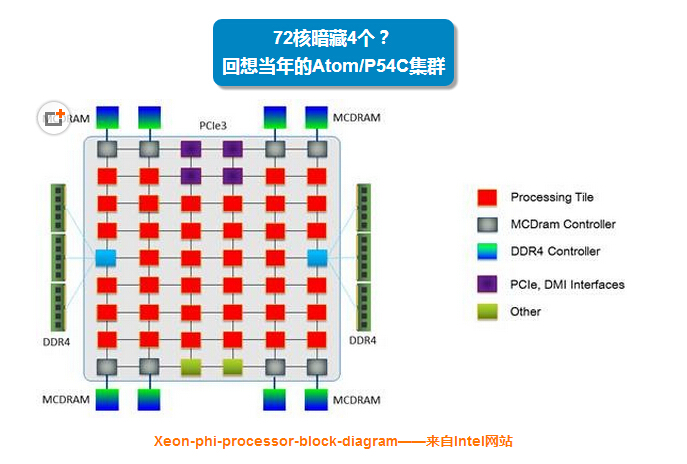
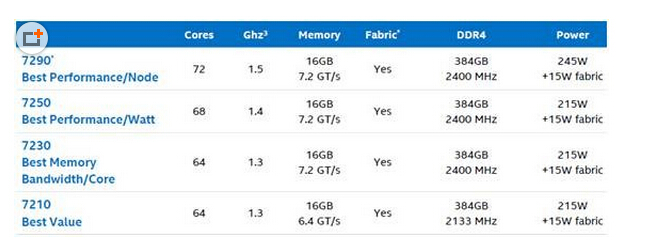
上下两张图可以结合起来看。我数了一下红色Processing Tile的数量是38个,如此则该架构设计应该支持最多76个核心,目前限制在72个可能是为了保证良品率,或者功耗考虑?
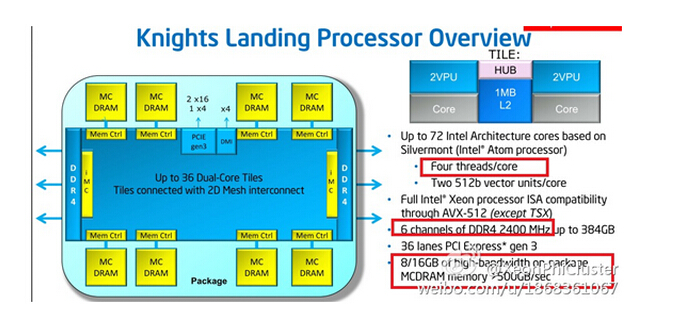
根据右边的解释,每个“tile”中有2个Core共享1MB L2 Cache,每个Core支持4线程并包含2个AVX-512矢量单元(浮点计算应该就是靠它来进行的)。Intel还提到了这些Core是基于Atom处理器内核,记得之前还有一种说法是P54C。P54C即当年Intel Pentium 75-166的核心代号,1997年我自己的第一台电脑用的就是奔腾133。

在2011年春季北京IDF上,我曾经看到这套由微服务器厂商SeaMicro打造的高密度系统,展板上介绍在10U机箱内容纳了256个双核Atom,当时负责展台的朋友也提到了P54C。不知大家有没有觉得神威太湖之光的节点布局有点像这个?

我猜测这个系统很早就开始用于预研今天的Xeon Phi Processor,当然此时它还谈不上芯片集成度和成本效益。从照片中看每颗Atom旁边应该都有一颗南桥(当时还不是SoC),内存等可能在PCB背面,4颗印着SeaMicro的芯片估计是用于互连。
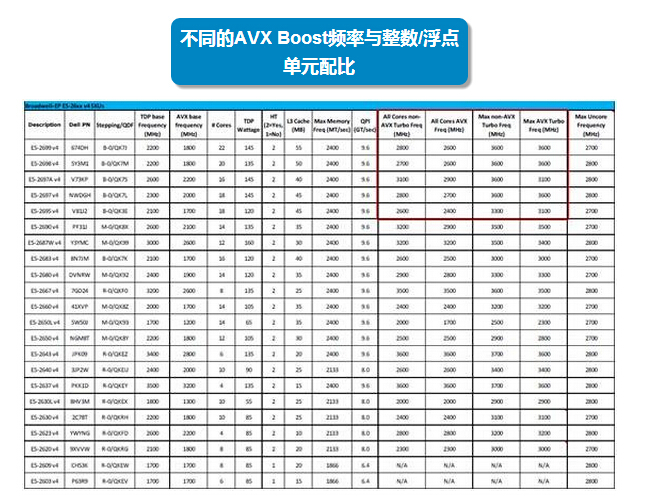
撰写上一篇《工程师笔记:一项Xeon E5-2600 v4测试数据的背后》的过程中,在Dell的Solutions Performance Analysis文档中我看到了以上规格表,其中有non-AVX和AVX单元不同的TurboBoost超频频率。让我们放大来看一下:
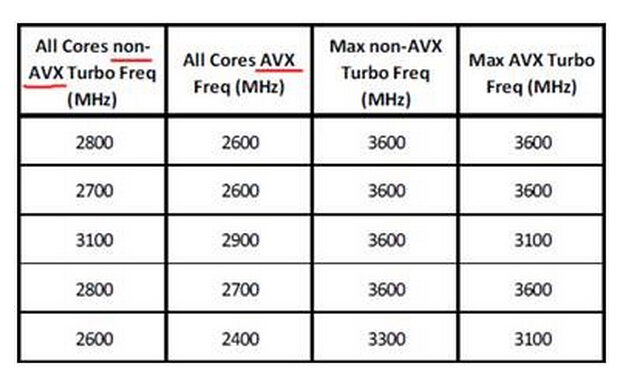
对于所有核心一起工作时的TurboBoost,non-AVX的频率比AVX要高,而最大(少数核心工作)TurboBoost频率有些型号的CPU也存在差别。
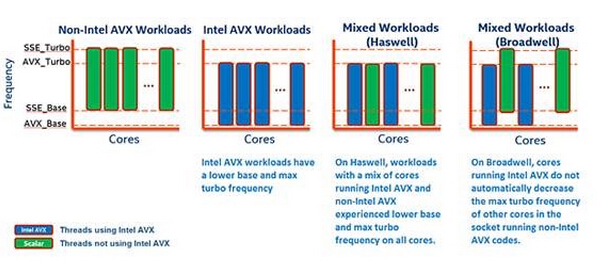
上图来自Intel资料,描述了Xeon E5v4(Broadwell)的一点改进。在此之前如果AVX和non-AVX负载在不同Core上混合运行,只能统一跑在两者中较低的TurboBoost频率上。而在Xeon E5v4上,则运行AVX的Core频率不会降低到其它Core的TurboBoost水平。
我有个理解不知是否准确:由于用途的原因,整数/浮点单元的设计偏重与配比是Xeon Phi Processor与Xeon CPU的重要区别。至于Intel为什么没有进一步像申威26010那样“将MPE(管理单元)减少到4个来搭配256个CPE(计算单元)”?我觉得是考虑到通用性,毕竟Xeon Phi仍属于x86指令集的一个扩展。
目前正式发布支持Xeon Phi Processor x200服务器产品的公司还不多,其中包括SuperMicro的主板和准系统(就是加个塔式机箱),或许只是先出个通用平台还没有太多特点。
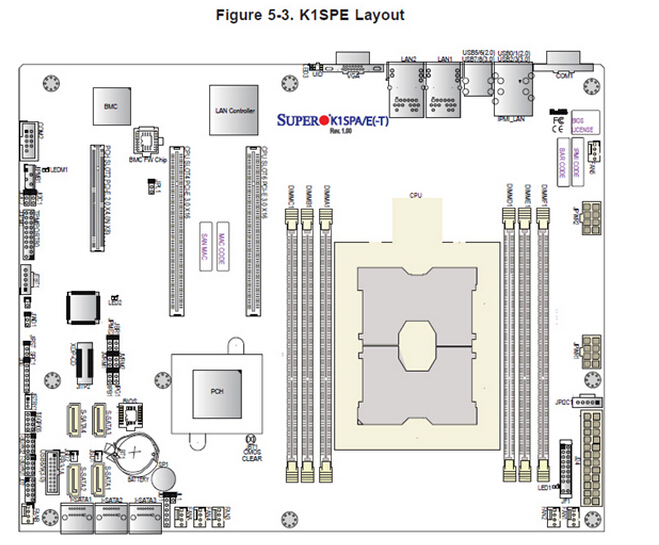
SuperMicro K1SPA/E (-T) 主板示意图,可以看到“巨大”的LGA-3647 CPU插座,据了解下一代Xeon E5可能也会用这个Socket。
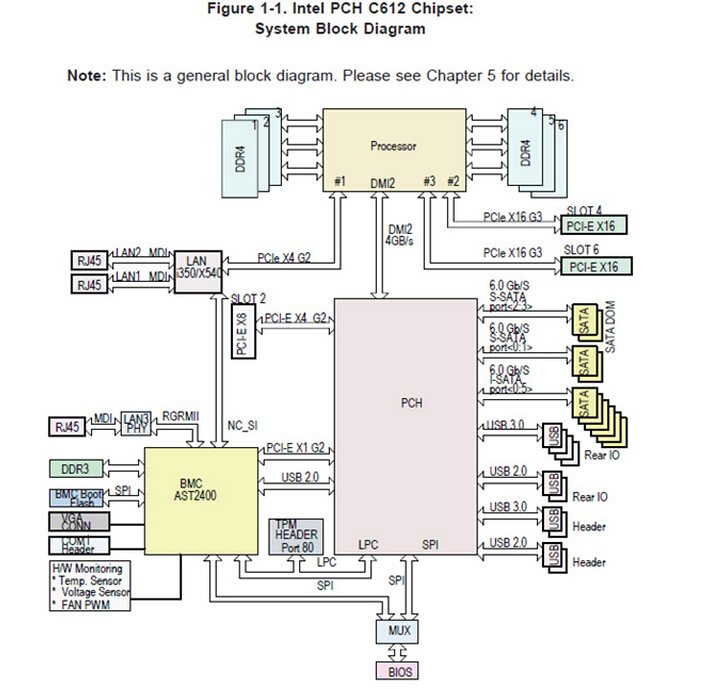
上面是SuperMicro这款主板的结构图。涉及PCH 612的部分与传统Xeon服务器并没有明显的不同;除了内存通道之外,从处理器引出的PCIe x16 Gen3插槽也许不再支持拆分成x8或者x4,因为Xeon Phi的定位就是HPC,除了高速网络互连应该啥也不缺了。

戴尔的这款PowerEdge C6320p,可以理解为是在2U 4节点机箱基础上将C6320 Xeon E5计算节点换成了Xeon Phi Processor节点。它比较接近前面我们列出的Intel参考平台,具备计算密度并适合大规模部署。
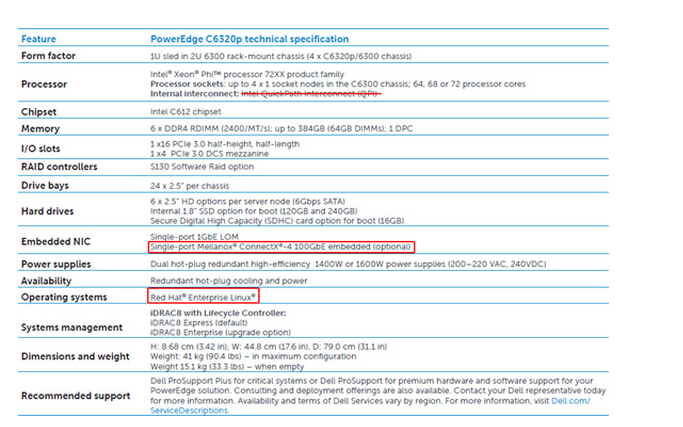
可能是由于初版资料,规格表中Xeon Phi Processor 72XX不支持的QPI还没来得及修改彻底。C6320p有几种硬盘/闪存支持选项,提供戴尔统一的iDRAC8服务器管理,听说可以直接安装Red Hat企业版Linux,具体注意事项有待后续确认。不过为了发挥AVX-512计算单元的能力,还是需要运行相应的编译好的程序。
关于集成单端口Mellanox ConnectX-4 100GbE网卡这个可选项,为什么不是InfiniBand EDR呢?其实该公司近几年对以太网的支持也不错,可以在同样的硬件上实现两种网络支持,比如EoIB这样的方式。

上图来自戴尔网站,可见这个100Gb网口应该是支持IB的。据了解PowerEdge C6320p也做好了支持Omni-Path的准备,除了现在可以使用Intel Omni-Path Host Fabric Adapter 100 Series PCIe网卡之外,等今年四季度Xeon Phi Processor 72xxF推出之后,像Intel参考平台中那样将Omni-Path引出机箱的连接器件也可以使用。
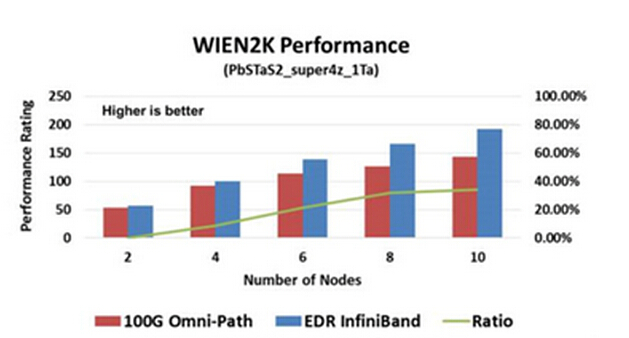
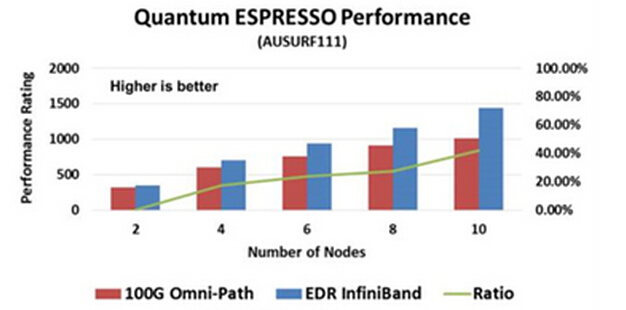
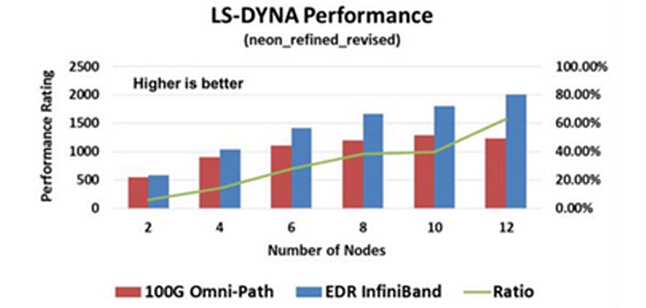
以上图表仅供参考,因为在Intel的宣传资料中您很可能会看到另外一些不同的测试数字。
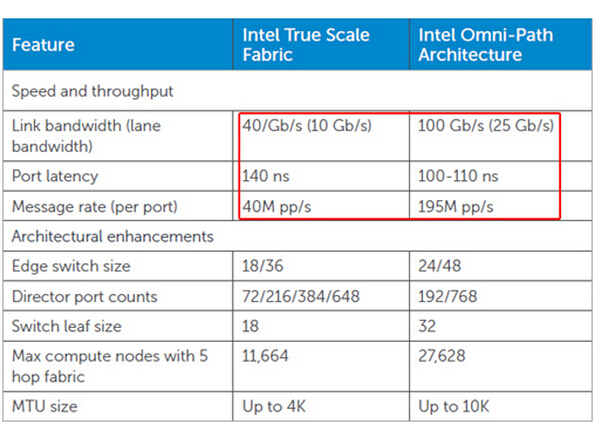
True Scale就是当初QLogic的40Gb/s InfiniBand产品线,可以看出100Gb/s的Intel Omni-Path在端口延时、发包速率上的优势。既然是在IB技术上发展而来,Omni-Path可能需要一个成熟的过程,但我不认为有太大的困难。
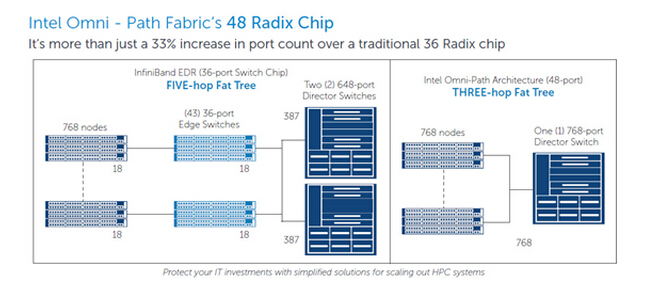
Intel还列出了交换机方面的一些优势。比如Edge(边缘)交换机48口比IB的36口多,服务器节点可以不通过边缘交换机直连Director(导向器)等。
关于HPC网络方面的最终战局,我觉得要看Intel Omni-Path怎么个卖法。如果未来某一代CPU/Xeon Phi Processor无论你用不用全都集成的话……